







1. 知识蒸馏简介
什么是知识蒸馏?
知识蒸馏(Knowledge Distillation)是一种模型压缩技术,目标是让一个较小的模型(学生模型,Student Model)学习一个较大、性能更优的模型(教师模型,Teacher Model)的知识。这样,我们可以在保持较高准确率的同时,大幅减少计算和存储成本。
相关论文
Distilling the Knowledge in a Neural Network
核心原理
知识蒸馏的核心思想是教师模型通过其预测结果(如概率分布或推理过程)向学生模型传授知识,而学生模型通过学习这些结果逐步提升自己的性能。以下结合流程图具体说明这一过程:
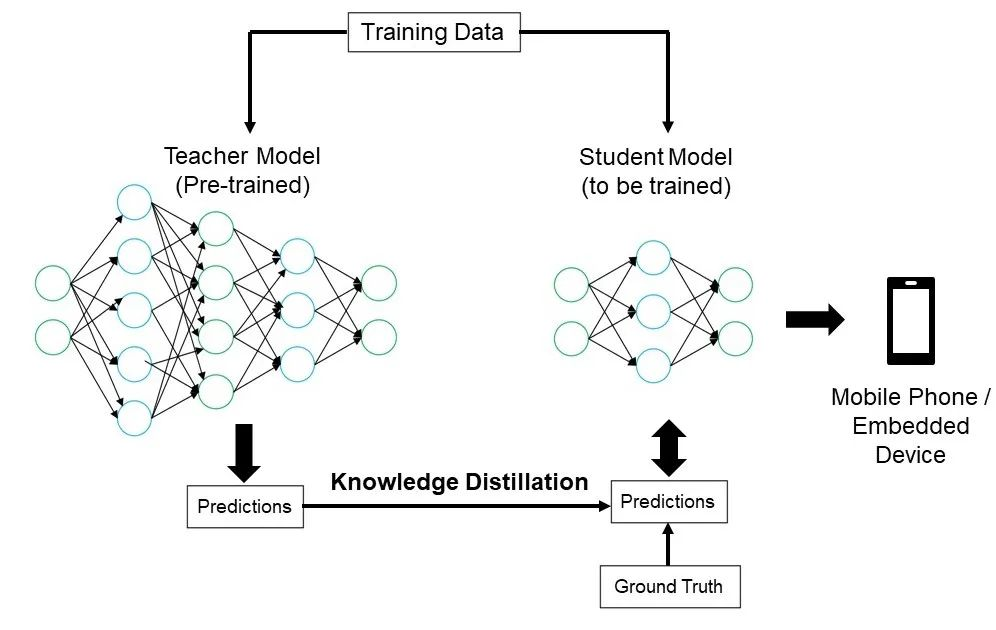
1. 教师模型的作用:
预先训练的教师模型是一个复杂而强大的网络,经过大规模数据训练后,可以提供高质量的预测。例如,它可以预测一个输入属于某个类别的概率分布,而不仅仅是单一的类别标签(即“软标签”)。
在图中,左侧的大型神经网络表示教师模型。
2. 学生模型的训练:
学生模型是一个较小的网络,其复杂度和参数量远低于教师模型。通过模仿教师模型的预测,学生模型逐渐学会在相同任务上的推理能力。
图中右侧的小型神经网络即为学生模型。
3. 知识蒸馏的实现:
教师模型通过训练数据生成预测(Predictions),并将这些预测传递给学生模型。
学生模型不仅学习数据的真实标签(Ground Truth),还通过模仿教师模型的预测结果,捕获额外的知识(如特定类别的相似性)。
输出到目标设备:
蒸馏完成后,学生模型被部署到资源受限的设备上,如图中所示的手机或嵌入式设备。
学“软标签”而不是“硬标签”
以图片识别任务为例,来对比一下传统的训练与知识蒸馏的训练:
| 传统训练(硬标签) | 知识蒸馏(软标签) | |
| 输入 | 一张图片 | 一张图片 |
| 标签 | 猫(猫100%) | 教师模型的输出(猫90%,狗5%,...) |
| 学习目标 | 模型直接学习“非黑即白”的答案。 | 学生模型的输出尽可能的接近老师模型。 |
为什么需要知识蒸馏?
- 降低计算成本:大模型(如 DeepSeek、GPT-4)通常计算量巨大,不适合部署到移动设备或边缘设备上。
- 加速推理:较小的模型可以更快地推理,减少延迟。
- 减少内存占用:适用于资源受限的环境,如嵌入式设备或低功耗服务器。
知识蒸馏的核心思想是:学生模型不仅仅学习教师模型的硬标签(one-hot labels),更重要的是学习教师模型输出的概率分布,从而获得更丰富的表示能力。
2. KL 散度的数学原理
2.1 KL 散度公式
在知识蒸馏过程中,我们通常使用Kullback-Leibler 散度(KL Divergence) 来衡量两个概率分布(教师模型和学生模型)之间的差异。

2.2 直观理解
KL 散度可以理解为如果用分布 Q 来近似分布 P,会损失多少信息。
- 当 KL 散度为 0,表示两个分布完全相同。
- KL 散度不是对称的,即
3. DeepSeek 中的 KL 散度应用
DeepSeek 作为一个强大的开源大语言模型(LLM),在模型蒸馏时广泛使用了 KL 散度。例如,在训练较小版本的 DeepSeek 时,研究人员采用了温度标度(Temperature Scaling) 来调整教师模型的输出,使其更适合学生模型学习。
教师模型的 softmax 输出使用温度参数 TT 进行调整:

当 T 增大时,softmax 输出的概率分布变得更平滑,从而让学生模型更容易学习教师模型的知识。
在 DeepSeek 的蒸馏过程中,常见的损失函数是加权组合:
![]()
其中:
- 第一项是 KL 散度损失,使得学生模型的输出接近教师模型。
- 第二项是交叉熵损失,确保学生模型仍然学习真实标签。
- λ是一个超参数,控制两者的平衡。
4. 代码示例:用 Keras 进行知识蒸馏
下面我们用 TensorFlow/Keras 训练一个简单的学生模型,让它学习一个教师模型的知识。
4.1 定义教师模型
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# 构建一个简单的教师模型
teacher_model = keras.Sequential([
layers.Dense(128, activation="relu", input_shape=(784,)),
layers.Dense(10, activation="softmax")
])
4.2 训练教师模型
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train, x_test = x_train.reshape(-1, 784) / 255.0, x_test.reshape(-1, 784) / 255.0
y_train, y_test = keras.utils.to_categorical(y_train, 10), keras.utils.to_categorical(y_test, 10)
teacher_model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"])
teacher_model.fit(x_train, y_train, epochs=5, batch_size=32, validation_data=(x_test, y_test))
4.3 让教师模型生成 soft labels
temperature = 5.0
def soft_targets(logits):
return tf.nn.softmax(logits / temperature)
y_teacher = soft_targets(teacher_model.predict(x_train))
4.4 训练学生模型
student_model = keras.Sequential([
layers.Dense(64, activation="relu", input_shape=(784,)),
layers.Dense(10, activation="softmax")
])
student_model.compile(
optimizer="adam",
loss=tf.keras.losses.KLDivergence(), # 使用 KL 散度
metrics=["accuracy"]
)
student_model.fit(x_train, y_teacher, epochs=5, batch_size=32, validation_data=(x_test, y_test))5. 真实应用场景
5.1 轻量级大模型
- DistilBERT:使用 BERT 作为教师模型进行蒸馏,训练更小的 Transformer。
- TinyBERT:针对任务优化蒸馏,提高学生模型的表现。
- DeepSeek-Chat 小模型:使用 KL 散度训练高效版本,提高推理速度。
5.2 知识蒸馏的优势
- 可以训练更小的模型,适用于移动端、嵌入式设备。
- 学生模型比直接训练的模型泛化性更强,能更好地模仿教师模型。
- 结合
KL 散度 + 交叉熵可以提升训练效果。
结论
KL 散度损失是知识蒸馏的核心,它让学生模型学习教师模型的概率分布,从而获得更好的表现。DeepSeek 这样的 LLM 在蒸馏过程中广泛使用 KL 散度,使得较小模型也能高效推理。希望本文能帮助你理解 KL 散度在知识蒸馏中的应用!
其它
代码示例一,
假设我们有两个概率分布 p(真实分布)和 q(预测分布),我们使用 KLDivergence 计算它们之间的 KL 散度损失。
import tensorflow as tf
import numpy as np
# 定义 KLDivergence 损失函数
kl_loss = tf.keras.losses.KLDivergence()
# 真实分布 p (标签)
p = np.array([0.1, 0.4, 0.5], dtype=np.float32)
# 预测分布 q
q = np.array([0.2, 0.3, 0.5], dtype=np.float32)
# 计算 KL 散度损失
loss_value = kl_loss(p, q)
print(f'KL Divergence Loss: {loss_value.numpy()}')
代码示例二,
一个完整的 Keras 代码示例,展示了如何在分类任务中使用 KLDivLoss 作为损失函数。这个示例使用一个简单的神经网络对 手写数字 MNIST 数据集 进行分类,并使用 KLDivLoss 计算真实分布和模型预测分布之间的散度。
import tensorflow as tf
from tensorflow import keras
from keras import layers
import numpy as np
# 加载 MNIST 数据集
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
# 归一化数据到 [0,1] 之间
x_train = x_train.astype("float32") / 255.0
x_test = x_test.astype("float32") / 255.0
# 将标签转换为概率分布 (one-hot 编码)
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
# 构建一个简单的神经网络模型
model = keras.Sequential([
layers.Flatten(input_shape=(28, 28)),
layers.Dense(128, activation="relu"),
layers.Dense(10, activation="softmax") # 输出层用 softmax 归一化
])
# 编译模型,使用 KLDivLoss 作为损失函数
model.compile(optimizer="adam",
loss=tf.keras.losses.KLDivergence(),
metrics=["accuracy"])
# 训练模型
model.fit(x_train, y_train, epochs=5, batch_size=32, validation_data=(x_test, y_test))
# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test)
print(f"Test Accuracy: {test_acc:.4f}")


















 1476
1476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











