



传统的RNN等模型的序列特性导致训练时不能并行化,而transformer模型使用的ATTENTION机制可以在训练时并行化。
结构
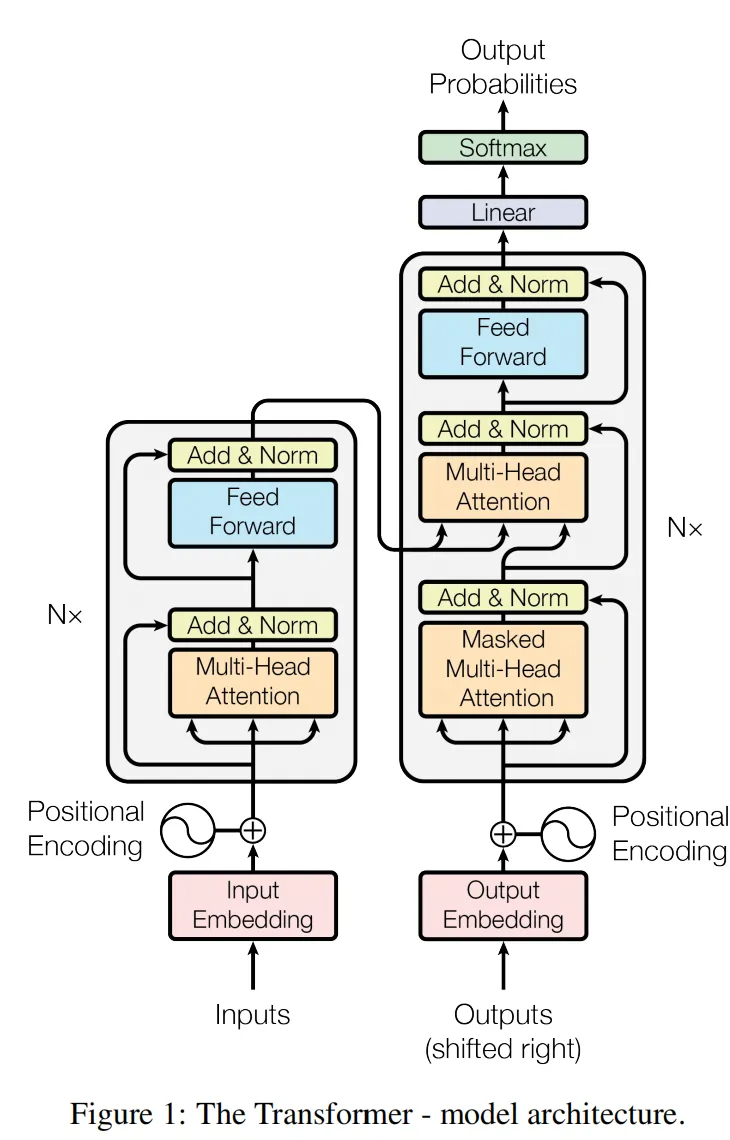
编码器重复了N次,解码器重复了N次
编码器由attention层和逐点全连接前馈层两部分组成,解码器由两个不同的attention层和逐点全连接前馈层组成。这些层都有一个残差连接和归一化过程。
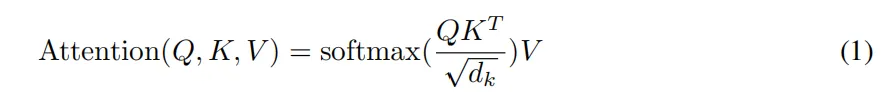
attention: query 匹配 key,根据key得到最匹配的value
self-attention:输入的source和输出的target相同,即内部元素之间发生的attention机制
为什么公式中除以根号dk?
- 防止分子值太大,导致softmax 上溢出
- 使分子的结果满足期望为0,方差为1的分布
为什么像公式中那样计算?
分子反映了两个向量在方向上的相似度,结果越大越相似
文中使用了缩放点积注意力,另外还有一种加性注意力,相比之下,缩放点积注意力在实际运用中更快并且更节省空间。
多头注意力指的是将keys,values和queries矩阵切分为h份,然后同时执行注意力机制,最后再拼起来。
在模型中,多头注意力有三个不同的应用,第一种,queries来自之前的解码层,keys和values来自于解码层的输出。第二种,自注意力机制,所有的keys,values 和 queries来自同一个地方。第三种,掩码自注意力机制,每一个位置可以访问这个位置及之前所有的位置。
除了注意力机制外,编码器和解码器中的每一层都包括一个全连接前馈神经网络,对每一个位置分别应用。它接收自注意力层捕捉的全局依赖,通过非线性变换优化局部特征,最终输出兼具全局依赖和精细表达的特征向量,为后续的分类、生成等任务提供高质量的特征输入。
包括两个步骤:先维度扩展,将每个位置的低维特征映射到更高维度的空间,为后续捕捉细粒度提供足够容量;然后使用激活函数,引入非线性;然后维度压缩,确保与后续残差连接的维度匹配,同时保留关键特征。
举个例子,假设输入序列为“猫吃鱼”(`Seq Length=3`),每个词对应一个 512 维向量(`D_model=512`):FFN 会对“猫”的 512 维向量、“吃”的 512 维向量、“鱼”的 512 维向量**分别执行“Linear1→ReLU→Linear2”**;三个位置的运算使用**同一套权重(W₁、W₂)和偏置(b₁、b₂)**,但运算过程互不干扰(无跨位置的信息传递);跨位置的依赖关系(如“猫”是“吃”的主语、“鱼”是“吃”的宾语)由自注意力层提前捕捉,FFN 仅负责优化每个词自身的特征表达。
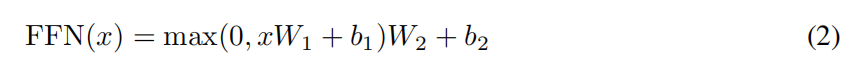
转变input tokens和output tokens的嵌入层和转变解码器输出的pre-softmax线性层的权重是相同的,这样做可以减少参数量,提升训练效率和泛化能力。
另外,在嵌入层,每个权重都乘以根号dmodel,主要原因是:
1. 位置编码取值范围-1--1,原始词嵌入向量的方差约为1/根号dm(Xavier初始化)缩放后两者相加融合时贡献均衡
2. 缩放后嵌入层输出的范数和后续网络层的输入分布对齐,避免梯度爆炸或消失
3. 适配参数共享机制
文章中使用了正余弦位置编码,好处有两个,一个是这个可以捕捉相对位置关系,另一个是正余弦位置编码具有长度外推性。
使用自注意力机制有三个原因,和其他常用模型相比:1.每一层的计算复杂性,2.并行性,3.网络中的长距离依赖

n:序列长度
d:隐藏状态维度
k:卷积核大小
r:限制性自注意力中的局部窗口大小
self-attention
complexity per layer:自注意力机制中,每个位置需要和其他位置计算注意力分数,得到注意力矩阵后,涉及向量点积,所以总计算量是n^2d
sequential operations:自注意力机制完全并行化,无需按顺序处理,因此顺序操作数为常数
maximum path length:任意两个位置之间可以直接通过注意力权重建立连接,全局依赖关系可以立即建模
recurrent
complexity per layer:由于RNN逐个处理序列中的元素,每次计算d^2的权重矩阵,共n个时间步
sequential operations:无法并行化,顺序操作数正比于序列长度
maximum path length:第一个位置到最后一个位置需要n-1步
convolutional
complexity per layer:使用大小为k的卷积核滑过序列,每个位置应用卷积核时,涉及kd^2的矩阵运算,共n个输出位置,总复杂度是knd^2。
sequential operations:卷积可以并行化
maximum path length:卷积本身是局部操作,信息只能逐步扩散。每层扩展感受野k倍,m层后感受野是k^m,要覆盖整个序列n,![]()
self-attention(restricted)
complexity per layer:只考虑每个位置周围r个邻居,每个位置只与r个位置计算注意力
sequential operations:虽然是局部注意力,但是每个位置的注意力计算仍然独立
maximum path length:信息每次最多传播r个位置,从第一个位置传到最后一个位置,至少需要n/r步
参考资料:
Attention Is All You Need

















 831
831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









