






opencv基于haar特征和cascade分类器进行人脸识别,基于R-CNN进行物体识别。
要求:
先看完成情况:
所需python库:获取方式1.win+R-cmd-pip install+库名
获取方式2.pycharm环境下,File-Settings-Python Interpreter-点击加号进行下载
import cv2
import datetime
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import torchvision.transforms as T
import torchvision
import socket1、人脸识别及储存识别信息:
1.1、训练
要进行特定人脸的识别需要使用若干张照片进行训练,获得训练的数据,再捕捉特定人员的特征进而识别出信息。
import cv2
import os
import numpy as np
from PIL import Image
#训练
def getimagesandlabels(path):
facesamples = []
ids = []
imagepaths = [os.path.join(path, f) for f in os.listdir(path)]
face_detector = cv2.CascadeClassifier('D:\opencv\opencv\sources\data\haarcascades\haarcascade_frontalface_default.xml')
for imagePath in imagepaths:
pil_img = Image.open(imagePath).convert('L')
img_numpy = np.array(pil_img, 'uint8')
id = int(os.path.split(imagePath)[-1].split(".")[0])
faces = face_detector.detectMultiScale(img_numpy) #检测人脸
for(x, y, w, h) in faces:
facesamples.append(img_numpy[y:y+h, x:x+w])
ids.append(id)
return facesamples, ids
if __name__ == '__main__':
path = './train/' #训练使用图片的位置
faces, ids1 = getimagesandlabels(path)
recognizer = cv2.face.LBPHFaceRecognizer_create()
recognizer.train(faces, np.array(ids1))
recognizer.write('trainer/trainer.yml') #保存训练的数据我获得的训练结果:

1.2人脸识别
调用训练结果进行人脸识别和信息获取,并储存识别时间和人员id。
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
recognizer = cv2.face.LBPHFaceRecognizer_create()
recognizer.read('trainer/trainer.yml') #调用训练结果
cap = cv2.VideoCapture(0) #开启摄像头
def facecapture():
while True:
ret, frame = cap.read() #获得每帧画面存进frame
faces = face_cascade.detectMultiScale(frame, 1.3, 5)
img = frame
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) #图片灰化
for (x, y, w, h) in faces:
# 画出人脸框
img = cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
id, confidence = recognizer.predict(gray[y:y + h, x:x + h])
s = str(id) + str(',') + str(confidence)
if confidence < 80:
cv2.putText(img, str(s), (x, y - 7), 3, 0.75, (0, 0, 255), 2, cv2.LINE_AA)
# 实时展示效果画面
cv2.imshow('frame2', img)
k = cv2.waitKey(1) & 0xFF
if k == ord('c'):
t = datetime.datetime.now().date().isoformat()#获取当时时间
cv2.imwrite('./save/' + str(t) + str(' ') + str(id) + '.jpg', img)#储存图片及识别信息。id为识别结果,与训练时图片命名有关
print('success')
if k == ord('q'):
break
return img结果展示(n,1n,2n分别为不同人员,n为匹配的训练的第n张照片):

摄像头实时(很流畅~)显示样例(逗号后为置信度,越低越可靠):

2、通信
# 客户端设置
s = socket.socket()
host = 'ip' # ip为所用ip地址
port = 12345 # 设置端口
s.bind((host, port)) # 绑定端口
s.listen(5)
# 服务端连接
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
address_server = ('ip', 12345)
sock.connect(address_server) # 失败会自动反馈
print('connected success')利用socket进行数据传输(本文未能成功传输视频,帧率太低)
3、物体识别
直接下载训练完的结果,进行物体识别。
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
model.eval()
COCO_INSTANCE_CATEGORY_NAMES = [
'__background__', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A', 'stop sign',
'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack', 'umbrella', 'N/A', 'N/A',
'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket',
'bottle', 'N/A', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl',
'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table',
'N/A', 'N/A', 'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'N/A', 'book',
'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush'
] #官方提供的分类
#识别物体
def get_prediction(img_path, threshold):
img = Image.open(img_path)
img = img.convert('RGB')
transform = T.Compose([T.ToTensor()])
img = transform(img)
pred = model([img])
pred_class = [COCO_INSTANCE_CATEGORY_NAMES[i] for i in list(pred[0]['labels'].numpy())]
pred_boxes = [[(int(i[0]), int(i[1])), (int(i[2]), int(i[3]))] for i in list(pred[0]['boxes'].detach().numpy())]
pred_score = list(pred[0]['scores'].detach().numpy())
pred_t = [pred_score.index(x) for x in pred_score if x > threshold][-1]
pred_boxes = pred_boxes[:pred_t + 1]
pred_class = pred_class[:pred_t + 1]
print("pred_class:", pred_class)
print("pred_boxes:", pred_boxes)
return pred_boxes, pred_class
#展示识别结果
def object_detection_api(img_path, threshold=0.5):
boxes, pred_cls = get_prediction(img_path, threshold)
img = cv2.imread(img_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
#画出物体框
for i in range(len(boxes)-1):
cv2.rectangle(img, (boxes[i][0]), (boxes[i][1]), color=(0, 255, 0), thickness=2)
cv2.putText(img, (str(i+1)+pred_cls[i]), (boxes[i][0]), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), thickness=1)
plt.imshow(img)
plt.show()结果展示:
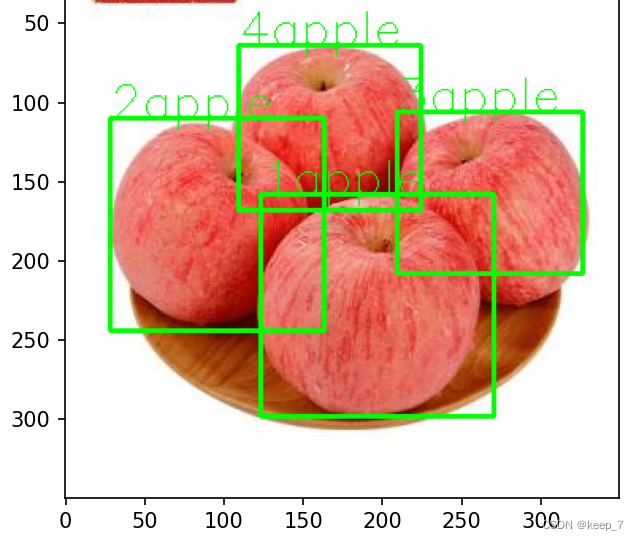
前文包装的函数直接调用,即可获得结果:
img=facecapture()
# 通信,发送照片信息
encode_param = [int(cv2.IMWRITE_JPEG_QUALITY), 50]
img_encode = cv2.imencode('.jpg', img, encode_param)[1]
data = np.array(img_encode)
stringData = data.tobytes()
sock.send(stringData)
print(str(stringData))
object_detection_api(img_path='test/0202.jpeg') # 输入物体照片路径即可
cap.release()
cv2.destroyAllWindows()发送的信息(很长,不全部截取了):
![]() PS:物体识别可多种物体同时检测:
PS:物体识别可多种物体同时检测:

以上便是所有功能及结果展示。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









