







 论文介绍了一种新的半监督学习方法FixMatch,通过弱增强的伪标签和强增强的真实标签结合,实现简单而准确的模型训练。该方法利用一致性正则化提高模型鲁棒性,对比其他复杂方法,FixMatch在多种数据集上表现出色,有望推动机器学习的民主化应用。
论文介绍了一种新的半监督学习方法FixMatch,通过弱增强的伪标签和强增强的真实标签结合,实现简单而准确的模型训练。该方法利用一致性正则化提高模型鲁棒性,对比其他复杂方法,FixMatch在多种数据集上表现出色,有望推动机器学习的民主化应用。
https://arxiv.org/ftp/arxiv/papers/2001/2001.07685.pdf
引言
这篇论文提出了一种名为"FixMatch"的半监督学习方法,该方法主要思想就是使用弱增强后未标记图像作为伪标签,再用强增强后同一图像作为训练样本,从而利用少量标注样本获得更好分类结果. 具体来说:1. FixMatch首先使用模型在弱增强后未标记图像上得到预测结果作为伪标签,然后再用强增强后同一图像预测结果作为真实标签; 2. 然后使用这两个标签计算一个新损失函数,既考虑到标注损失也考虑到伪标签误差; 3. 最后使用这个新损失函数进行模型训练即可完成整个过程.
重要要名词解释:
1." 半监督学习":指利用少量已知类别标注数据(如部分标注样本)加上大量未标记但已知类别分布信息(如大量无标识样本)来训练机器学习模型,以获得比纯有标记样本更好分类效果;
2."弱增强",指只做轻微变换比如随机水平翻转等;
3."强增强",指做大幅度变换比如随机裁剪或旋转等;
4."伪标签",指使用弱增强后未标记图片预测出可能对应某一类别概率最大的那个类别作为一个虚拟"假"标签来代替完全未知类别;
5."FixMatch",即保证预测输出与真正特征匹配程度很高才能被接受作真标".
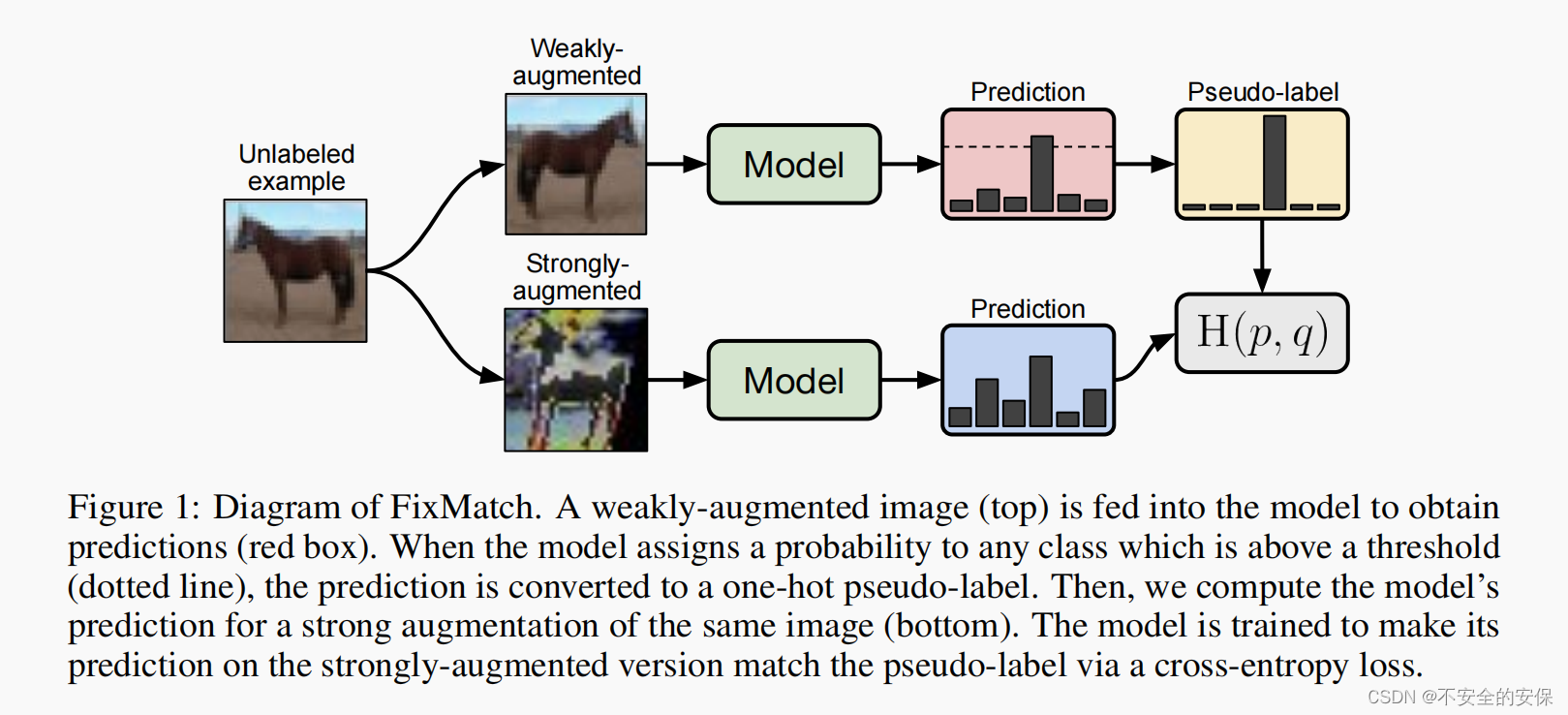
一、概要
打破了最近最先进的方法的趋势,这些方法结合了越来越复杂的机制[4,54,3],并产生了一种更简单,但也更准确的方法。我们的算法 FixMatch 使用一致性正则化和伪标记来生成人工标签。
深度神经网络已成为计算机视觉应用的事实模型。它们的成功部分归因于它们的可扩展性,即经验观察表明,在更大的数据集上训练它们会产生更好的性能 ,但是人工标注成本过高。一类流行的SSL方法可以看作是为未标记的图像生成人工标签,并训练模型在将未标记的图像作为输入时预测人工标签。我们打破了最近最先进的方法的趋势,这些方法结合了越来越复杂的机制,并产生了一种更简单,但也更准确的方法。我们的算法 FixMatch 使用一致性正则化和伪标记来生成人工标签。
二、FixMatch
"FixMatch"算法是一种半监督学习算法,它将两种主流的半监督学习方法:一致性正则化和伪标记进行了有机结合。 具体来说,它利用弱增强后未标记图像作为伪标签,再用强增强后同一图像预测结果作为真实标签进行训练。 这两个步骤分别对应着一致性正则化和伪标记技术的应用。
其中,"一致性正则化"是一种利用模型对同一输入数据产生不同输出时保持一致性的技术,用于提高模型鲁棒性和泛化性能。
假设你有一个照相机,每次拍照时都会把照片拍摄得很清晰。 但是如果你在不同位置或角度重新拍摄同一张照片,由于光线和环境因素的影响,可能会出现模糊或失真的情况。 这就像模型对同一输入数据输出结果存在不一致性一样。
"一致性正则化"就是为了防止这种不一致性发生而设计的一种技术。 它要求模型在不同条件下对同样输入产生相似结果,从而提高其鲁棒性和泛化性能。 比如,如果相机在不同位置拍摄同样物体照片时,需要确保照片清晰度和色彩还原程度保持一致,这就是一种一致性约束的体现。
而"伪标记"是指利用弱增强后未标记图像预测结果作为虚拟标签来代替完全未知类别进行训练的方法。 两者在FixMatch中结合使用可以充分发挥各自优势来获得更好的分类效果。
此外,"FixMatch"还采取了单独使用弱增强和强增强策略执行一致性正则化,这也是其独特之处之一。 通过这种方式可以避免强增强对模型性能产生负面影响,同时保证了一致性约束的有效实施,又充分利用了伪标签提升分类性能的潜力。 这就像我们使用相机从不同角度再次拍下同一物体照片时保持清晰度一致一样,"FixMatch"将两个看似矛盾但又互补的方法结合起来取得了更好效果。 总之,"FixMatch"将两种主流半监督学习方法巧妙地结合起来形成新体系,并在实现过程中采取了一些创新措施来进一步提升其效果。
三、相关工作
-
介绍了半监督学习的背景和意义,以及现有半监督学习方法面临的挑战。
-
概述了当前主流半监督学习方法,如UDA、RemixMatch等,并分析了它们之间的异同。
-
详细描述了FixMatch算法的设计思路和关键步骤,并给出了实现细节及实验结果。
-
通过对比实验分析比较不同半监督学习方法在不同数据集上的性能差异,证明FixMatch在多项任务上都取得最优表现。
-
提出了如何将其他半监督技术如Augmentation Anchoring、Distribution Alignment等结合到FixMatch中进一步提高性能。
-
总结本文工作并展望未来可能研究方向和应用场景。 所以,"相关工作部分"主要从理论和实践两个层面系统地梳理和解析了当前半监督学习领域中一些重要工作及其关系,为后续深入研究提供参考
四、实验
-
介绍了使用的基准数据集,如CIFAR10、CIFAR100、SVHN和ImageNet等,以及相应的数据预处理方法和训练设置。
-
详细描述了本文提出FixMatch算法在各个基准数据集上与主流半监督学习方法进行性能比较的实验结果。 通过比较不同模型配置下的错误率变化趋势,证明了FixMatch在多项任务上取得最优结果。
-
进行了广泛的超参数调优实验分析,探究对模型性能影响最大因素如学习率、优化器类型等。 并给出了最佳超参数组合推荐值供参考。
-
对比分析了不同数据增强方式如弱增强和强增强对FixMatch性能提升效果的差异,证明采用单独弱增强执行一致性正则化效果更佳。
-
进行了不同伪标签阈值设定对性能影响的实验分析;同时还对比分析了不同优化器类型对FixMatch效果影响等细节问题。
-
提供了完整实验代码及运行细节以供读者复现验证结果;同时也给出结论总结及未来研究方向建议,为进一步探索该方向提供参考
五、消融实验
主要对FixMatch算法的各个关键组成部分进行了广泛实验分析,以探究其在性能提升中的重要性。
-
对不同伪标签阈值设定下FixMatch算法性能的影响进行了实验对比,发现选择合适的阈值对提升模型性能至关重要。
-
对比分析了使用不同优化器类型(如SGD、Adam等)和学习率衰减方式(如cosine衰减等)对FixMatch效果的影响,证明优化器选择也是一个关键因素。
-
通过调整不同超参数(如学习速率比率、正则化系数等)来评估其对FixMatch性能提升的贡献。 结果显示一些参数设置需要谨慎调整才能获得最佳效果。
-
比较了在使用弱增强和强增强数据增强方式时,一致性正则化策略在保证模型鲁棒性与提高分类精度之间的平衡关系,证明单独使用弱增强执行一致性约束可以达到更好效果。
-
对比分析了不同数据增强方式(如Cutout等)对数据多样性与模型性能之间关系,进一步说明选择合适数据增强方式也是影响半监督学习效果的一个关键因素。
六、结论
-
相较于现在发展迅速的一些SSL方法、我们提出的FixMatch不以日益复杂的学习算法为代价,相反训练目标只需几行代码就能编写。(简洁性拉满)
-
发现某些设计选择很重要(但往往被低估)——最重要的是重量衰减和优化器的选择。
广泛影响
-
帮助机器学习民主化,使使用范围更广
-
例如,获得医学扫描通常比花钱请专家医生来标记每张图像要便宜得多。
-
-
更先进的半监督学习技术可能会允许更高级的监控
-
例如,我们的一次性分类的功效可能允许从几张图像中更准确地识别人员。
-

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









