






目录
intelligent chatting demo--InternLM_7B_model
image-text creating demo--InternLM_Xcomposer_7B_model:
intelligent chatting demo--InternLM_7B_model
InternLM-7B介绍:
大约70e参数与一个为实际场景准备好的基础对话模型,支持8k token的上下文长度。
实践:
模型下载:internstudio平台内置了模型,位置在/share里面,如果是自己在别的平台使用或者自己电脑使用见于本文最后的模型下载部分。
#linux 复制指令:
cp -r $要复制的目标的路径$ $你想复制去哪里的路径$ # -r 含义是递归得复制目录下所有文件示例代码克隆:
git clone https://gitee.com/internlm/InternLM.git
cd InternLM
git checkout 3028f07cb79e5b1d7342f4ad8d11efad3fd13d17 #切换 commit 版本,与demo的 commit 版本保持一致,避免出现莫名其妙的错误
---------------------------------------------------------阅读代码-------------------------------------------------------
将会使用web_demo.py文件,可以发现其中方便了没有下载模型的用户,在load_model中书写的是网络下载模型版本,如果已经下载了模型,请替换为自己的模型路径。
交互运行:
示例中tokenizer,model是这么2个需要传入的参数,作用看来是load已经可是使用的模型进入gpu显存,注意,在使用的时候也是吃gpu显存的。

下面是示例代码:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name_or_path = "/root/model/Shanghai_AI_Laboratory/internlm-chat-7b"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, trust_remote_code=True, torch_dtype=torch.bfloat16, device_map='auto')
model = model.eval()
system_prompt = """You are an AI assistant whose name is InternLM (书生·浦语).
- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.
- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文.
"""
messages = [(system_prompt, '')]
print("=============Welcome to InternLM chatbot, type 'exit' to exit.=============")
while True:
input_text = input("User >>> ")
input_text.replace(' ', '')
if input_text == "exit":
break
response, history = model.chat(tokenizer, input_text, history=messages)
messages.append((input_text, response))
print(f"robot >>> {response}")测试效果:


上面两图为示例,很好地回答了日常性对话,但对于逻辑性附带要求的话反应似乎有一些差。
将端口映射到本地以网页方式打开版:
streamlit run web_demo.py --server.address 127.0.0.1 --server.port 6006需要配置ssh端口,不过既然都用本地vscode 来访问了肯定都完成了,直接输入上方代码即可,个人不太理解streamlit要求,是个我的知识盲点。并且体验下来streamlit下的网页访问会很慢,load_model跑的时间远远大于终端中(也许是第一次使用?)但是人机交互界面看上去比终端舒服不少。简单查看web_demo中也没有类似设置,估计是streamlit这个package里面做了对于界面的优化?看得出这个界面设计是贴合internlm的。

Lagent智能体框架介绍:
这是一个智能体框架,用于将大语言模型转换成多种类型的智能体,进行与外部api的交互,获得新信息。
安装:
git clone https://gitee.com/internlm/lagent.git
cd /root/code/lagent
git checkout 511b03889010c4811b1701abb153e02b8e94fb5e
pip install -e . # 使用文件夹内的setup本地安装修改部分代码:见视频中,本块内容修改过多不适合贴出。
效果:


image-text creating demo--InternLM_Xcomposer_7B_model:
与之前类似,换用xcomposer的仓库与代码即可
git clone https://gitee.com/internlm/InternLM-XComposer.git这里暂时只展示效果了,之后考完试有空再来具体看看一些代码使用知识:
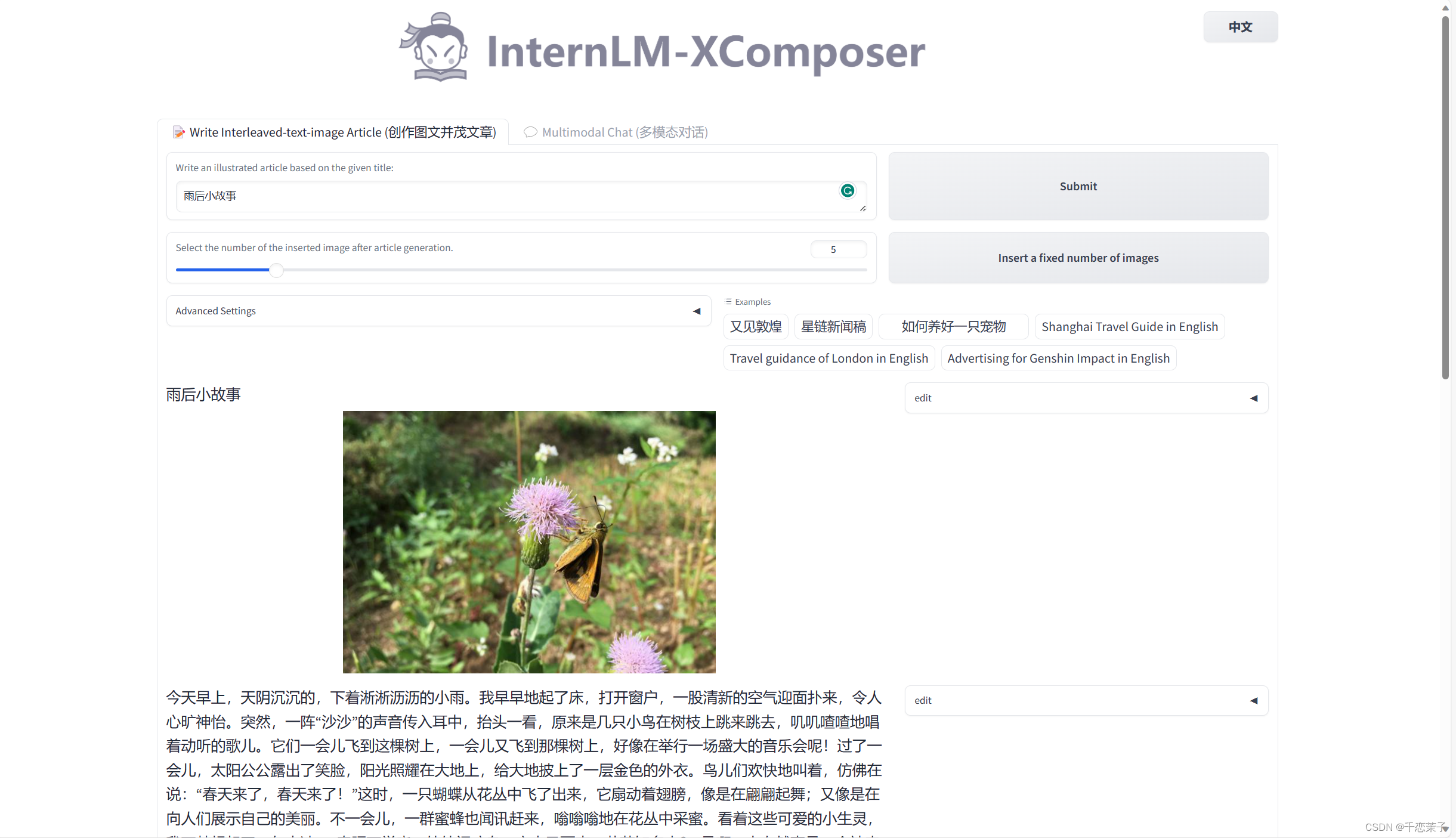
还试了一下别的关键词,但就像前一篇里说的,internlm的训练数据很有价值观,所以没有什么奇怪的内容,你懂的。
环境配置与模型下载:
一般来说,国内计算云平台的机器都是在国内,并且配置好了清华源,不用再调整了,反而是要担心访问github的速度,可以使用时检查是否有gitee的镜像,使用gitee的clone肯定能更快些。
使用hugging-face模型时,hugging_face也做了类似于openmim的官方下载工具:huggingface-cli,通过install -U huggingface_hub之后即可使用,具体见huggingface的官方docs的install部分。
如上节课提到的,openxlab也提供了模型下载,需要置顶模型仓库,下载文件名称,和存放位置。安装的话直接pip install -U openxlab,例子如下:
from openxlab.model import download
download(model_repo:'', model_name='', output='')顺带一提课后作业2的huggingface地址和做法:
import os
from huggingface_hub import hf_hub_download # Load model directly
hf_hub_download(repo_id="internlm/internlm-20b", filename="config.json")
# 地址:https://huggingface.co/internlm/internlm-20b/tree/main













 300
300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









