









CUDA编程(三)
评估CUDA程序的表现
上一篇博客我们基本上搭建起来了CUDA程序的骨架,但是其中并没有涉及到我们之前不断提到的并行加速,毕竟只有当我们的程序高并行的运行在GPU上才能大大缩短运行时间。不过在加速之前我们还有一件非常重要的事情需要考虑,那就是我们的程序到底有没有一个好的表现,也就是我们要准确计算程序的运行时间,这对之后的程序优化也有至关重要的作用,所以值得我们去仔细研究一下~
这里所谓的计算运行时间也不是单纯意义上的看运行时间,更重要的是我们要通过核函数的运行时间去计算程序实际上所使用的内存带宽,与显卡的性能进行比较,看看我们到底发挥了GPU的几成功力,像上一篇博客里的那个程序,其所使用的内存带宽大概只有 5M/s,而我们之前也提到过了,像GeForce 8800GTX这样比较老的显卡,也具有超过50GB/s 的内存带宽 。所以只有学会评估程序,才能不断去优化程序,直到驾驭我们的显卡。
计算核函数运行时间
clock函数
评估程序在GPU上的运行时间我们需要使用CUDA提供的一个Clock函数,这个函数将会返回GPU执行单元的频率(timestamp),这十分适合用来判断一段程序执行所花费的时间。
我们首先来看一下之前写好的CUDA程序骨架,然后我们的任务就是加上计算程序运行时间的功能:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
首先我们需要先引入time.h,才能使用clock_t
- 1
- 1
然后我们需要先改动一下我们的核函数sumOfSquares,因为之前提到过了,核函数是不能有返回值的,我们现在不仅需要返回计算结果,还需要一个返回运行时间的参数,同时调用clock函数获取开始时间,通过做差计算出运行时间。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
因为需要记录时间,我们也需要为这个记录时间的变量开辟一块内存,所以开辟显存的部分也需要进行更改
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
调用核函数的部分也要加一个参数
- 1
- 1
最后不要忘记从显存拿回时间并且输出出来
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
经过以上改造我们就能成功的输出clock函数的结果了~
完整程序:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
运行结果:
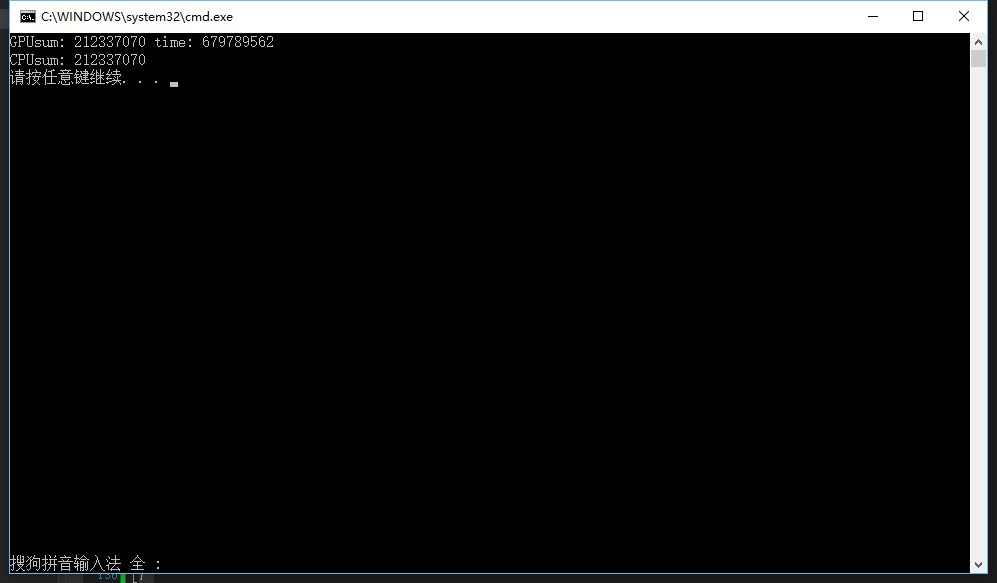
(另外说一下我的环境,这里用的是Debug,后面不说明的话也是Debug下的,Release的话还会快10倍左右。然后我的显卡是NVIDIA GeForce GT 640
也够老的,主要是因为我另一台电脑用户文件夹是中文的,所以死活用不了CUDA,我又不想重装系统,所以知道怎么改用户文件夹的同学一定要告诉我啊,555555555)
我们看到输出的时间很奇怪:679743997,其实这个地方返回的是GPU执行单元的频率,也就是GPU的时钟周期(timestamp),需要除以GPU的运行频率才能得到以秒为单位的时间。那么问题来了,我们怎么去获取准确的GPU信息呢,这对我们今后的优化也有着重大意义。
获取GPU的详细信息:
之前我们提到过CUDA的初始化过程我们要获取 CUDA 的设备数,然后利用其支持CUDA版本的属性来判断是否是仿真器,最终判断是否机器上具有完备的CUDA开发环境。其实在使用cudaGetDeviceProperties获取设备属性的时候,我们获取的是一个关于设备的属性集合,现在我们来具体的看一下这个函数:
函数说明:
以*prop形式返回设备dev的属性。
返回值:
cudaSuccess、cudaErrorInvalidDevice,注,如果之前是异步启动,该函数可能返回错误码。
cudaDeviceProp 结构定义:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
cudaDeviceProp 结构中的各个变量的意义:
-
name
用于标识设备的ASCII字符串; -
totalGlobalMem
设备上可用的全局存储器的总量,以字节为单位; -
sharedMemPerBlock
线程块可以使用的共享存储器的最大值,以字节为单位;多处理器上的所有线程块可以同时共享这些存储器; -
regsPerBlock
线程块可以使用的32位寄存器的最大值;多处理器上的所有线程块可以同时共享这些寄存器; -
warpSize
按线程计算的warp块大小; -
memPitch
允许通过cudaMallocPitch()为包含存储器区域的存储器复制函数分配的最大间距(pitch),以字节为单位; -
maxThreadsPerBlock
每个块中的最大线程数 -
maxThreadsDim[3]
块各个维度的最大值: -
maxGridSize[3]
网格各个维度的最大值; -
totalConstMem
设备上可用的不变存储器总量,以字节为单位; -
major,minor
定义设备计算能力的主要修订号和次要修订号; -
clockRate
以千赫为单位的时钟频率; -
textureAlignment
对齐要求;与textureAlignment字节对齐的纹理基址无需对纹理取样应用偏移; -
deviceOverlap
如果设备可在主机和设备之间并发复制存储器,同时又能执行内核,则此值为 1;否则此值为 0; -
multiProcessorCount
设备上多处理器的数量。
我们可以写一个函数来把这些信息都输出出来,这样我们就能获得我们GPU的全部信息了,更重要的是获得我们所关心的时钟频率:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
我们把这个函数放到初始化CUDA的InitCUDA()函数中去使用,这样就能把每个设备的信息打印出来。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
运行结果:
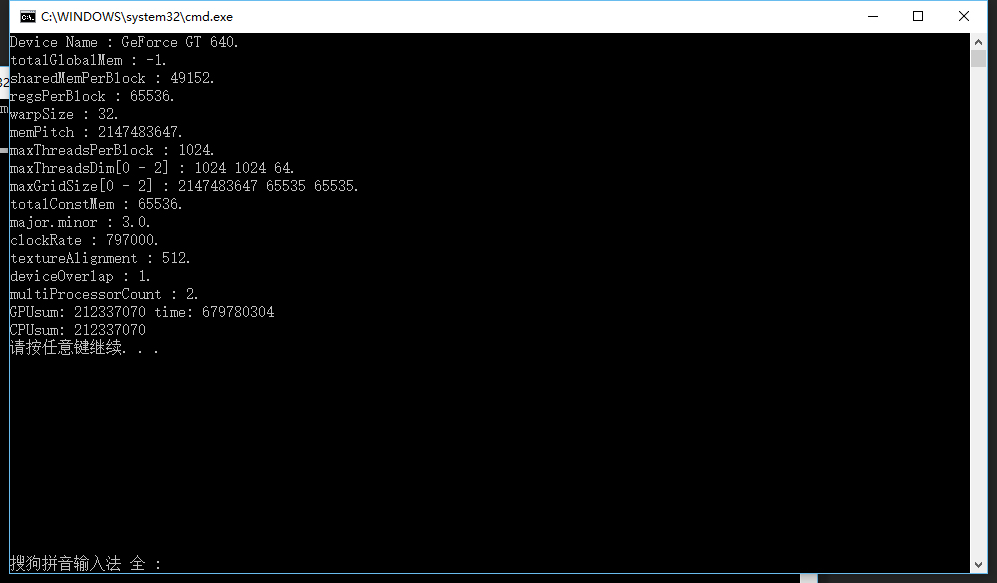
在这里我们就很清楚的看到了GPU的各项信息,包括最大的Thread数,Grid数等等,这对后面的并行优化也是很有价值的。然后我们看到我的GPU的时钟频率是797000千赫兹,于是我们就可以计算出这次运行核函数部分的时间约为:
679680304 / (797000 * 1000) = 0.853S
计算使用的内存带宽:
我们的数据量为:DATA_SIZE 1048576,也就是1024*1024 也就是 1M
1M 个 32 bits 数字的数据量是 4MB。
因此,这个程序实际上使用的内存带宽约为:
4MB / 0.853S = 4.68MB/s
只有4.68MB/s 左右!这是非常糟糕的表现,因为我们之前也提到过了,像GeForce 8800GTX这样比较老的显卡,也具有超过50GB/s 的内存带宽,不过产生这种现象的原因和解决我们留到下次~
那么我们为什么着呢在意内存带宽呢,这里给大家补充一下写出一个优异的CUDA程序所要经过的步骤。
什么是优秀的CUDA程序:
为了短时间内完成计算,需要考虑算法、并行划分、指令吞吐量、存储器带宽等多方面因素,总的来说一个优秀的CUDA程序应该具有下面这些特征:
-
在给定的数据规模下,选用算法的计算复杂度不明显高于最优的算法;
-
Active warp的数量能够让SM满载,并且active block的数量大于2,能够有效地隐藏访存延迟(使用足够大的内存带宽);
-
当瓶颈出现在运算指令时,指令流的效率已经过了充分优化;
-
当瓶颈出现在访问IO时,程序已经选用了恰当的存储器来储存数据,并使用了适当的存储器访问方式,以获得最大带宽;
CUDA程序编写优化步骤:
如何完成一个优秀的CUDA程序呢?这里有一份步骤给大家参考:
-
确定任务中的串行和并行的部分,选择合适的算法(首先将问题分解为几个步骤,确定哪些步骤可以用并行实现,并确定合适的算法);
-
按照算法确定数据和任务的划分方式,将每个需要实现的步骤映射为一个满足CUDA两层并行模型的内核函数,让每个SM上至少有6个活动warp和至少2个活动block;
-
编写一个能正确运行的程序作为优化的起点,要确保程序能稳定运行以及其正确性,在精度不足或者发生溢出时必须使用双精度浮点或者更长的整数类型;
-
优化显存访问,避免显存带宽成为瓶颈。在显存带宽得到完全优化前,其他优化不会产生明显效果。
-
优化指令流,在误差可接受的情况下,使用CUDA算术指令集中的快速指令;避免多余的同步;在只需要少量线程进行操作的情况下,使用类似
“if threaded<N”的方式,避免多个线程同时运行占用更长时间或者产生错误结果; -
资源均衡,调整每个线程处理的数据量,shared memory和register和使用量;通过调整block大小,修改算法和指令以及动态分配shared memory,都可以提高shared的使用效率;register的多少是由内核程序中使用寄存器最多的时刻的用量决定的,因此减小register的使用相对困难;节约register方法是使用shared memory存储变量;使用括号明确地表示每个变量的生存周期;使用占用寄存器较小的等效指令代替原有指令;
-
与主机通信优化,尽量减少CPU与GPU间的传输,使用cudaMallocHost分配主机端存储器,可以获得更大带宽;一次缓存较多的数据后再一次传输,可以获得较高的带宽;需要将结果显示到屏幕的时候,直接使用与图形学API互操作的功能;使用流和异步处理隐藏与主机的通信时间;使用zero-memory技术和Write-Combined memory提高可用带宽;
由此我们可以看到我们的优化之路还很漫长,这个优化步骤中的每一步都对应了大量可以去做的优化,上面这个只是个概述,不过我们可以看到有一句非常重要的话:
在显存带宽得到完全优化前,其他优化不会产生明显效果。
所以我们就先不要想其他的了,先完成最基本的优化,去尽可能的使用显卡的内存带宽~
总结:
这篇博客主要讲解了怎么去获取核函数执行的准确时间,以及如何去根据这个时间评估CUDA程序的表现,也就是推算所谓的内存带宽,总的来说有了这些准备,我们接下来就可以尽情去优化程序了~但是优化过程也是十分复杂与漫长的,我们首先需要解决内存带宽问题。希望我的博客能帮助到大家~















 1173
1173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









