







 本文深入探讨时间序列分析,从数学特征、平稳性概念出发,讲解AR、MA、ARMA和ARIMA模型,包括模型选择、诊断与预测。通过理论介绍和实例分析,帮助理解时间序列建模流程。
本文深入探讨时间序列分析,从数学特征、平稳性概念出发,讲解AR、MA、ARMA和ARIMA模型,包括模型选择、诊断与预测。通过理论介绍和实例分析,帮助理解时间序列建模流程。
CSDN:http://blog.csdn.net/kicilove/article/
github:https://github.com/zhaohuicici?tab=repositories
前言
一说起时间序列大家并不会陌生。每时刻的甲醛浓度变化、每日股票闭盘价格、共享单车每日租车数等等都可以看做一系列时间点上的观测,在一系列时间点上观测获取的数据也就是我们俗称的时间序列数据。本文主要介绍常见的AR、MA、ARMA、ARIMA平稳时间序列模型以及时间序列常见的数学特征以及时间序列建模的流程,此篇相对来说偏于理论、偏于公式,下篇会给出一个关于时间序列的Python实例。
下面我们通过两幅图来简单看看时间序列的样子。
图一是2000-2016年美国消费者信心指数;
图二是某地在某段时间pm2.5的浓度变化情况;
图三是1949年到1960年某地某航空公司每月乘客数。
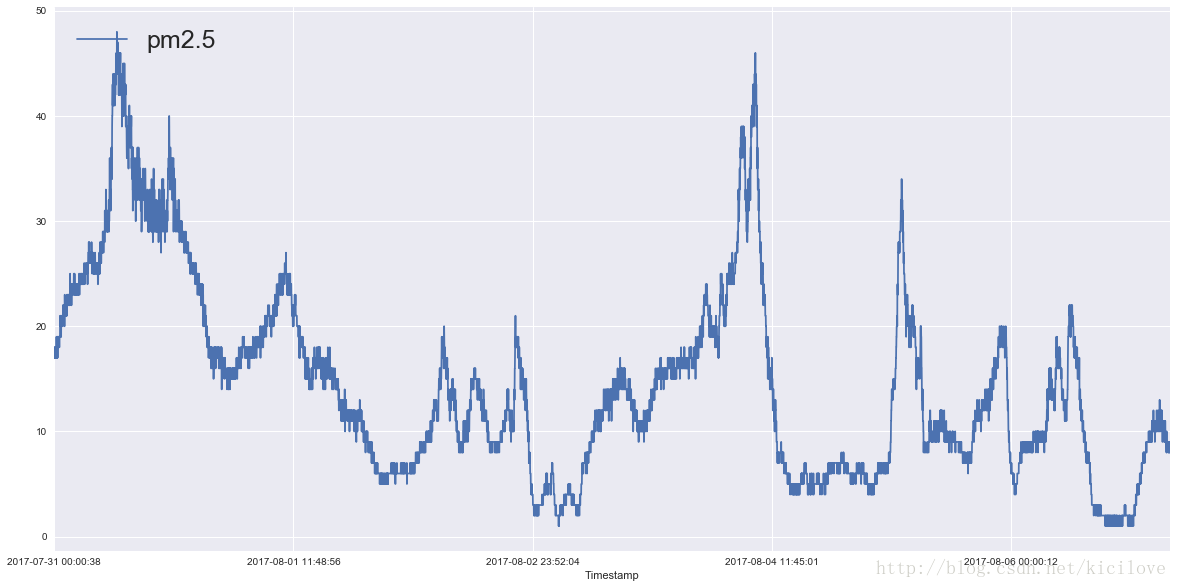
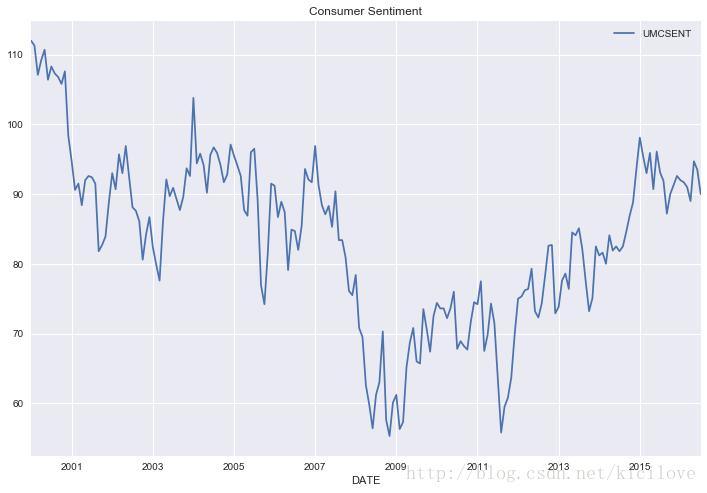
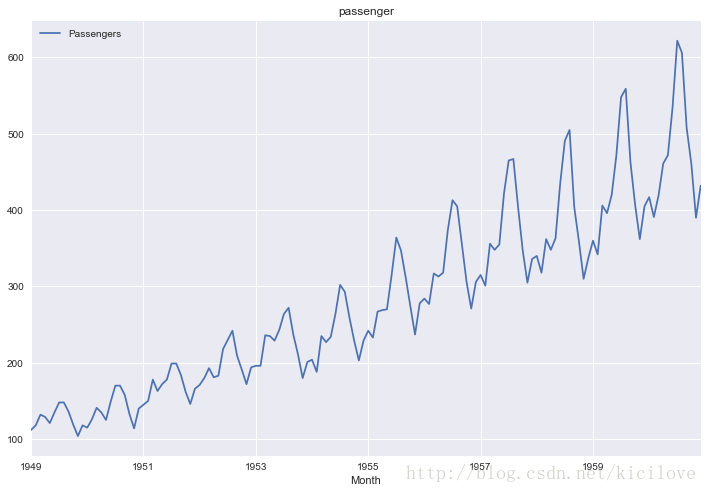
可以看出来时间序列数据的形状真的是千奇百怪,但是不管怎么样,要想预测好数据还得见招拆招,根据不同的数据特点做不同的检验,选择不同的模型,确定不同的参数。
1. 数学特征
在介绍模型之前,先看看时间序列数据有啥部件需要我们知晓,下面介绍时间序列的数学特征。像一般的随机变量一样,时间序列也有随机变量序列,也有相应的均值、自协方差、方差、期望、相关系数等,只不过这里我们要加上函数俩字,也就是均值函数、自协方差函数、方差函数、期望函数、相关系数函数,之所以加上函数二字,是因为时间序列对应的这些数学特征变成了时间的函数。来看看它们具体的数学表达式(公式是一个一个敲上去的,如果有手误请指正):
1.1 一般随机变量的数学特征
1.1.1 期望
对于连续型随机变量 X ,有概率密度函数
为 X 的数学期望。
对于离散型的随机变量
1.1.2 方差
设 X 施一个随机变量,若
E[X−E(X)]2 存在,则称 E[X−E(X)] 为 X 的方差,记为D(X) 或 Var(X) ,即 D(X)=Var(x)=E[X−E(X)]2 ;D(X)−−−−−√ 称为 X 的标准差;
若
X 是离散型随机变量,则 D(X)=∑∞k=1[xk−E(X)]2pk ;若 X 是连续型随机变量,则
D(X)=∫∞−∞[x−E(X)]2f(x)dx
补充:
方差的推导关系:
D(X)
=E[X−E(X)]2
=EX2−2XE(X)+[E(X)]2
=E(X2)−2E(X)E(X)+[E(X)]2
=E
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2907
2907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









