







系列文章目录
前言
CUDA编程,就是利用GPU设备的并行计算能力实现程序的高速执行。CUDA内核函数关于网格(Grid)和模块(Block)大小的最优设置才能保证CPU设备的这种并行计算能力得到充分应用。这里介绍并行性衡量指标,可以衡量最优性能的网格和模块大小设置。
一. CUDA C并行性衡量指标介绍
占用率(nvprof 中的achieved occupancy):
占用率指的是活跃线程束与最大线程束的比率。活跃线程束足够多,可以保证并行性的充分执行(有利于延迟隐藏)。占用率达到一定高度,再增加也不会提高性能,所以占用率不是衡量性能的唯一标准。
延迟隐藏:一个线程束的延迟可以被其他线程束执行所隐藏。
线程束执行率(nvprof中的warp executation effeciency)
线程束中线程的执行
分支率(nvprof中的branch effeciency):
分支率是指未分化的分支数与所有分支数的比率,可以理解为这个数值越高,并行执行能力越强。这里的未分化的分支,是相对于线程束分化而言,线程束分化是指在同一个线程束中的线程执行不同的指令,比如在核函数中存在的if/else这种条件控制语句。同一线程束中的线程执行相同的指令,性能是最好的。nvcc编译器能够优化短的if/else 条件语句的分化问题,也就是说,你可能看到有条件语句的核函数执行时的分支率为100%,这就是CUDA编译器的功劳。当然,对于很长的if/else条件语句一定会产生线程束分化,也就是说,分支率<100%;
避免线程束分化的方法:调整分支粒度适应线程束大小的整数倍
每个线程束的指令数(nvprof中instructions per warp):
每个线程束上执行指令的平均数
全局加载效率(nvprof中 global memory load effeciency):
被请求的全局加载吞吐量与所需的全局加载吞吐量的比率,可以衡量应用程序的加载操作利用设备内存带宽的程度
全局加载吞吐量(nvprof中 global load throughout):
检查内核的内存读取效率,更高的加载吞吐量不一定意味着更高的性能。
二、案例介绍
1. 案例说明
这里以整数规约(数据累加求和)为例,实现了三种不同的内核函数,交错规约性能最好。
reduceNeighbored 内核函数流程(下图引用《CUDA C 编程权威指南》):
 reduceNeighboredLess 内核函数流程(下图引用《CUDA C 编程权威指南》):
reduceNeighboredLess 内核函数流程(下图引用《CUDA C 编程权威指南》):
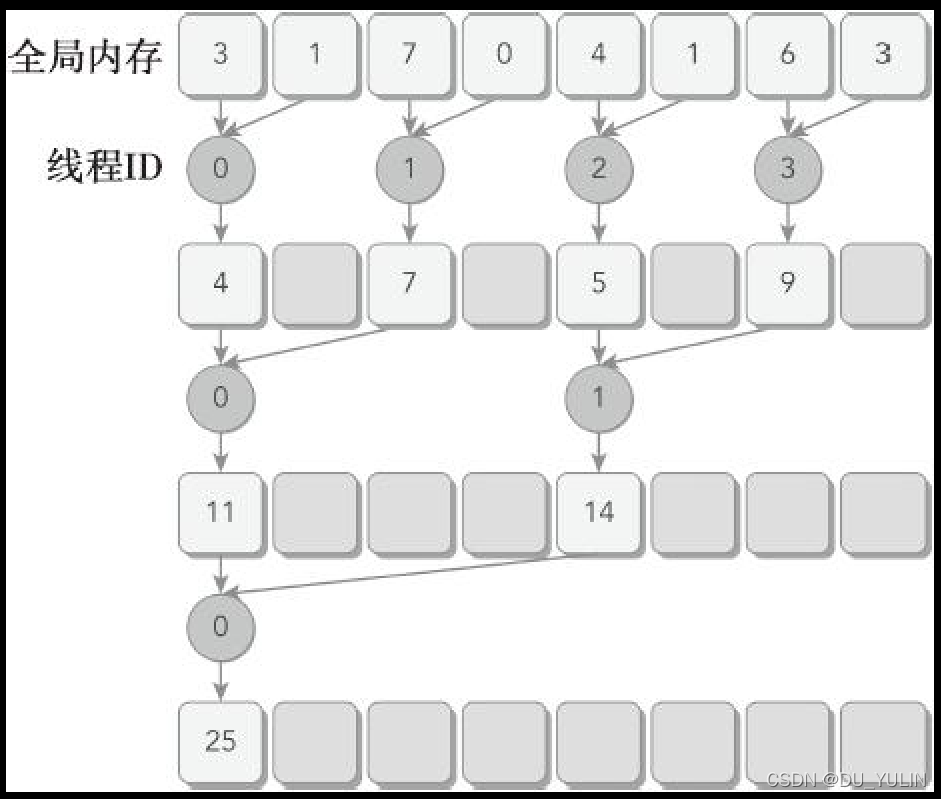 reduceInterLeave 内核函数流程(下图引用《CUDA C 编程权威指南》):
reduceInterLeave 内核函数流程(下图引用《CUDA C 编程权威指南》):

2. 案例实现
#include <stdio.h>
#include <iostream>
#include <cuda.h>
#include <cuda_runtime.h>
#include <cuda_runtime_api.h>
#include <device_launch_parameters.h>
#include <device_functions.h>
#include "CudaUtils.h"
//cpu recursive reduce
int recursiveReduce(int* data, const int size)
{
if (size == 1)
{
return data[0];
}
const int stride = size / 2;
// in-place reduction
for (int i = 0; i < stride; i++)
{
data[i] += data[i + stride];
}
//call recursively
return recursiveReduce(data, stride);
}
//accumulate by neighbor elements of array
__global__ void reduceNeighbored(int* g_idata, int* g_odata, unsigned int n)
{
//set thread ID
unsigned int tid = threadIdx.x;
//convert global data pointer to the local pointer of this block
int* idata = g_idata + blockIdx.x * blockDim.x;
//boundary check
if (tid >= n)
return;
// in-place reduction in global memory
for (int stride = 1; stride < blockDim.x; stride *= 2)
{
if (tid % (2 * stride) == 0)
{
idata[tid] += idata[tid + stride];
}
//synchronize within block, wait all threads finish within block
__syncthreads();
}
//write result for this block to global mem
if (tid == 0)
g_odata[blockIdx.x] = idata[0];
}
//accumulate by neighbor elements of array
__global__ void reduceNeighboredLess(int* g_idata, int* g_odata, unsigned int n)
{
//set thread ID
unsigned int tid = threadIdx.x;
unsigned int idx = threadIdx.x + blockIdx.x * blockDim.x;
//convert global data pointer to the local pointer of this block
int* idata = g_idata + blockIdx.x * blockDim.x;
//boundary check
if (idx >= n)
return;
// in-place reduction in global memory
for (int stride = 1; stride < blockDim.x; stride *= 2)
{
int index= 2 * stride * tid;
if (index < blockDim.x)
idata[index] += idata[index + stride];
//synchronize within block, wait all threads finish within block
__syncthreads();
}
//write result for this block to global mem
if (tid == 0)
g_odata[blockIdx.x] = idata[0];
}
//accumulate by neighbor elements of array
__global__ void reduceInterLeave(int* g_idata, int* g_odata, unsigned int n)
{
//set thread ID
unsigned int tid = threadIdx.x;
//convert global data pointer to the local pointer of this block
int* idata = g_idata + blockIdx.x * blockDim.x;
//boundary check
if (tid >= n)
return;
// in-place reduction in global memory
for (int stride = blockDim.x / 2; stride > 0; stride >>= 1)
{
if (tid < stride)
idata[tid] += idata[tid + stride];
//synchronize within block, wait all threads finish within block
__syncthreads();
}
//write result for this block to global mem
if (tid == 0)
g_odata[blockIdx.x] = idata[0];
}
int main()
{
int nDevId = 0;
cudaDeviceProp stDeviceProp;
cudaGetDeviceProperties(&stDeviceProp, nDevId);
printf("device %d: %s\n", nDevId, stDeviceProp.name);
cudaSetDevice(nDevId);
bool bResult = false;
//initialization
int size = 1 << 24; //total number of elements to reduce
printf("array size: %d \n", size);
//execution configuration
int nBlockSize = 512;// initial block size
dim3 block(nBlockSize, 1);
dim3 grid((size + block.x - 1) / block.x, 1);
printf("grid: %d, block: %d\n", grid.x, block.x);
//allocate host memory
size_t bytes = size * sizeof(int);
int* h_idata = (int*)malloc(bytes);
int* h_odata = (int*)malloc(grid.x * sizeof(int));
int* tmp = (int*)malloc(bytes);
//initialize the array
for (int i = 0; i < size; i++)
{
h_idata[i] = i;
}
memcpy(tmp, h_idata, bytes);
double dElaps;
int nGpuNum = 0;
//allocate device memory
int* d_idata = NULL;
int* d_odata = NULL;
cudaMalloc(&d_idata, bytes);
cudaMalloc(&d_odata, grid.x * sizeof(int));
//cpu reducation
CudaUtils::Time::Start();
int cpu_sum = recursiveReduce(tmp, size);
CudaUtils::Time::End();
dElaps = CudaUtils::Time::Duration<CudaUtils::Time::MS>();
printf("cpu reduce: elapsed %.2f ms gpu_sum: %d\n",
dElaps, cpu_sum);
// kernel 0: warpup -- reduceNeighbored
cudaMemcpy(d_idata, h_idata, bytes, cudaMemcpyHostToDevice);
cudaDeviceSynchronize();
CudaUtils::Time::Start();
reduceNeighbored << <grid, block >> > (d_idata, d_odata, size);
cudaDeviceSynchronize();
CudaUtils::Time::End();
dElaps = CudaUtils::Time::Duration<CudaUtils::Time::MS>();
cudaMemcpy(h_odata, d_odata, grid.x * sizeof(int), cudaMemcpyDeviceToHost);
size_t gpu_sum = 0;
for (int i = 0; i < grid.x; i++)
gpu_sum += h_odata[i];
printf("gpu Warmup: elapsed %.2f ms gpu_sum: %lld\n",
dElaps, gpu_sum);
// kernel 1: reduceNeighbored
cudaMemcpy(d_idata, h_idata, bytes, cudaMemcpyHostToDevice);
cudaDeviceSynchronize();
CudaUtils::Time::Start();
reduceNeighbored << <grid, block >> > (d_idata, d_odata, size);
cudaDeviceSynchronize();
CudaUtils::Time::End();
dElaps = CudaUtils::Time::Duration<CudaUtils::Time::MS>();
cudaMemcpy(h_odata, d_odata, grid.x * sizeof(int), cudaMemcpyDeviceToHost);
gpu_sum = 0;
for (int i = 0; i < grid.x; i++)
gpu_sum += h_odata[i];
printf("gpu Neighbored: elapsed %.2f ms gpu_sum: %lld\n",
dElaps, gpu_sum);
// kernel 2: reduceNeighboredLess - 减少线程束分化
cudaMemcpy(d_idata, h_idata, bytes, cudaMemcpyHostToDevice);
cudaDeviceSynchronize();
CudaUtils::Time::Start();
reduceNeighboredLess << <grid, block >> > (d_idata, d_odata, size);
cudaDeviceSynchronize();
CudaUtils::Time::End();
dElaps = CudaUtils::Time::Duration<CudaUtils::Time::MS>();
cudaMemcpy(h_odata, d_odata, grid.x * sizeof(int), cudaMemcpyDeviceToHost);
gpu_sum = 0;
for (int i = 0; i < grid.x; i++)
gpu_sum += h_odata[i];
printf("gpu NeighboredLess: elapsed %.2f ms gpu_sum: %lld\n",
dElaps, gpu_sum);
// kernel 3: reduceInterLeave - 减少线程束分化
cudaMemcpy(d_idata, h_idata, bytes, cudaMemcpyHostToDevice);
cudaDeviceSynchronize();
CudaUtils::Time::Start();
reduceInterLeave << <grid, block >> > (d_idata, d_odata, size);
cudaDeviceSynchronize();
CudaUtils::Time::End();
dElaps = CudaUtils::Time::Duration<CudaUtils::Time::MS>();
cudaMemcpy(h_odata, d_odata, grid.x * sizeof(int), cudaMemcpyDeviceToHost);
gpu_sum = 0;
for (int i = 0; i < grid.x; i++)
gpu_sum += h_odata[i];
printf("gpu InterLeave: elapsed %.2f ms gpu_sum: %lld\n",
dElaps, gpu_sum);
//free host memory
free(h_idata);
free(h_odata);
//free device memory
cudaFree(d_idata);
cudaFree(d_odata);
system("pause");
return 0;
}
3. 结果分析
 从运行时间看,reduceNeighbored内核函数最慢(线程束执行效率最低),reduceInterLeave内核函数最快(线程束执行效率最高)。
从运行时间看,reduceNeighbored内核函数最慢(线程束执行效率最低),reduceInterLeave内核函数最快(线程束执行效率最高)。
总结
衡量并行性的指标有很多,除了上面介绍的这些外,还有很多其他指标,通过均衡多个指标,评估并行能力,得到一个近似最优的网格和模块大小;通过后面的案例可以发现,最优的并行能力并不一定每一项衡量指标都是最优的。
参考资料
《CUDA C编程权威指南》















 1570
1570











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









