







CUDA编程(十)
使用Kahan’s Summation Formula提高精度
上一次我们准备去并行一个矩阵乘法,然后我们在GPU上完成了这个程序,当然是非常单纯的把任务分配给各个线程,也没有经过优化。最终我们看到,执行效率相当的低下,但是更重要的是出现了一个我们之前做整数立方和没遇到的问题,那就是浮点数精度损失的问题。
关注GPU运算的精度问题:
在程序的最后,我们计算了精度误差,发现最大相对误差偏高,而一般理想上应该要低于 1e-6。
我们之前将评估CUDA程序的时候也提过了,精度是CUDA程序需要重点评估的一个点,那么我们该如何解决这个问题呢?我们先分析一下原因。
出现精度问题的原因:
其实计算结果的误差偏高的原因很简单,在 CPU 上进行计算时,我们使用 double(即 64 bits 浮点数)来累进计算过程,而在 GPU 上则只能用 float(32 bits 浮点数)。在累加大量数字的时候,由于累加结果很快会变大,因此后面的数字很容易被舍去过多的位数。
这里可能说的不是很清楚,看完下面这个例子就清楚了。
浮点数的大数吃小数问题:
浮点数的精度:
大家应该很清楚,浮点数在内存中是按科学计数法来存储的,分为符号位,指数位,和尾数位。
float和double各段的位数分别是:
float:
1bit(符号位) 8bits(指数位) 23bits(尾数位)
double:
1bit(符号位) 11bits(指数位) 52bits(尾数位)
float和double的精度是由尾数的位数来决定的:
float: 2^23 = 8388608,一共七位,这意味着最多能有7位有效数字,但绝对能保证的为6位,也即float的精度为6~7位有效数字。
double: 2^52 = 4503599627370496,一共16位,同理,double的精度为15~16位。
大数吃小数:
float因为位数相较于double要短不少,所以很容易出现大数吃小数的问题:
比如我们用两个float相加:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
a+b 应该等于 101000.338,前面说了float的精度有6~7位,所以38可能会被截掉,3不一定,但是8必然会被截掉,我们可以实际输出一下看看:
结果是:the sum is 101000.335938
因为%f是输出double类型,可以看到转换后8这位已经没了,33是正常的。
从这里可以看到一个加法过程就没了0.008,要是加1000次,一个整8就没了。
这就是大数吃小数问题。
Kahan’s Summation Formula:
现在我们就要想办法解决这个问题了,我们看到标题中这个看起来很高大上的名字,这个也叫作kahan求和算法,我们接下来就要用kahan求和来避免这种精度损失的情况。
名字很高大上,但是原理很小儿科,小学生也知道,缺的我们想办法再补回来:
所以我们用一个temp变量来记住损失掉的部分,等下次加法的时候再加回去就好了。
temp= (a+b)-a-b; 在上面那个问题中 temp = -0.008,在下次计算的时候加和到下一个加数就可以一定程度的减小误差。
Kahan’s Summation Formula伪代码:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
提高矩阵乘法的精度:
看着伪代码比着葫芦画瓢还是比较简单的,我们只需要更改核函数中的加和部分即可:
原版
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
改版
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
完整程序:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
运行结果:
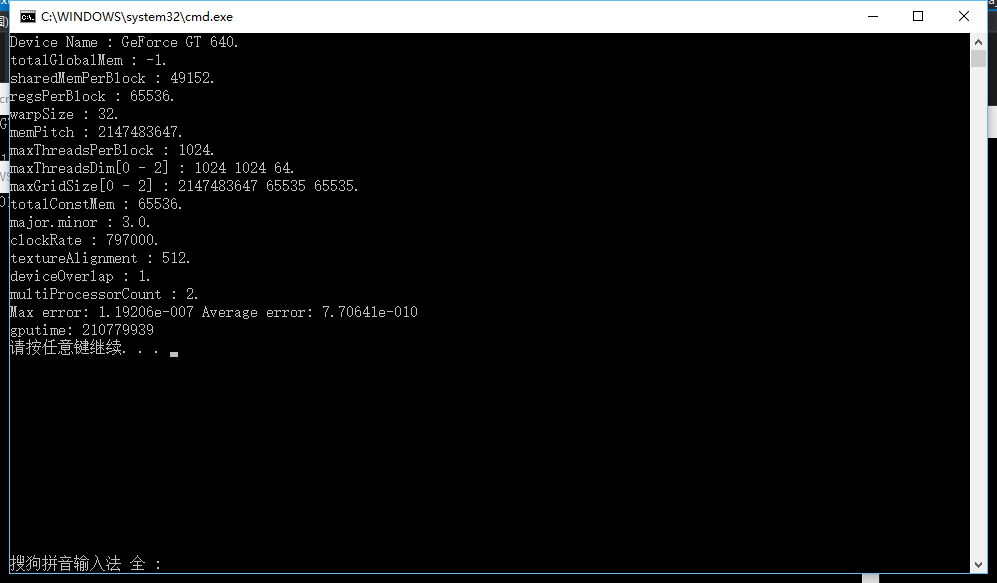
我们看到结果还是效果还是非常不错的,我们上次的结果是:
Max error:2.07589e-006
Average error :3.3492e-007
gpu time:189967999
而目前的结果是:
Max error:1.19206e-007
Average error :7.70641e-010
gpu time:210779939
我们可以看到精确度确实有了很大的提升,当然效率还是一如既往地慢,不过我们至少把精度问题给解决了。
总结:
之前我们用CUDA完成了矩阵乘法,但是当然会存在很多问题,除了速度问题,GPU浮点数运算的精度也很差,本篇博客从出现误差的原理(浮点数大数吃小数)分析,使用了Kahan’s Summation Formula在一定程度上解决了CUDA运算float精度不够的情况,接下来我们会着手去解决速度问题~
希望我的博客能帮助到大家~
参考资料:《深入浅出谈CUDA》














 826
826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









