



embedding: 将文字映射到高维连续空间中,相似的文字有更靠近的向量表征。
现有方法的缺陷:一般,embedding模型通过对比学习来训练,负例的质量对于模型表现非常关键。之前的研究提出了很多难负样本挖掘策略,这些策略都只在预处理阶段使用,限制了模型处理复杂多变的训练数据的能力。
conan-embedding的特点:1. 在训练过程中挖掘难负样本,使得模型可以动态适应变化的训练数据。2.使用跨-GPU平衡损失来平衡不同任务的负样本数量,提高训练的有效性。3. LLM中的提示词-回答对可以被用做训练数据,进一步提高了embedding 模型的性能。
训练工作流:多阶段训练方法,将多阶段分为预训练和微调两阶段。
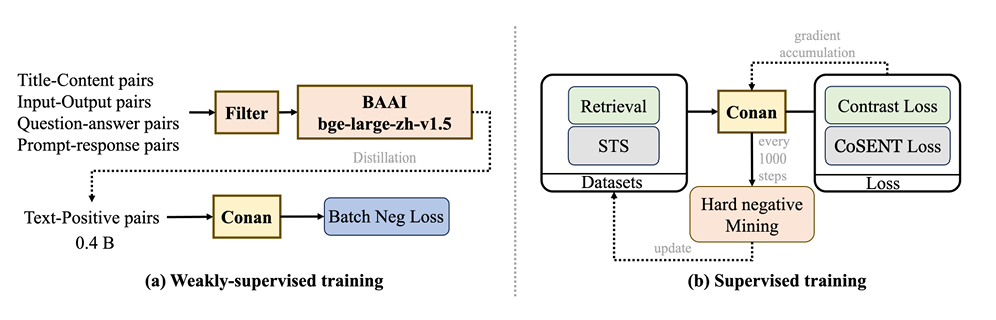 如a图,在预训练阶段,首先使用标准数据过滤方法(Internlm2 technical report. arXiv preprint arXiv:2403.17297, 2024.),然后使用bge-large-zh-v1.5对数据进行评分,如果分数低于0.4就丢弃。为了有效的使用预训练数据,在每个mini-batch中,除了目标样本的正例外,其他的所有样本都被视为负例。
如a图,在预训练阶段,首先使用标准数据过滤方法(Internlm2 technical report. arXiv preprint arXiv:2403.17297, 2024.),然后使用bge-large-zh-v1.5对数据进行评分,如果分数低于0.4就丢弃。为了有效的使用预训练数据,在每个mini-batch中,除了目标样本的正例外,其他的所有样本都被视为负例。
In-Batch Negative InfoNCE Loss:
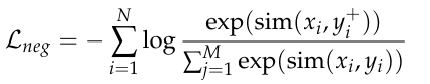
- xi: 第 i 个输入样本(例如一段文本、图像等)。
- yi+: xi 的正样本(positive sample),即与 xi 相关或语义一致的样本(如同一句子的不同增强版本、对应的查询/文档对等)。
- yj: 除了正样本之外的第 j 个负样本(negative samples)。总共有 M 个候选样本。
- sim(a,b): 表示两个向量之间的相似度,通常是 余弦相似度 或 点积。
- N: 批次中样本的数量(batch size)。
- M: 候选样本总数(通常包含一个正样本 + 多个负样本)。
如b图,在监督微调阶段,执行了分任务的微调。首先,将任务分成两个类别,检索和STS(语义文本相似度)。检索任务包括query,正样本和负样本,使用InfoNCE Loss。STS任务指的是区别两个文本的相似度,损失函数是CoSENT loss。
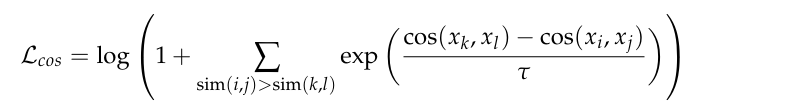
如果正样本的相似度远大于负样本的相似度,那么括号内的指数项就会趋近于 0,整个 Loss 就会趋近于0,说明模型已经学得很好了。反之,如果负样本相似度很高,Loss 就会很大,迫使模型去调整参数。
注意,在预训练阶段和监督微调阶段中的检索任务都使用了InfoNCE Loss,区别在于Pre-train 阶段是“通识教育”,解决“能不能看懂人话”的问题;而 Supervised Fine-tuning 检索任务阶段是“特种兵集训”,解决“能不能在一堆坏答案里精准挑出好答案”的问题。
1. 负样本(Negative Samples)的来源与难度
这是两个阶段最本质的区别,直接决定了模型能力的上限。
Pre-train(预训练)直接把当前训练批次(Batch)里其他样本的答案当成负样本。
Supervised Fine-tuning(监督微调):引入了动态难负例挖掘(Dynamic Hard Negative Mining)。模型不再满足于区分“毫不相关”的文本,而是专门去找那些和问题很像、但其实是错的样本(Hard Negatives)。2. 训练数据的构成与质量
Pre-train(预训练):虽然也会用 BGE 模型过滤掉极低质量的数据(如得分低于 0.4 的),但整体偏向于“广撒网”,保留数据的多样性。
Supervised Fine-tuning(监督微调):数据精且专,它会引入跨语言检索数据等特定场景的数据,并且通过动态挖掘机制,确保数据集里始终包含对当前模型来说最具挑战性的样本。
3. 损失函数的配合与微调目标
虽然核心都是 InfoNCE,但它们在模型学习中扮演的角色不同。
Pre-train(预训练):
目标:主要目标是对齐。让模型学会把“查询(Query)”和它对应的“答案(Passage)”在向量空间里拉近,同时推开批次里的其他随机文本。
作用:建立一个通用的语义空间,让同类或相关的文本距离相近。Supervised Fine-tuning(监督微调):
目标:主要目标是排序(Ranking)。它不仅要拉近正样本,还要通过高质量的难负样本,精确地调整向量空间的分布,使得模型在实际检索时,能把最相关的文档排在最前面。
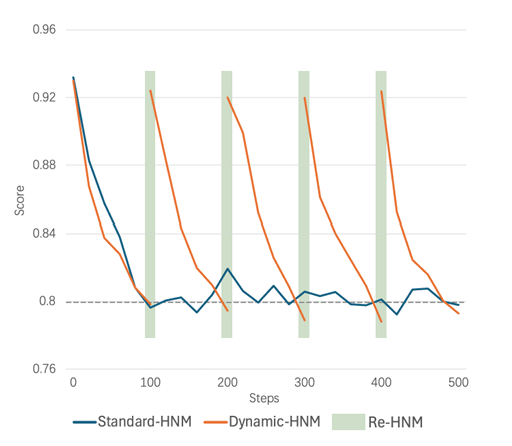
动态难负样本挖掘
对于每个数据点,记录当前难负样本相对于query的平均得分,每一百轮,如果分数*1.15小于原始分数并且分值低于0.8,这个负样本就不再被认为是难的,并会被剔除,然后开始新一轮的难负样本挖掘。
跨GPU批次平衡损失(CBB)
存在的问题:sequential random task training
在嵌入模型(Embedding Model)训练中,由于搜索空间(Search Space)的不匹配导致训练过程出现振荡(Oscillation)的现象。
简单来说,“振荡”在这里指的是模型的性能(如损失函数 Loss)在训练过程中忽高忽低,不稳定,无法平滑地收敛到一个最优值。
产生这种振荡的核心原因可以归纳为以下两点:
1. 局部与全局的“错位” (The Mismatch)
这是最根本的原因。在每一次迭代(训练一步)中,模型并不是在审视整个数据世界的“全局搜索空间”,而是在一个受限的“单次迭代搜索空间”内进行优化。单次迭代搜索空间(Optimized in a single iteration):通常指一个小批量数据(Mini-batch)。由于计算资源的限制,我们无法每次用所有数据(全局)来更新模型,只能用一小部分数据(比如几百或几千个样本)来估算梯度并更新参数。
全局搜索空间(Global search space): 指的是整个训练数据集的完整分布。为什么会出问题?
单次迭代所看到的“局部风景”(Mini-batch的数据分布)可能与整个“大世界”(全局数据分布)不一致。
* 例如,某一个 Mini-batch 中可能恰好包含了很多难样本,或者某一类特定的样本。模型在这一轮迭代中会拼命去拟合这些样本,导致参数剧烈变动。
* 但在下一个 Mini-batch 中,数据分布可能又变了。模型发现刚才的调整“过头了”,于是又得往回调整。这种“走一步、看一眼局部、大调整、发现不对、再大调整”的循环,就导致了参数在寻找最优解的过程中来回“摇摆”,也就是产生了振荡。
2. 梯度估计的噪声 (Noisy Gradient Estimation)
由于上述的“错位”,单次迭代计算出的梯度(Gradient)只能算是对全局真实梯度的一个有噪声的估计。不稳定性:如果每个 Mini-batch 的数据差异很大,计算出的梯度方向就会忽左忽右,缺乏一致性。
震荡路径:想象一下你在浓雾中下山(寻找损失函数的最低点)。如果你每次只能看清脚底下很小的一块地方,你很容易根据脚下这块地的坡度做出错误的转向,导致你走的路径是锯齿状的(振荡),而不是一条平滑的直线直达谷底。总结
Oscillation(振荡)产生的原因是:训练时使用的局部数据(Mini-batch)分布与全局数据分布存在差异,导致模型在每次迭代中对参数的更新方向不一致,从而在收敛过程中产生来回摇摆、不稳定的训练轨迹。
解决方法:在检索任务中,为了使用更多的难样本,我们确保gpu0, gpu1, gpu2, gpu3有不同的负样本的同时,分享相同的queries和正样本。每个gpu计算了相应的loss之后,汇总到gpu1中。对于STS任务,gpu4运行STS任务并计算损失。最终,所有的结果都汇总到CBB损失中。
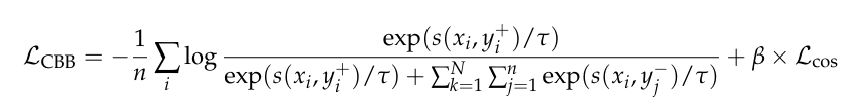
第一部分是对比损失,目的是让正样本对的相似度尽可能高,负样本对的相似度尽可能低。
第二部分是额外添加的余弦一致性损失,目标是让正样本对的余弦相似度接近1,从而提升嵌入质量。
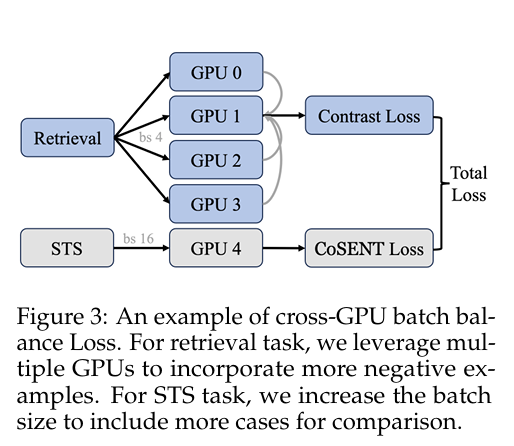
为什么retrieval四张卡,STS只用一张卡?
1. 数据规模与 Batch Size 的需求不同
RETRIEVAL(检索)任务: 通常涉及海量的负采样(Negative Sampling)。为了模拟真实的检索场景(从成千上万个文档中找答案),你需要非常大的 Batch Size 来包含足够多的负样本。单卡显存根本放不下这么大的 Batch,所以必须用 4 卡甚至更多,通过“跨 GPU Batch”来拼出一个超大批次。
STS(句子相似度)任务: 通常是计算两个句子之间的相似度(Siamese Network 或 Cross-Encoder 结构)。它的数据集相对较小(例如,一次只计算几百或几千对句子的相似度)。单张 GPU 的显存足以容纳一个效果很好的 Batch Size,没有“放不下”的压力,因此没必要为了扩充显存而上多卡。
2. 计算模式的差异(Pairwise vs Pointwise)
STS 的计算开销: STS 往往需要计算句子对之间的深层交互(Interaction),这在计算上非常昂贵。如果你强行把 STS 的 Batch Size 扩大 4 倍(为了喂饱 4 张卡),计算量会呈平方级增长,导致显存溢出(OOM)。
多卡反而受限: 在 STS 中,为了使用 4 张卡,你不得不把 Batch Size 切得很碎(例如每张卡只处理很小的 batch),这会导致 GPU 利用率极低,甚至因为多卡通信的开销(All-Reduce)而拖慢整体训练速度。单卡处理一个适中的 Batch Size 往往是效率最高的。
3. 梯度噪声的“副作用”有时是好事
RETRIEVAL 需要平滑: 检索任务通常需要非常稳定的梯度,因为负样本很多,噪声大,所以需要大 Batch 来平均掉噪声。
STS 需要噪声: STS 任务的数据集相对固定,模型容易过拟合。单卡训练产生的“小批次梯度噪声”实际上具有正则化(Regularization)的效果,有助于 STS 模型在小数据集上泛化得更好。
4. 性价比与工程复杂度
成本考量: 训练 4 张 GPU 的成本是单卡的 4 倍。
边际效应递减: 对于 STS 这种成熟的小模型微调任务,用 4 卡训练通常并不会带来精度上的显著提升(Accuracy Gain),反而增加了分布式训练的调试难度(比如死锁、通信故障)。
结论: 既然单卡能跑得动,且效果和 4 卡差不多,为了省钱和省心,大家都会选择单卡训练 STS。
参考资料
Conan-embedding: General Text Embedding with More and Better Negative Samples

















 878
878

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









