






为音频和视频生成对应字幕的方法有很多,之前介绍过本地模型 openai-whisper ,虽然需要下载模型配置复杂环境,但全免费无限制。
今天介绍个更简单的方式,豆包提供的在线“音视频字幕生成”功能。相比 openai-whisper 简单许多,速度也更快,有20个小时的免费额度。
首先登陆注册火山引擎
登陆地址 console.volcengine.com/auth/login
若无账号,当然需要先注册了,还需要实名认证哦。
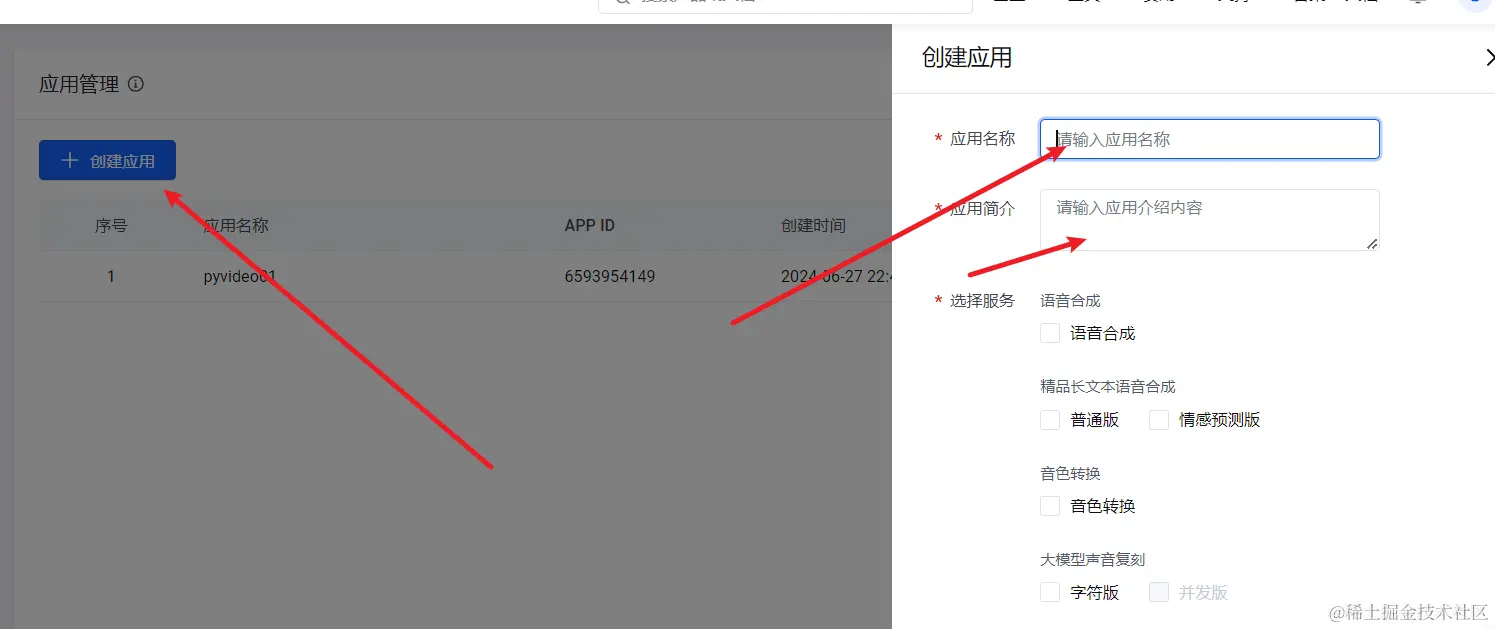
创建一个应用
上步登陆并实名认证后,打开“语音技术”模块,直达地址 console.volcengine.com/speech/app
点击 “创建应用”,名字填写英文,描述随意,重要的是下方的一堆复选框,拉到底部,选中“音视频字幕生成”,这是必须的,其他均可以不选。
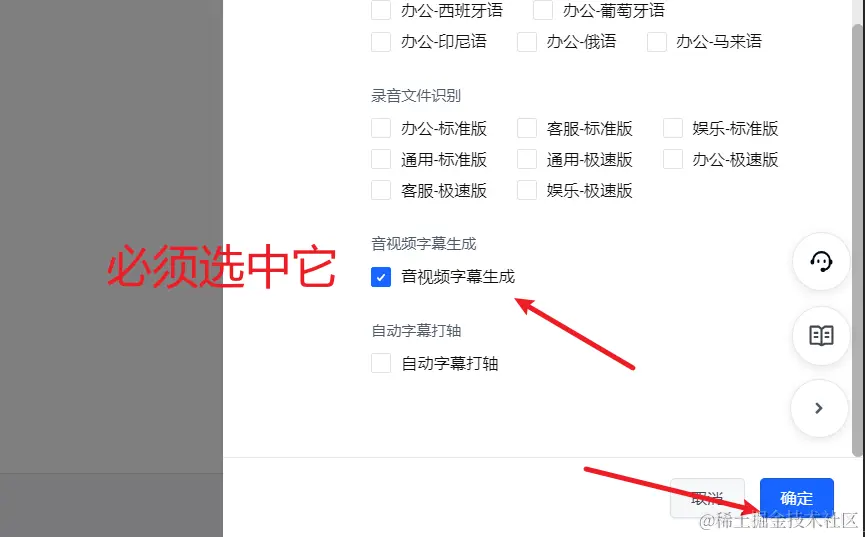
点击确定,继续下一步“获取 APP ID 和 Access Token”
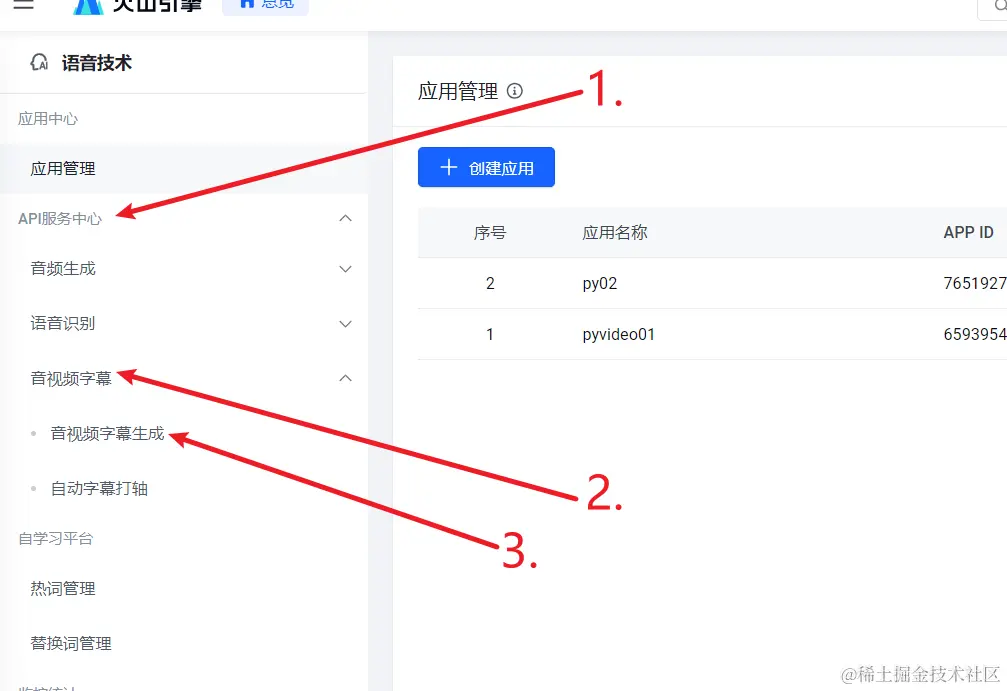
获取 Access Token / 开通正式版
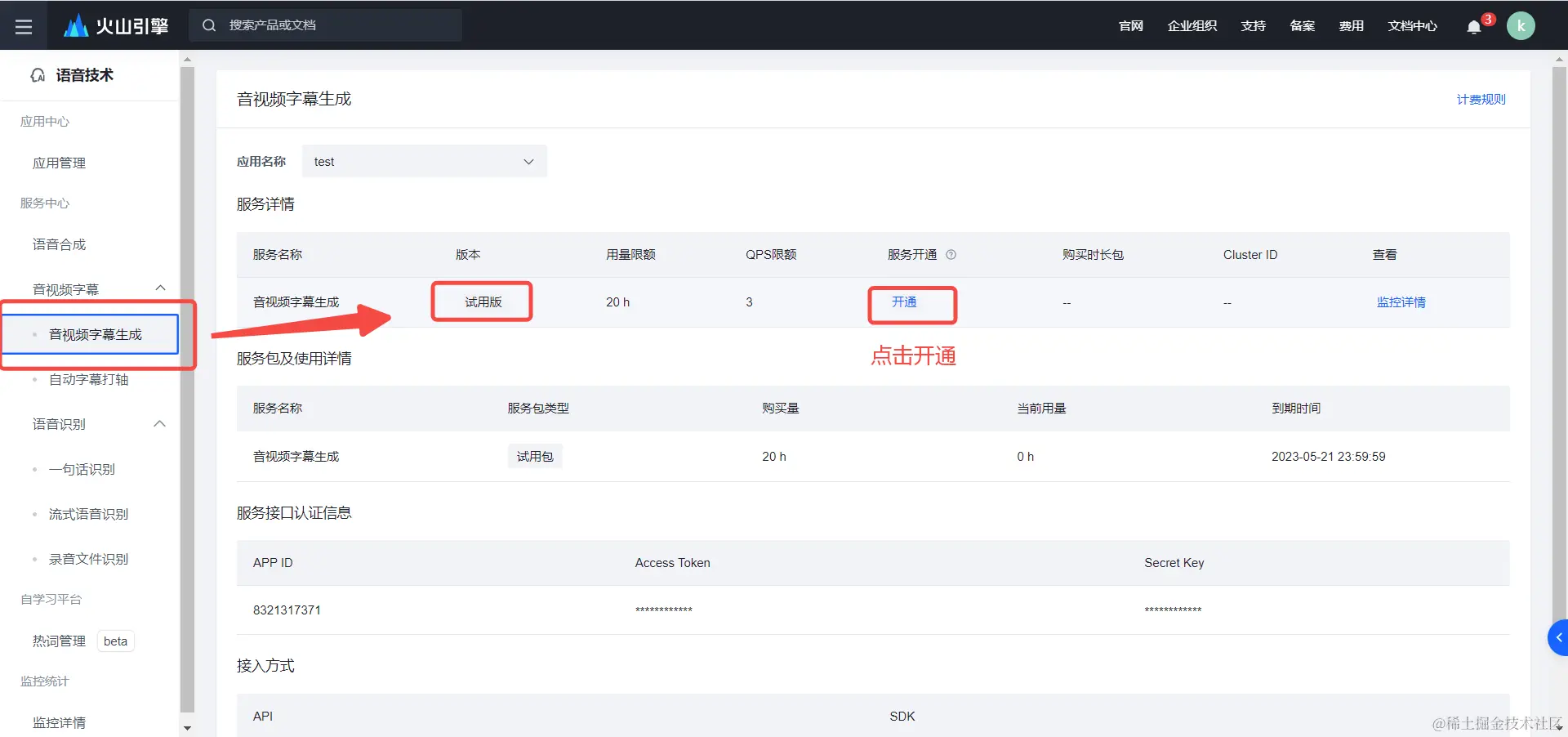
创建应用后,去应用服务开通的地方复制 Access Token,按下图所示进入,点击左侧“API服务中心”–“音视频字幕”–“音视频字幕生成” 或 直接打开 console.volcengine.com/speech/serv…
在右侧,你将能看到已创建的所有应用,选择你要使用的那个
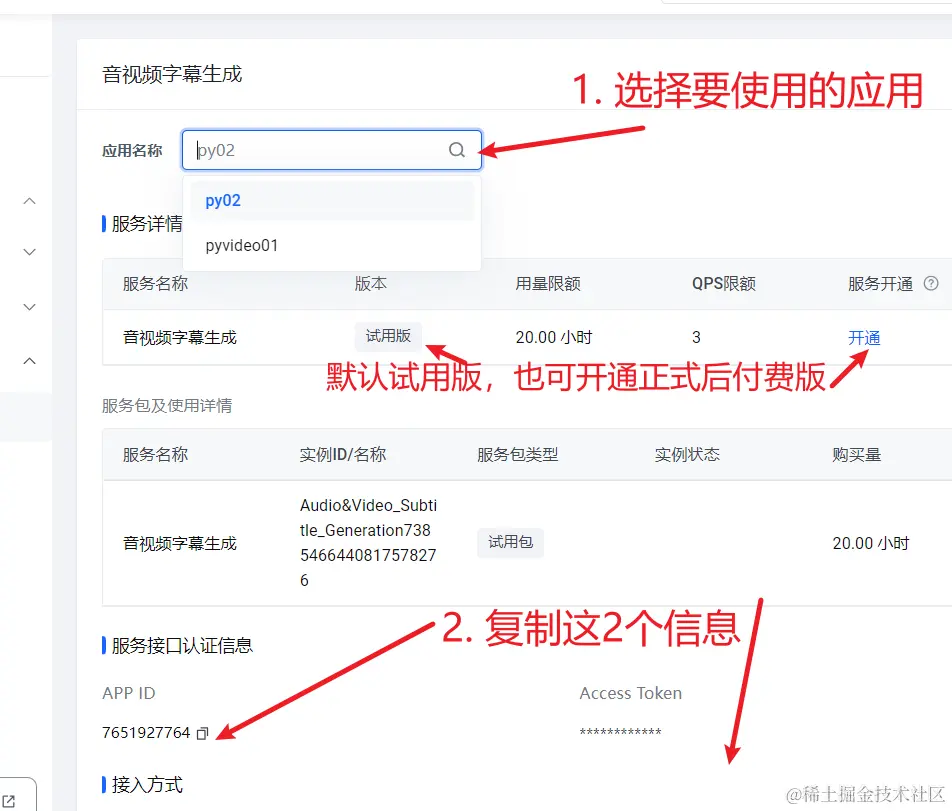

默认创建的是试用版,有20个小时的免费时长。
从上方应用名称里选择你要使用的的应用,拉到页面底部找到“服务接口认证信息”处,复制 APP ID 和 Access Token, 代码中将用到这2个信息。
你也可以点击开通,转为后付费正式版
安装python3.10和ffmpeg
如果不会安装,请查看教程 juejin.cn/post/738391…
开始接入识别
新建一个空白文件夹,在其内创建 start.py 文件, 输入代码
import time
import subprocess
import requests
import re
from datetime import timedelta
# 固定
base_url = 'https://openspeech.bytedance.com/api/v1/vc'
appid = "填写刚才记录的 APP ID"
access_token = "填写刚成记录的 Access Token"
# 音视频发声语言
language = 'zh-CN'
#待识别的文件
file_url = r'./60.mp4'
注意2个参数,一是 language 代表语言代码,中文是 zh-CN,其他语言对应填写

file_url 参数是你需要识别的音频或视频文件,为方便起见,可将这些文件复制到 start.py 所在目录,然后填写带后缀的文件名称,如果在其他目录下,请填写盘符开头的完整文件路径,直到文件后缀。
提取出音轨
需要确保设备已安装了ffmpeg并配置了环境变量,如果没有,请查看 juejin.cn/post/738391…
以下代码确保将任何格式的音视频均转为 1通道24k的wav音频文件。
subprocess.run(["ffmpeg","-y",'-i',file_url,"-ac","1","-ar","24000","./chuli.wav"])
chuli.wav 就是从视频中提取出来的将要发送给豆包进行识别的音轨文件。
接着以二进制形式提交音轨数据
with open("./chuli.wav",'rb') as f:
audio=f.read()
response = requests.post(
'{base_url}/submit'.format(base_url=base_url),
params=dict(
appid=appid,
language=language,
use_itn='True',
caption_type='speech',
max_lines=1,
words_per_line=15,
),
data=audio,
headers={
'Content-Type': 'audio/wav',
'Authorization': 'Bearer; {}'.format(access_token)
}
)
这里要注意,以 rb 直接读取音频为 Byte 数据,然后传递给 data参数,headers参数里Content-Type需设为 audio/wav。
max_lines=1 表示每条字幕最多只能包含一行文字,如果 改为 max_lines=2,即代表最多允许2行。 words_per_line=15 表示一行最多15个字符,如果英文的话可以改成 50 更合适。
params 里还可提供更多参数,用于更细化的控制识别,具体可参考豆包文档

如果没出错的话,提交后将返回
{ "code": "0", "message": "Success", "id": "fc5aa03e-6ae4-46a3-b8cf-1910a44e0d8a" }
id是任务编号,据此再去查询识别任务是否完成,如果任务已完成,不管失败还是成功,都会返回json数据
job_id = response.json()['id']
response = requests.get(
'{base_url}/query'.format(base_url=base_url),
params=dict(
appid=appid,
id=job_id,
),
headers={
'Authorization': 'Bearer; {}'.format(access_token)
}
)
注意 params里的参数,默认是阻塞,即直到任务有了结果才返回,可以通过添加参数 blocking=0 改为非阻塞,即查询任务未完成也立即返回
如果不幸失败了,返回信息中 code 是错误代码,message 是错误原因。
"id": "d22cca84-8c8a-4d15-aa2c-ac550518d5ae", "code": 错误码, "message": "错误原因",
识别成功返回结果中将存到 utterances 列表,遍历列表中每个元素的text、start_time、end_time 字段,可获取识别结果,当然还可以进一步使用 words 字段,获取每个字符的时间戳
[
{
"text": "如果您没有其他需要举报的话这边就先挂断了",
"start_time": 0,
"end_time": 3197,
"words": [
{
"text": "如",
"start_time": 0,
"end_time": 208
}....
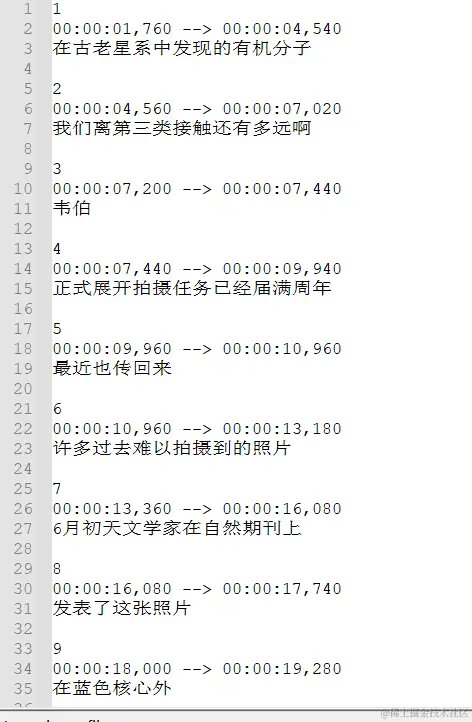
将结果转为 srt 格式的字幕
srts=[]
for i,it in enumerate(response.json()['utterances']):
srts.append(f'{i+1}\n{ms_to_time_string(ms=it["start_time"])} --> {ms_to_time_string(ms=it["end_time"])}\n{it["text"]}\n\n')
with open(f'./chuli.srt','w',encoding='utf-8') as f:
f.write("".join(srts))
打开 chuli.srt 字幕,效果还不错。
完整代码
import time
import subprocess
import requests
import re
import os
from datetime import timedelta
base_url = 'https://openspeech.bytedance.com/api/v1/vc'
# 应用 APP ID
appid = "填写应用APP ID"
# Access_Token
access_token = "填写Access Token"
# 音频视频中说话语言
language = 'zh-CN'
# 音视频文件地址
file_url = r'./60.mp4'
# 将毫秒转为字幕格式时间值
def ms_to_time_string(*, ms=0, seconds=None):
# 计算小时、分钟、秒和毫秒
if seconds is None:
td = timedelta(milliseconds=ms)
else:
td = timedelta(seconds=seconds)
hours, remainder = divmod(td.seconds, 3600)
minutes, seconds = divmod(remainder, 60)
milliseconds = td.microseconds // 1000
time_string = f"{str(hours).zfill(2)}:{str(minutes).zfill(2)}:{str(seconds).zfill(2)},{str(milliseconds).zfill(3)}"
return time_string
# 文件的基本名字
basename=os.path.basename(file_url)
# 提取音频
subprocess.run(["ffmpeg","-y",'-i',file_url,"-ac","1","-ar","24000",basename+".wav"])
with open(basename+".wav",'rb') as f:
audio=f.read()
response = requests.post(
'{base_url}/submit'.format(base_url=base_url),
params=dict(
appid=appid,
language=language,
use_itn='True',
caption_type='speech',
max_lines=1,#每条字幕只允许一行文字
words_per_line=15,#每行文字最多15个字符
),
data=audio,#二进制音频
headers={
'Content-Type': 'audio/wav',
'Authorization': 'Bearer; {}'.format(access_token)
}
)
print('submit response = {}'.format(response.text))
assert(response.status_code == 200)
assert(response.json()['message'] == 'Success')
# 得到任务id,继续执行查询任务状态
job_id = response.json()['id']
response = requests.get(
'{base_url}/query'.format(base_url=base_url),
params=dict(
appid=appid,
id=job_id,
),
headers={
'Authorization': 'Bearer; {}'.format(access_token)
}
)
assert(response.status_code == 200)
result=response.json()
assert(result['code'] == 0)
# 保存 srt 字幕
srts=[]
for i,it in enumerate(result['utterances']):
srt=f'{i+1}\n{ms_to_time_string(it["start_time"])} --> {it["end_time"]}\n{it["text"]}\n\n'
srts.append(srt)
print(srt)
with open(f'./{basename}.srt','w',encoding='utf-8') as f:
f.write("".join(srts))
代码保存为 start.py, 填写好自己的APP ID 和 Access Token,以及音视频地址,然后打开 cmd 窗口(文件夹地址栏输入cmd回车),执行 python start.py,没意外的情况下,就能看到输出以及当前目录下创建的 srt 字幕文件了
srt 格式的字幕文件可用记事本打开

















 2649
2649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









