







虽然是个菜鸟,但是决定好好研究一下机器学习算法,初步决定 一周学习两种算法,希望我能坚持下来!此过程中难免出错,望各位前辈指出探讨!同时文章可能借鉴其他博客书籍等资料,请海涵!
第一篇选择贝叶斯分类,因为它是比较基础的一种机器学习算法。今天介绍简单理论和R的简单实现。
朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法。算法的基础是概率问题,分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类。
朴素贝叶斯两个假设:①特征间独立 (各个特征出现与否与其他特征无关)
② 每个特征同等重要
但朴素贝叶斯算法简单,快速,具有较小的出错率。
假设有数据D,我们由一组数据D导出一个参数化模型M=M(ω).
计算方法:
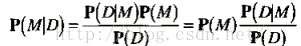
P(M): 先验概率
P(M|D) 后验概率
则 问题转化为 已知数据D求模型M的概率为后验概率。
贝叶斯推断方法:比较两个特定模型的后验概率P(M1|D)和P(M1|D)来比较这两个模型。后验概率值越大,相应的误差越小。(MAP估计,最大后验概率估计) 常用的先验分布:高斯分布,伽马分布和Dirichlet分布
若假定所有参数具有均匀的先验分布(P(M)),求较大P(M|D)问题(MAP最大后验概率估计)即转化为求最大P(D|M)问题(ML最大似然估计)。
为了便于比较,通常取对数进行计算。
【参考文献1】贝叶斯分类 主要 对于输入特征x,利用通过学习得到的模型计算后验概率分布,将后验概率最大的分类作为输出。
根据贝叶斯定理,后验概率P(Y=cx | X=x) = 条件概率P(X=x | Y=cx) * 先验概率P(Y = ck) / P(X=x),取P(X=x | Y=cx) * P(Y = ck)最大的分类作为输出。
R简单贝叶斯分类R简单贝叶斯分类
[plain] view plaincopy #构造训练集 data <- matrix(c("sunny","hot","high","weak","no", "sunny","hot","high","strong","no", "overcast","hot","high","weak","yes", "rain","mild","high","weak","yes", "rain","cool","normal","weak","yes", "rain","cool","normal","strong","no", "overcast","cool","normal","strong","yes", "sunny","mild","high","weak","no", "sunny","cool","normal","weak","yes", "rain","mild","normal","weak","yes", "sunny","mild","normal","strong","yes", "overcast","mild","high","strong","yes", "overcast","hot","normal","weak","yes", "rain","mild","high","strong","no"), byrow = TRUE, dimnames = list(day = c(), condition = c("outlook","temperature", "humidity","wind","playtennis")), nrow=14, ncol=5); #计算先验概率 prior.yes = sum(data[,5] == "yes") / length(data[,5]); prior.no = sum(data[,5] == "no") / length(data[,5]); #模型 naive.bayes.prediction <- function(condition.vec) { # Calculate unnormlized posterior probability for playtennis = yes. playtennis.yes <- sum((data[,1] == condition.vec[1]) & (data[,5] == "yes")) / sum(data[,5] == "yes") * # P(outlook = f_1 | playtennis = yes) sum((data[,2] == condition.vec[2]) & (data[,5] == "yes")) / sum(data[,5] == "yes") * # P(temperature = f_2 | playtennis = yes) sum((data[,3] == condition.vec[3]) & (data[,5] == "yes")) / sum(data[,5] == "yes") * # P(humidity = f_3 | playtennis = yes) sum((data[,4] == condition.vec[4]) & (data[,5] == "yes")) / sum(data[,5] == "yes") * # P(wind = f_4 | playtennis = yes) prior.yes; # P(playtennis = yes) # Calculate unnormlized posterior probability for playtennis = no. playtennis.no <- sum((data[,1] == condition.vec[1]) & (data[,5] == "no")) / sum(data[,5] == "no") * # P(outlook = f_1 | playtennis = no) sum((data[,2] == condition.vec[2]) & (data[,5] == "no")) / sum(data[,5] == "no") * # P(temperature = f_2 | playtennis = no) sum((data[,3] == condition.vec[3]) & (data[,5] == "no")) / sum(data[,5] == "no") * # P(humidity = f_3 | playtennis = no) sum((data[,4] == condition.vec[4]) & (data[,5] == "no")) / sum(data[,5] == "no") * # P(wind = f_4 | playtennis = no) prior.no; # P(playtennis = no) return(list(post.pr.yes = playtennis.yes, post.pr.no = playtennis.no, prediction = ifelse(playtennis.yes >= playtennis.no, "yes", "no"))); } #预测 naive.bayes.prediction(c("rain", "hot", "high", "strong")); naive.bayes.prediction(c("sunny", "mild", "normal", "weak")); naive.bayes.prediction(c("overcast", "mild", "normal", "weak"));
最后一个分类预测结果如下:
$post.pr.yes [1] 0.05643739 $post.pr.no [1] 0 $prediction [1] "yes"
参考网址:
1、http://blog.csdn.net/yucan1001/article/details/23033931
2、机器学习实战 Peter Harrington著
下节将会介绍贝叶斯在文本分类应用的实例。
















 5407
5407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











