







Paper name
InternLM-XComposer: A Vision-Language Large Model for Advanced Text-image Comprehension and Composition
Paper Reading Note
Paper URL: https://arxiv.org/pdf/2309.15112.pdf
Code URL: https://github.com/InternLM/InternLM-XComposer
TL;DR
- 2023 年上海人工智能实验室文章,提出了视觉语言大模型 InternLM-XComposer,具有高级的文本图像理解和组合能力。文章详细介绍了图像文本交织数据的构造方式,同时开源了 7b 的预训练和指令微调模型
Introduction
背景
- 在过去的一年里,大型语言模型(LLMs)进展很大。包括 ChatGPT、GPT4 和 PaLM 2,展示出了前所未有的能力,能够遵循人类的指令并解决开放性任务。
- 受到 PaLM-E 和 BLIP2 的成功启发,通过将视觉特征作为 LLMs 的额外输入来扩展语言模型以执行视觉-语言任务是一种有前途的方法。社区已经开发了几个视觉-语言大型模型(VLLMs),如 MiniGPT-4、LLaVA 和 InstructBLIP,基于开源 LLMs,如 LLaMA 、GLM 和 InternLM。
- 然而,这些 VLLMs 侧重于纯文本输出,从而无法为生成的文本附加更丰富的多媒体信息(比如图像)
本文方案
- 提出了视觉语言大模型 InternLM-XComposer,具有高级的文本图像理解和组合能力
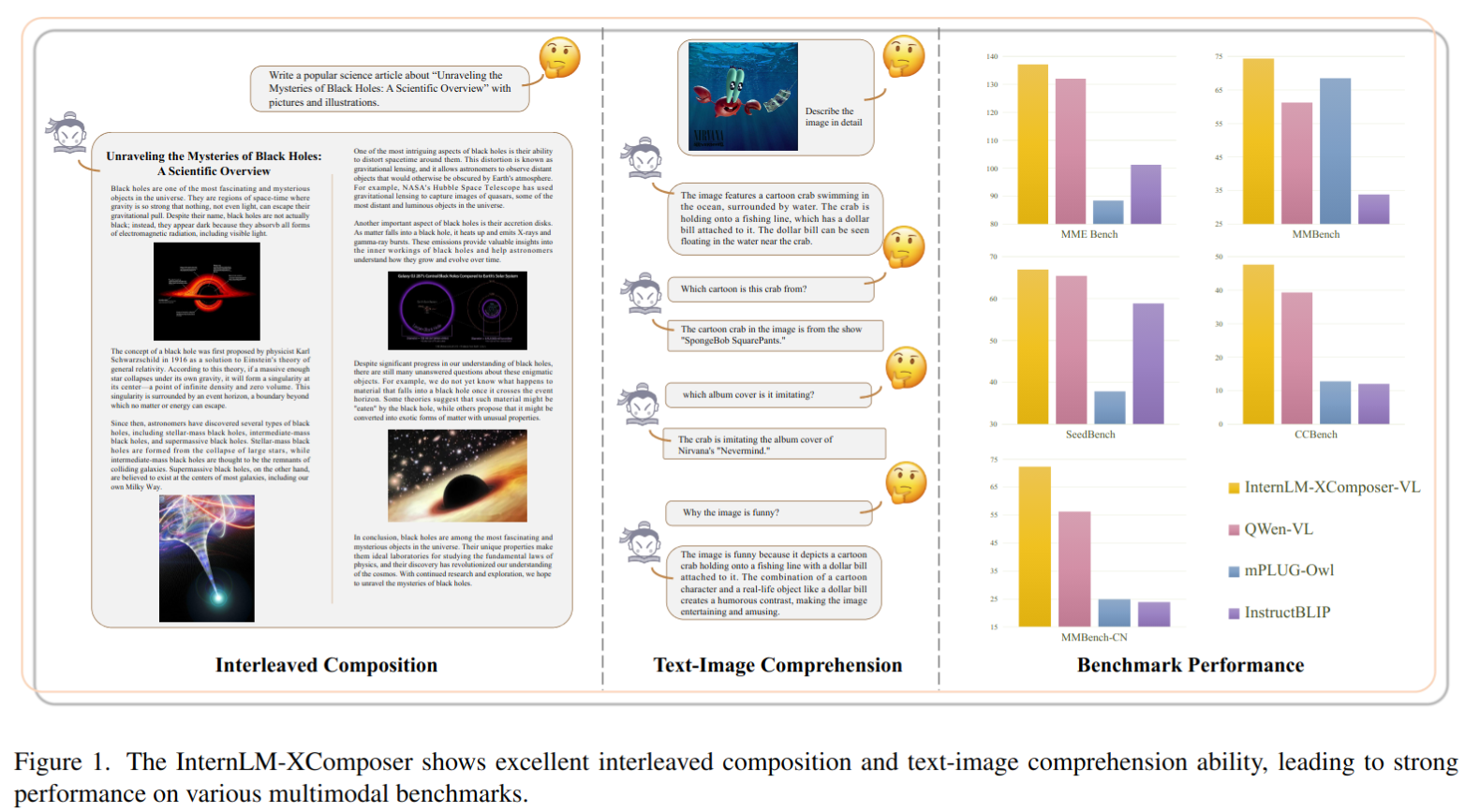
- 交错式文本-图像组合:InternLM-XComposer 擅长生成与上下文相关图像交错的长篇内容,从而提升了视觉-语言交互的体验。
- 首先根据人工提供的指令创建文本
- 随后,它自动确定文本中最适合放置图像的位置,并提供相应的合适的图像描述。根据生成的描述,与依赖于文本-图像生成模型来帮助的方法不同,我们选择从大规模网络爬取的图像数据库中获取对齐的图像,以实现更真实的质量和上下文对齐。此外,它还提供了灵活性,允许用户自定义图像库。
- 与仅依赖于 CLIP 进行图像检索的基线方法相比,XComposer 提供了更可靠的选择最合适图像的解决方案。首先,使用 CLIP 从数据库中选择潜在的图像候选项。然后,InternLM-XComposer 利用其理解能力来识别最适合内容的图像
- 具有丰富多语言知识的理解。LLM 在处理开放世界任务方面表现出了出色的通用性,这一能力归因于其广泛的训练数据,例如 LLaMA2 中使用的 2T token 训练。这一庞大数据集囊括了多个领域的广泛语义知识。相比之下,现有的视觉-语言数据集在容量和多样性方面相对受限。为了解决这些限制,我们采用了两种实际解决方案:
- 首先,从公共网站收集了一个包含超过 1100 万个语义概念的交错多语言视觉-语言数据集
- 其次,在训练流程中精心制定了预训练和微调策略,采用了主要是英文和中文的纯文本和图像-文本混合训练数据。因此,InternLM-XComposer 在理解各种图像内容和提供广泛的多语知识方面表现出了出色的能力。
- 交错式文本-图像组合:InternLM-XComposer 擅长生成与上下文相关图像交错的长篇内容,从而提升了视觉-语言交互的体验。
- 所提出的 InternLM-XComposer 在文本-图像理解和组合方面表现出卓越的能力。它在各种领先的视觉-语言大型模型的基准测试中取得 SOTA 的成绩,包括英文的 MME 基准测试、MMBench、Seed-Bench 以及中文的 MMBench-CN 和 CCBench(中国文化基准测试)的评估。值得注意的是,我们的方法在中文语言的基准测试中,即MMBench-CN 和 CCBench 上显著优于现有框架,展示出卓越的多语知识能力。
- 发布 InternLM-XComposer 系列的两个版本:
- InternLM-XComposer-VL:这是基于 InternLM 作为初始 LLM 的预训练和多任务训练的 VLLM 模型
- InternLM-XComposer:这是基于 InternLM-XComposer-VL 进行了进一步指令微调的 VLLM,用于交错式文本-图像组合和基于 LLM 的人工智能助手。
Methods
模型架构
- 模型由三个组件构成
- 视觉编码器:EVA-CLIP (CLIP的一个改进变种,通过掩码图像建模能力增强,以有效捕捉输入图像的视觉细微差异)。输入 224x224,以 stride 14 分为小 patch 后输入 transformer
- 感知采样器(Perceive Sampler):InternLM-XComposer 中的感知采样器作为一种专注的池化机制,旨在将初始的 257个 图像嵌入压缩为 64 个经过优化的嵌入。这些优化的嵌入随后会与大型语言模型理解的知识结构相匹配。与 BLIP2 类似,使用带有交叉注意力层的 BERTbase 作为感知采样器。
- LLM:InternLM-XComposer 以 InternLM 作为其基础的大型语言模型。值得注意的是,InternLM 是一款强大的语言模型,具备多语言能力,在英语和中文方面表现出色。使用公开可用的 InternLM-Chat-7B 作为大型语言模型。
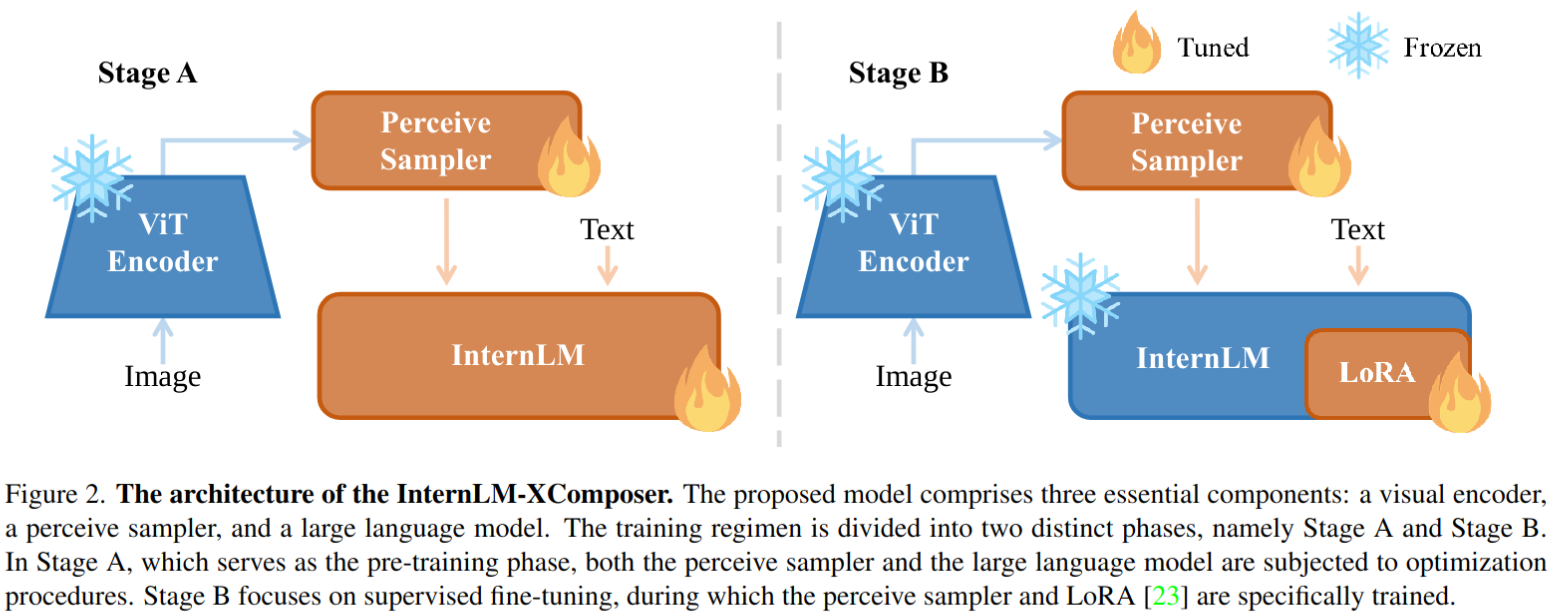
训练流程
- 如上图所示,InternLMXComposer 的训练过程分为 A 阶段和 B 阶段。
- A 阶段是预训练阶段,利用大量数据进行基础模型的训练
- B阶段是监督微调阶段,包括多任务训练步骤和随后的指令微调步骤
- 模型在多任务训练后被命名为InternLM-XComposer-VL,指令微调后被命名为InternLM-XComposer。
预训练
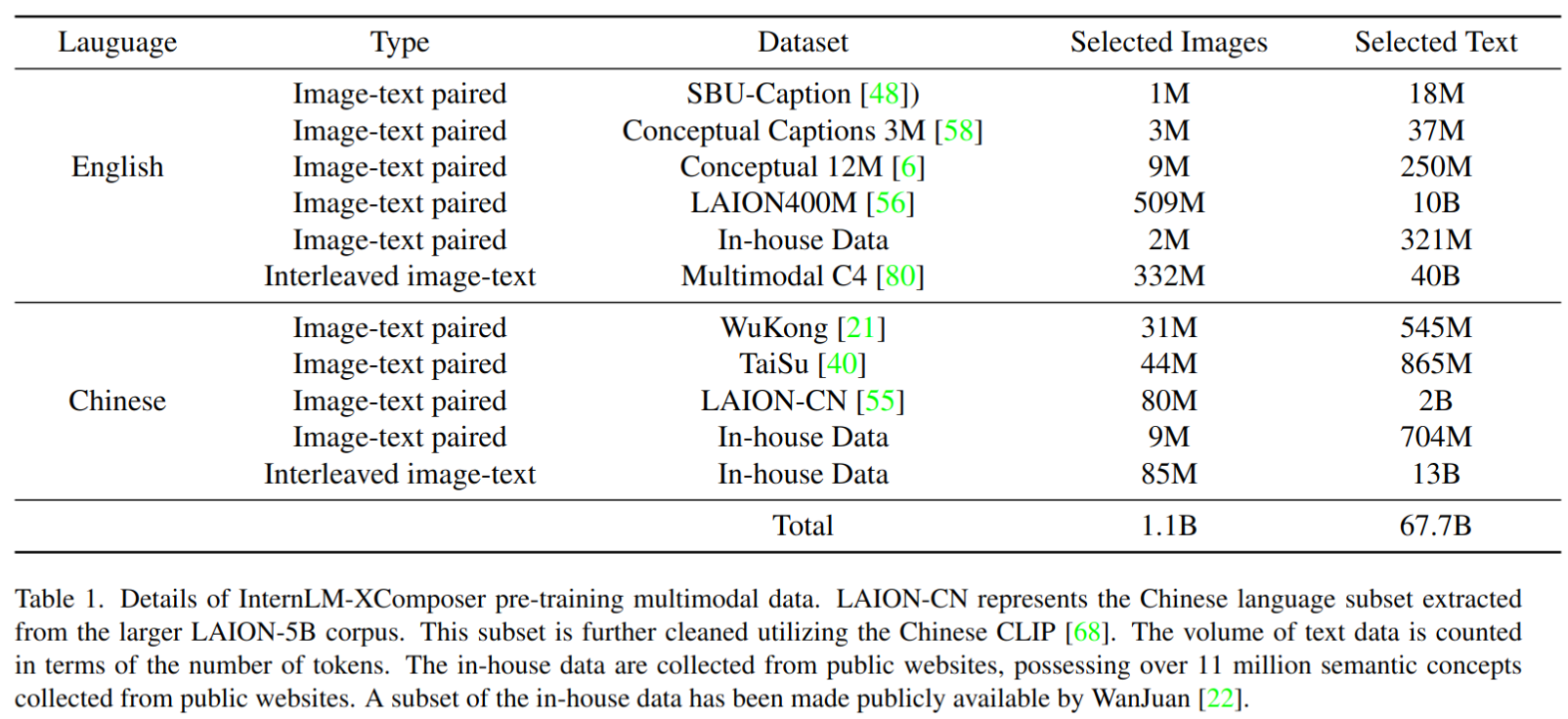
- 训练数据:大规模的网络爬取的图像-文本对,以及交错的图像-文本数据。1.1B 图像和 67.7B 文本 token,文本 token 中 50.6B 是英文,17.1B 是中文。同时,从 InternLM 的预训练数据集中抽样出的约 100 亿个文本 token 被纳入以维护模型的语言能力
- 感知采样器和大型语言模型的初始权重分别来自于 BLIP2 和 InternLM
- 由于大型语言模型缺乏对图像嵌入的理解,它在多模态预训练框架内的优化旨在增强其有效解释这些图像嵌入的能力。模型的训练目标集中在下一个 token 的预测上,使用交叉熵损失作为损失函数。
- 超参数设置:β1=0.9,β2=0.95,eps=1e-8。感知采样器和大型语言模型的最大学习率分别配置为 2e-4 和 4e-5,遵循余弦学习率调度。最小学习率设置为1e-5。此外,首个 200 个步骤采用线性 warmup。训练过程使用约 1570 万 token 的批量大小,共进行 8000 次迭代。在有限的迭代次数内使用如此大的批量大小有助于稳定的训练动态,并有助于保持 InternLM 的固有能力
监督微调
- 在预训练阶段,图像嵌入与语言表示进行了对齐,为大型语言模型提供了对图像内容的基本理解。然而,模型仍然不能熟练地利用这些图像信息。为了解决这一限制,我们在随后的监督微调阶段(SFT)中引入了各种视觉-语言任务,该阶段包含两个连续的步骤,即多任务训练和指令微调。
- 多任务训练,针对下表中的多任务数据进行训练:

- 微调数据格式
< |User| >:指令<eou>< |Bot| >:回答<eob>
其中,<eou>和<eob>分别代表用户和机器人的结束 token
- 为了实现稳定和高效的微调,将现有大型语言模型的权重保持在冻结状态。随后,我们使用 Low-Rank Adaption(LoRA)来进行微调。感知采样器同时进行训练,尽管学习率不同。具体来说,LoRA 应用于注意层的查询、值和键,以及前馈网络。我们发现,较高的 LoRA 秩有助于赋予模型新的能力;因此,我们将 LoRA 秩和 alpha 参数都设置为 256。模型在 10000 次迭代中使用全局批量大小为 256 进行训练。LoRA 层的学习率设置为 5e-5,感知采样器的学习率设置为 2e-5。
- 指令微调:为了进一步增强前述模型的指令遵循和交错的图像-文本组合能力,如上表所示,利用纯文本对话语料库和 LLava-150k 的数据进行基于指令的微调,并利用 LRV 数据集减轻幻觉。交错的图像-文本组合数据集的构建方式下一章节会介绍。保持批量大小为 256,并以小学习率 1e-5 进行 1000 step 训练
交错的图像文本组合
- 为了实现交错的图像-文本组合的目标,初始步骤涉及生成以文本为中心的文章。随后,在文本内容内合适的位置插入相关图像,从而丰富整体叙述并增强读者的参与感。
文本生成
- 为了促进生成扩展的基于文本的文章,策划了一个包含交错的图像-文本组合的数据集。需要注意的是,获得的数据集包含噪音,特别是以营销和广告内容的形式存在。为了解决这个问题,我们使用 GPT-4 来评估每个段落的噪音水平。任何被识别为嘈杂的段落,以及其中超过 30% 的内容被分类为嘈杂的文章,随后被过滤出数据集。为了使模型能够根据特定的标题生成基于文本的文章,根据以下方式制定了训练数据:

在这里,{Title}充当文章标题的占位符,而[para1]和[paraN]分别表示第一个和最后一个段落。 - 为了增强生成的以文本为中心的文章的视觉吸引力和参与度,需要加入与上下文相关的适当图像。为了实现这一目标,建立了一个数据库,作为图像选择的候选池。整个过程分为两个主要组成部分:
- 图像定位,用于识别文本内图像集成的合适位置
- 图像选择,旨在选择最具上下文意义的图像。图像选择的基本策略涉及总结前面的文本内容,并从可用的图像池中检索与之最相关的图像。
- 然而,这种方法不足以维护文章中图像的连贯主题流。为了弥补这一限制,建议使用本文训练好的的视觉语言基础模型。这个模型被设计为选择一组图像,这些图像不仅具有上下文相关性,而且在整个文章中保持主题的一致性。为了提高计算效率,我们最初使用检索机制来减小候选图像池的大小。随后,我们的视觉语言模型被用于从这个缩小的候选集中进行最终的图像选择。因此,这个总体任务被分解为图像定位和字幕,以及图像检索和选择。
Image Spotting and Captioning(图像定位和字幕)
- 利用获得的交错的图像-文本组合,定位图像的位置变得简单。为了进行后续的图像检索,生成适当的字幕至关重要,以便应用各种文本-图像检索算法。发现用本文 7b 预训练模型为图像生成字幕效果不好,往往会错过文章的中心主题或概念。为了解决这一挑战,提出了一个监督微调的方法,利用 GPT4 生成的字幕数据。为了创建这些数据, GPT-4 被提供文本文章和图像位置,并被要求生成一个与文章的整体主题和概念保持一致的字幕,特别用于图像检索目的。在生成数据之后,训练数据结构如下:

在这里,[seg1] 充当索引标记,用于确定特定段落的索引。占位符 {x1} 和 {xk} 分别代表第一个和最后一个图像位置的位置。相应地,{cap1} 和 {capk}作为与这些图像位置相关的生成字幕
Image Retrieval and Selection(图像检索和选择)
- 获得了图像字幕后,就可以使用各种文本-图像检索方法。在这项工作中,我们选择了 CLIP 模型,充分利用了它在零样本分类任务中已被证明有效的能力。我们计算生成的字幕与候选池中的每个图像之间的相似性分数。基于这些相似性分数,选择前 m 个图像,以构成候选池以供进一步处理。为了确保文章中散布的图像在主题或概念上具有一致性,我们部署了我们的视觉语言模型来执行最终的图像选择。在选择要与第 j 段一起显示的图像时,训练数据的结构如下:

在这个配置中,[imgi]表示与第 i 段相关的图像(位于第j段之前)。[img1j],…,[imgmj]代表了候选图像池中的图像。同时,{selected index} 充当占位符,表示最终选定图像的索引 - 视觉语言模型通过考虑文章中之前的文本和图像来选择图像。这个机制使模型能够获得主题和视觉连贯性的理解,这种专业知识来自经过精心策划的交错图像-文本组合数据集。
Experiments
多模态测试 BMK 介绍
- 英文 BMK
- MME Benchmark(多模态理解基准测试):测量了多模态大型语言模型的感知和认知能力,其中包括14个子任务,每个子任务都有精心设计的问题。
- MMBench 是一个手工制作的挑战性基准测试,评估了具有多选题的视觉相关推理和感知能力
- Seed-Bench是一个大规模的多模态基准测试,是在GPT-4的帮助下构建的,包含了近19,000个关于图像和视频的多选题
- 中文 BMK
- MMBench-CN是原始MMbench的中文翻译基准测试,展示了与视觉相关的中文理解和推理能力。
- Chinese-Bench是一个与中文相关的知识基准测试,挑战模型回答有关中国传统文化的问题,包括艺术、食物、服装、地标等
定量评测结果
-
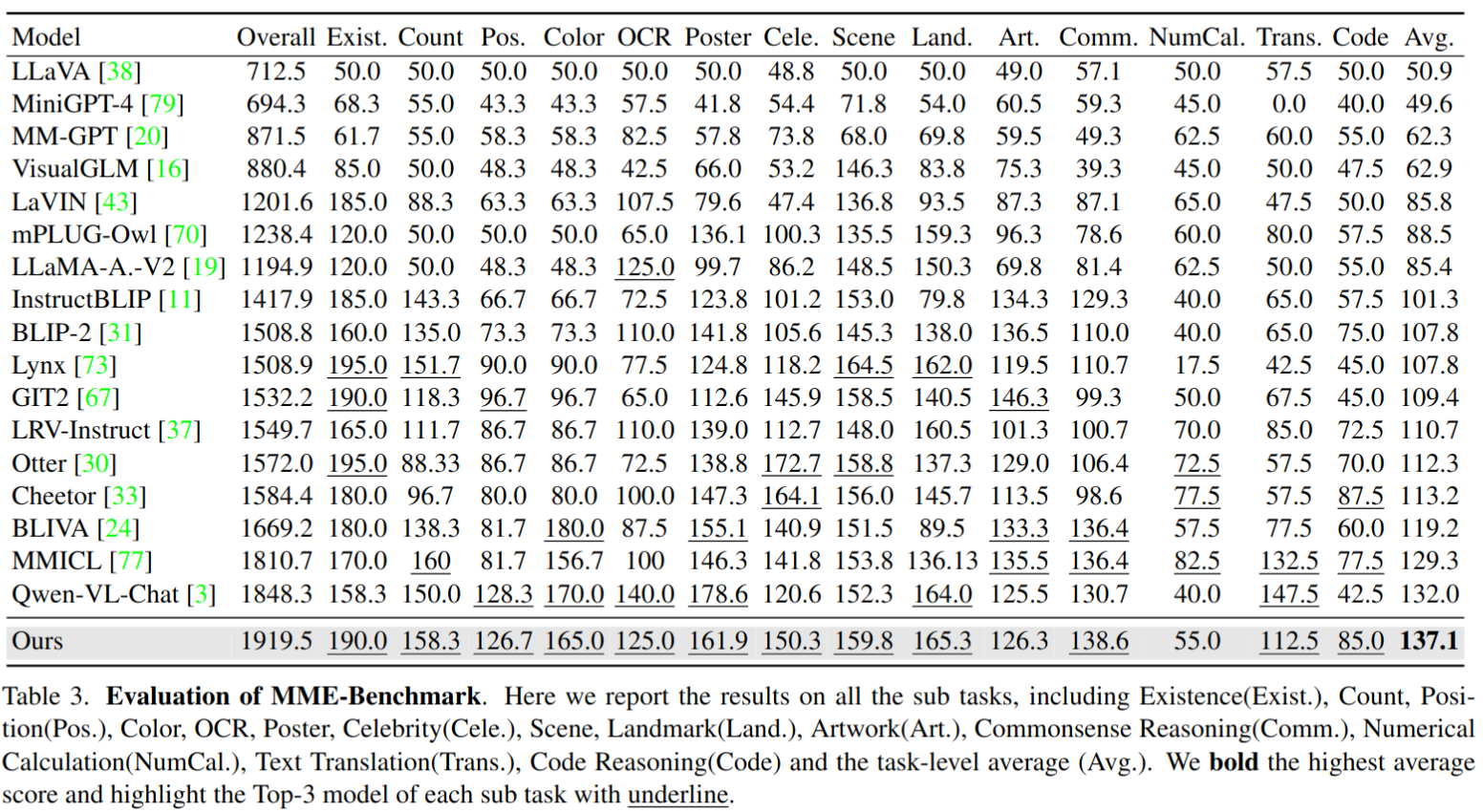
MME 结果。超过了之前的方法 QWen-VL-Chat 5.0%。还在每个子任务的前三名模型上划线,并注意到我们的模型在 14 个子任务中有 12 个达到了前三名的表现
-
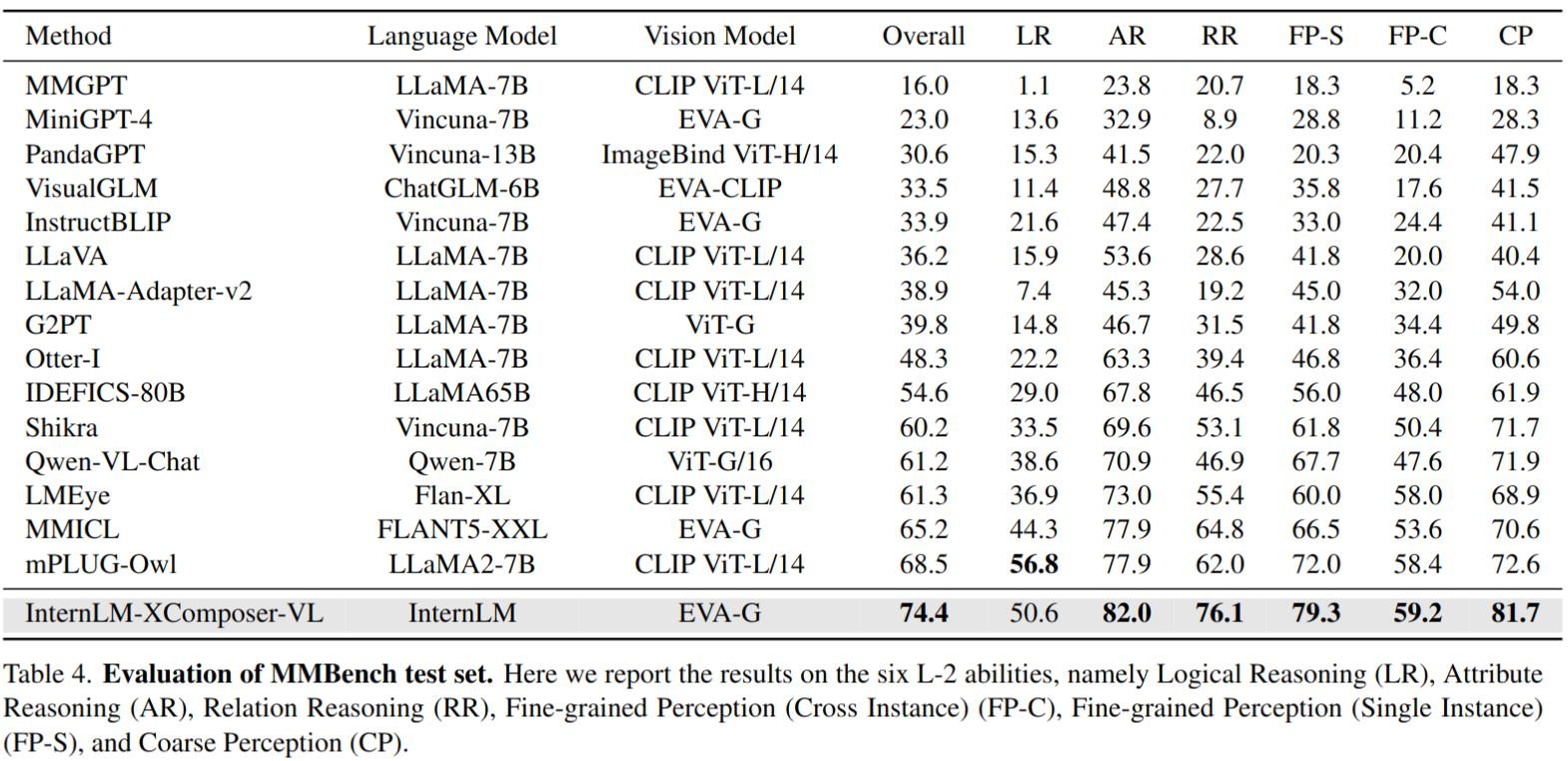
MMBench 结果,其中 6 个评估维度上达到 SOTA
-
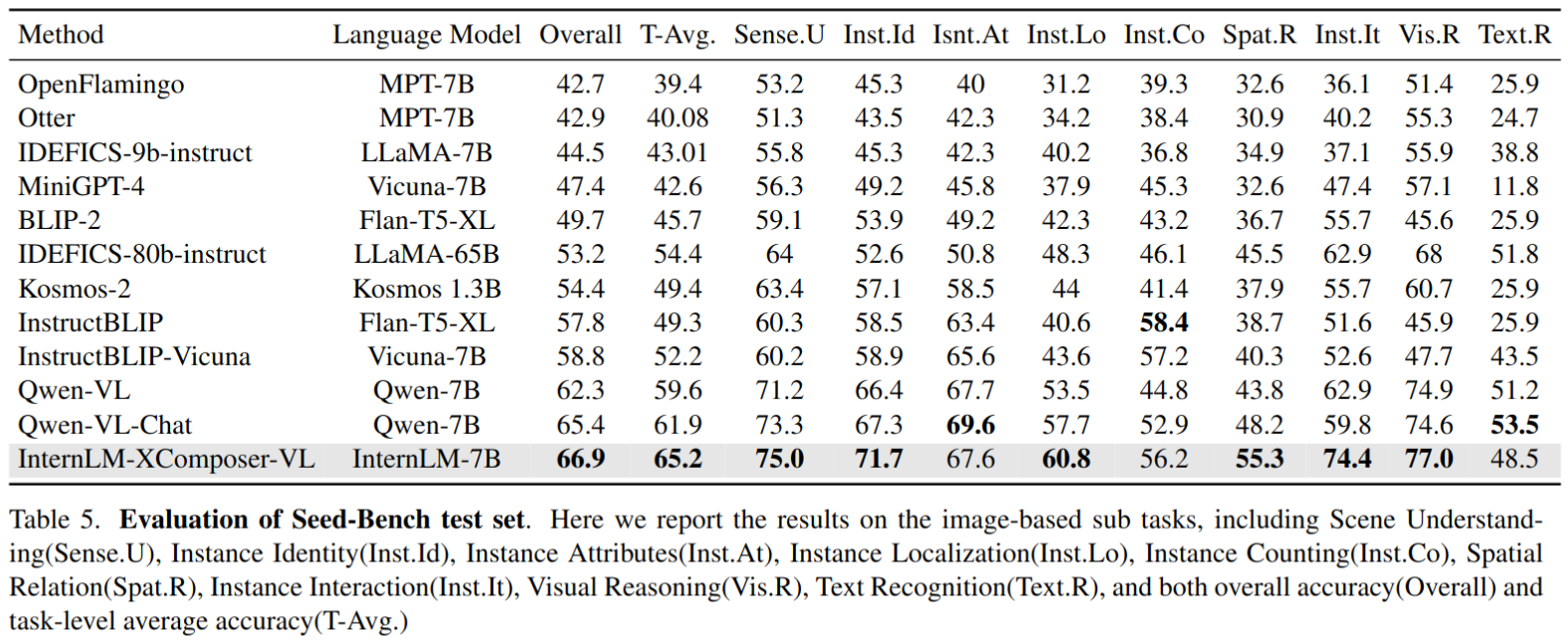
Seed-Bench,在9个子任务中有6个子任务表现最佳
-
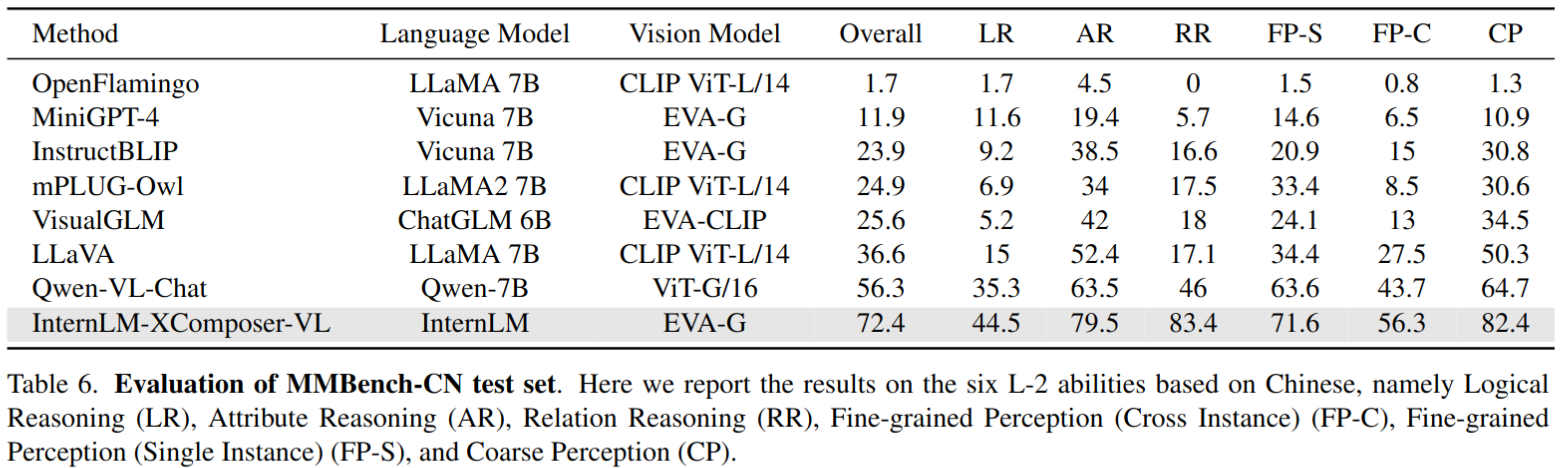
MMBench-CN 结果,与 MMBench 的英文版本性能相比,Qwen 和 VisualGLM 的性能分别下降了 4.9% 和 7.9%,而我们的模型在不同语言之间的性能差距只有 2.0%。这证明了我们模型的强大的多语言能力。
-
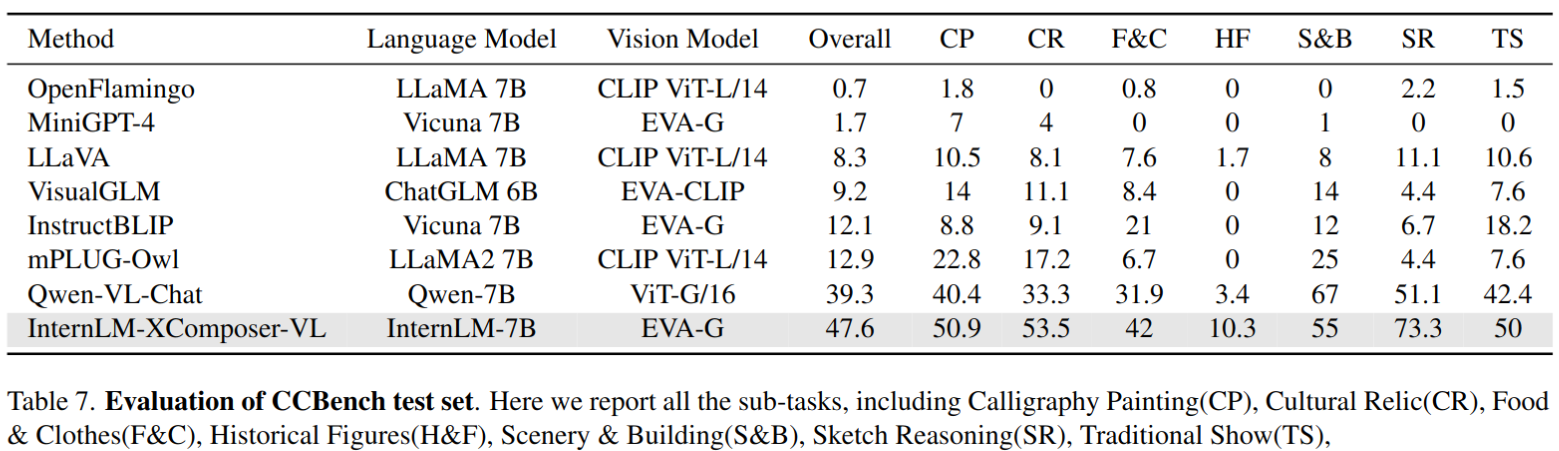
Chinese-Bench 结果,大多数基于LLaMA的模型无法回答这些问题,因为它们缺乏相应的知识
定性测试结果
- 样例1




- 样例2
- 样例3:

Thoughts
- 整体训练流程介绍详细,其中图文交织数据的准备也花了比较多篇幅进行介绍
- 模型结构上没有精心设计的地方,怀疑精度提升主要还是来源于数据的构造和清洗,其中的细节本文没有详细介绍。
- 本文模型精度由于 qwenvl 的原因还有可能是 qformer 这里使用le blip2 的预训练参数初始化,同时 qwenvl 只使用了一层 cross attention 层,本文模型的参数量应该更大
















 288
288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









