







重点总结:
- 主要结合了伪标签和一致正则化(两种数据增强的方式实现)方法
- 利用更少的带标签数据,实现了更高的准确度。
下面具体说一下关于FixMatch具体实施细节:
先来介绍一下本篇论文中数据增强。数据增强的主要思路:在未标记的图像上进行弱增强从而生成伪标签,同时也在未标记的图像上进行强增强进行预测。具体使用到的方法的解释如下:
1.弱增强:包括对图像的翻转和平移两种策略。
2.强增强:主要应用RandAugment或CTAugment,然后应用CutOut增强
-
CutOut方法:

这种增强的方式会随机的删除图像中正方形的部分,并且用灰色或者黑色去填充。 -
RandAugment
这个方法的主要思想是首先有一个14种可能的增强的列表,以及一系列可能的增幅。比如下面图中表示的这样。
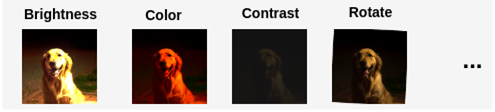
然后再从这个列表中随机选出N个增强,假设在里面选出2种,比如是Color和Rotate;再选择一个随机的幅度M,这个M的取值范围是从1-10,假设选择一个幅度为5,这意味着百分比表示的幅度为50%,因为最大可能的M是10,所以百分比=5/10=50%。所以对Color和Rotate操作都予以50%的权重去做数据增强。比如Color变换最大值是0.9,Rotate变换的最大值是30°。这样每个操作的变化可以表示为:

- CTAugment
假设有一组18种可能的变换,类似于RandAugment。但是这里的幅度值被设置为bin,每个bin被分配一个权重,最初的时候,bin被初始化为1。现在从这个变换集合中以相等的概率随机选择两个变换,他们的序列形成了一条管道,这个操作也类似于RandAugment,(就是刚刚说到的那个Color和Rotate那种)。对于每个变换来说,根据归一化的权重随机选择一个幅值bin。对带有标记的样本通过这两个变换得到了增强之后的结果,并传递给模型进行预测。根据模型预测值与实际标签的接近程度,更新这些变换的bin权重。因此它学会选择具有较高的机会来预测正确的标签的模型,从而完成这个增强的效果。
根据上面的描述,可以发现CTAugment与RandAugment不同,CTAugment 可以在训练过程中动态学习每个变换的幅度。
有了上面基础之后,下面说一下整体的一个流程:

如上图所示。使用交叉熵损失在标注的图像上训练了监督模型。对于每个未标记的图像,使用弱增强(翻转、平移)和强增强(RandAugment、CTAugment)两种方式获得图像,经过处理之后。将弱增强的图像传递到模型中,会得到关于种类的预测值。将置信度最高的类别概率与阈值进行比较,如果高于阈值,那么就把这个弱增强图像分类的结果最为ground truth的标签(伪标签)。然后,将经过强增强的图像传到模型中,得到种类的预测值,使用交叉熵损失,将此概率分布于ground truth伪标签进行比较。两种损失组合起来进行模型的更新。















 1463
1463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









