






linear list
概览 : 以顺序表和链表为基础,从而实现栈,队列,串
一对一
基本操作
- 对于个体:
Insert Delete find(Locate/Get)
-
对于整体:
Initial Clear Destroyread(Traverse/Length/Empty) -
操作时注意: 下标越界,长度不够,内存的分配与失败
-
每个操作的基本组成 : 检查,操作,(返回以及长度调整)
检查
变量名 : i:index ; L:list ; e:element ; p:positon
i
检查i是否合法
if ((i <= 0 ) || (i > length)) return ERROR;
L
L以指针形式传入,并检查是否为空,为空则返回错误(内存分配失败或者只有头节点)
if ((L == NULL) || (L->next = NULL)) return ERROR;
e
e在插入时表示插入的数,再删除时来接受删除的数(删除时以指针传入)
p
再分配内存后检查是否分配成功,在遍历,定位,尾插时更新,作为一个标尺
包含对象
长度 数据 指针
- 预定义,提高代码可读性
#define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0
typedef int ElemType;//方便后期适配其他类型
顺序表(SequenceList)
用于对数表之类的存储,存储密度高
常用操作
- 结构
#define MAXSIZE 20//动态储存较短的数据
typedef struct sqlist {
ElemType data[MAXSIZE];
int length;
}Sqlist;
//在传参时使用指针
- 插入/删除时,将元素移动
下面代码只是关键部分,完整的还需要检查index是否合法,插入后L.length的改变,以及返回成功与否
//插入时,后面先移动
for (int j = L.length; j >= i; j--)
L.data[j] = L.data[j-1];
L.data[i-1] = e;
//删除时,前面覆盖
e = L.data[i-1];
for (int j = i; j < L.length; j++)
L.data[j-1] = L.data[j];
- 动态分配顺序表( 连接两个数组)
*先将原指针备份,再分配新大小的指针给原指针,将原数据拷贝到新指针,释放原指针
对于顺序表还需要调整长度
void IncreaseSize(SqList &L, int len)
{
//备份 + 创建新的区域
ElemType *p = L.data;
L.data = (ElemType *)malloc((L.MaxSize+len) * sizeof(ElemType));
// 将数据复制到新区域
for (int i = 0; i < L.length; i++)
L.data[i] = p[i];
L.MaxSize = L.MaxSize + len;
// 释放原来的内存空间
free(p);
}
链表 (LinkList)
空间利用率低,存储弹性强
操作 : 分配内存(检查+赋值),定位指针(在create中就不用了,每次循环就自动定位了),改变指针指向,(释放空间)
单链表
- 声明
头节点的data可以用来存储长度
typedef struct Node{
ElemType data;
struct Node *next;
}Node, *LinkList;
typedef struct node Node;
struct node
{
ElemType data;
Node *next;
};
- 分配空间+检查
Node* alloc() {return (Node*)malloc(sizeof(Node*))}
p=alloc();
if(p==NULL)return ERROR;
- 定位到操作的位置
Node* p = L;
for(int j =0;j<i-1;j++)p=p->next;
//因为是对第i位操作所以定位到i-1位
- 改变指针指向
对于insert和delete都需要先定位p
- ListInsert
创建新节点后,改变两个指针的指向
Node * in =alloc();
in->data = e;
in->next = p->next;
p->next = in;
- ListDelete
先寄存被删节点,改变断点处指向,释放空间
Node *q = p->next;
e = q->data;
p->next = q->next;
free(q);
- ListCreateHead
新指后,前指新
for (int i = 0; i < length; i++)
{
Node* in = alloc();
if (in == NULL) return ERROR;
in->data =i;
in->next = L->next;
L->next = in;
}
- ListCreateTail
尾指新,尾更新,最后末尾添NULL
Node* p = L;
for (int i = 0; i < length; i++)
{
Node* in = alloc();
if (in == NULL) return ERROR;
in->data = i;
p->next = in;
p = in;
}
p->next = NULL;
数据也可以利用scanf进行输入
- inverse
按顺序读取每一个节点再头插
Node *Inverse(Node *L)
{
Node *p, *q;
p = L->next; //p来存储原链表
L->next = NULL; //将链表清空
while (p != NULL)
{
q = p;//q来定位每一个
p = p->next;//p的迭代
q->next = L->next;
L->next = q;
}
return L;
}
双链表
既有前驱,又有后继
- 声明
typedef struct DNode
{
ElemType data;
struct DNode *prior, *next; //前驱和后继指针
}DNode;
- 尾插
可以通过循环获取输入
DNode* Last, *p;
p = (DNode*)malloc(sizeof(DNode*));
if(p==NULL)return ERROR;
p->data = e;
Last->next = p;//双向
p->prior = Last;
p->next = NULL;
Last = p;//Last更新
- 删除
//先将p定位到i处
p->prior->next = p->next;
if(p->next)//如果是最后一个节点,规则就不一样了
p->next->prior = p->prior;
free(p);
栈(Stack)
只有一端允许插入和删除,叫做栈顶(top),另一端叫做栈底(bottom),大小固定为S(size)
后进先出(Last in First Out) LIFO结构
栈的操作: push/pop 进(入)栈/出栈 (压栈/弹栈) 只是叫法的不同 GetTop
本质是前面线性表的退化(只能对一个接口进行操作)
用途
- 函数的执行
- 表达式的求解(后缀表达式)
- 递归
顺序表实现
typedef struct Stack{
ElemType data[MAXSIZE];
int top;
}SqStack;
void InitStack(SqStack *S){ S->top = -1;}
Status Push(SqStack *S,Elem e)
{
if(S->top>=MAXSIZE-1) return ERROR;//判断栈是否已满
S->data[++(S->top)]=e;
return OK;
}
Status Pop(SqStack *S, ElemType *e){
if(S->top == -1) return false; //判断栈是否为空
*e = S->data[(S->top)--];
return OK;
}
链表实现
typedef struct Linknode{
ElemType data;
Linknode *next;
}LinkNode,*LStack;
//push/pop就跟前面的尾插/删除一样
队列(Queue)
顺序表实现
队头删除队尾插入
FIFO(First In First Out)
为了区别队空与队满,将队列最后一位不放数据
rear指向队尾的下一位空格
I n i t / D e s t r o y E n Q u e u e / D e Q u e u e G e t H e a d Init/Destroy \quad EnQueue/DeQueue \quad GetHead Init/DestroyEnQueue/DeQueueGetHead
以下直接用c++描述了,C不能传引用参数
typedef struct{
ElemType data[MaxSize];
int front, rear;
}SqQueue;
void InitQueue(SqQueue &Q){ Q.rear = Q.front = 0;}
length = (Q.rear + MAXSIZE - Q.front)%MAXSIZE;
//考虑到循环队列,以及rear处没数据
//检查:判断长度 顺序表中的length判断
if((Q.rear+1)%MaxSize == Q.front;//在入队前判断队列是否满
if(Q.rear == Q.front); //出队时判断是否为空
//定位:顺序表先天优势
//操作:入队与出队
Q.data[Q.rear] = e;
e = Q.data[Q.front];
//修改length
Q.rear = (Q.rear+1)%MaxSize;
Q.front = (Q.front+1)%MaxSize;
//返回
Q.rear的妙处
- 指向的说末尾的下一个,在入队时直接使用
- 因为指向的多一个,在处理长度是相当于默认加了1,让表达式更简洁
链表实现
typedef struct LinkNode{ //定义节点
ElemType data;
struct LinkNode *next;
};
typedef struct{ //定义队列
LinkNode *front, *rear;
}LinkQueue;
void InitQueue(LinkQueue &Q){ // 初始化时,front、rear都指向头结点
Q.front = Q.rear = (LinkNode*)malloc(sizeof(LinkNode));
Q.front -> next = NULL;
}
//入队即尾插,出队即删除结点,都比较简单,就不写了
小结
栈和列表只是规定了操作的顺序表和链表,不需要定位操作了
cpp中STL(Standard Template Library):就是链表就是顺序表
而这两种基本的也叫存储结构 顺序/链式存储
一般,我们习惯顺序表下标从0开始,链表从1开始
串(String)
以字串为使用单位的顺序表
如 : 名字储存用顺序表,聊天记录用链表
空串:任意个空格组成的串
主串 S 子串 T
Concat SubStr Replace
朴素模式匹配
作用上类似低配版find
int Index(hstring S, hstring T){
int k=1; //开始比较的位置
int i=k, j=1;
while(i<=S.length && j<=T.length){
if(S.ch[i] == T.ch[j]){
++i; ++j;
}else{
k++; i=k; j=1;
}
}
if(j>T.length)
return k;
else
return 0;
}
时间复杂度:设子串长度为m,主串长度为n
- 匹配成功的最好时间复杂度: O ( m ) O(m) O(m) 在第一个位置就匹配成功
- 匹配失败的最好时间复杂度: O ( n ) O(n) O(n) 子串的第一个和主串的每一位都不同
- 最坏时间复杂度: O ( n m ) O(nm) O(nm)
KMP
名字只是三个人名抽的第一个 可记成(看猫片)
- 原理
根据已经匹配的来得到匹配失败时该匹配的位置
- 实现
- next[j]数组
void GetNext(string t,int next[])
{
int i = 0, j = -1;
next[0] = -1;
while (i < t.length() - 1)
{
if (j == -1 || t[i] == t[j])
{
i++; j++;
next[i] = j;
}
else j = next[j];
}
}
- 利用next[j]数组进行跳跃
int Index_KMP(string S, string T)
{
int i = 0, j = 0;
int l1 = S.size(), l2 = T.size();
int* next = new int[l2];
GetNext(T, next);
while (i < l1 && j < l2)
{
if (j == -1 || S[i] == T[j])
{
i++;
j++;
}
else j = next[j];
}
return j == l2 ? i - l2 : -1;
}
KMP的平均时间复杂度为 O ( m + n ) O(m+n) O(m+n)
一个人能走的多远不在于他在顺境时能走的多快,而在于他在逆境时多久能找到曾经的自己。 —KMP
树(tree)
一对多
树(tree)=根节点(root)+子树(subtree)
度(degree):一个节点的子树个数,叶结点(leaf)(终端节点):度为0,分支节点(非终端节点):root和leaf之外的
子节点(child) 父节点(parent) 兄弟节点(sibling)同一父节点的子节点
深度(depth):节点的层数 ,从0开始
森林(forest):不相交的树的集合,实际上是图
- 抽象数据类型
AbstractDataType,ADT
基本操作
T : Tree 根节点来记录长度
对于树
Init/Destroy/Create/Clear BiTree//create时注意要把空指针域设为NULLTree Empty/Depth对于创建二叉树,可以将没有数据的位置填成^
对于节点
Root / Parent / LeftChild / RightSibling获取相应的地址,不存在则返回NULLAssign/Value/InsertChild/DeleteChild赋值/读值/增删
不是完全二叉树时,与链表的实现大差不差,只是不方便精确获取某个位置
实现方式
- 顺序表 父节点表示法
节点 = 数据 + 关系
node = data + parent 可以迅速找到父节点(将根节点下标默认为-1)(树的基本形式)
node = data + parent + 长子下标(firstchild) 可以迅速找到子节点(将长子默认为-1,用来判断叶节点)
node = data + parent + 右兄弟下标(rightsib) 可以迅速找到同级
- 顺序表+链表 孩子表示法
顺序表为主体,关系由链表表达
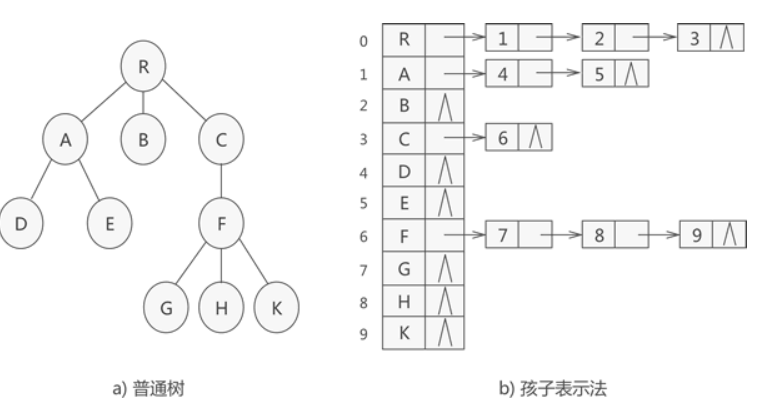
- 孩子兄弟表示法
完全用链表,二叉树最常用
二叉树
定义
每个节点的子节点数不超过2(区分左右节点)
斜树: 只有一种结点(左/右),像链表一样
满二叉树: 除了叶结点层,其他每层的其他结点都有左右子结点
二叉树一般用链表存储,如下结构体
typedef struct BiTNode
{
TElemType data;
struct BiTNode *lchild,*rchild;
}BiTNode,*BiTree;
二叉树同构:可以交换左右子树转换的树
完全二叉树
高密度,用顺序表存储
从右往左,从下往上依次去除结点的满二叉树(可以在顺序表中快速读取)
其他接近完全二叉树的可以将缺少部分填为 “^” (用来表示空的符号)
数量关系全用等比数列理解
遍历二叉树
访问 次序
树对我们来说虽然很直观,
前/中/后序是根节点的访问次序,层序遍历就顾名思义
Pre/In/PostOrderTraverse
而在代码的实现上,都是用的递归,区别不同的只有打印出现的位置
而层序遍历是通过将结点值放入一个队列之中,在父节点出队后,子节点再入队.
//前/中/后序遍历
void __OrderTraverse(BiTree T)
{
if(T==NULL) return ;//若为空,则啥也不干
//printf("%c",T->data); //前序遍历
__OrderTraverse(T->lchild);
//printf("%c",T->data); //中序遍历
__OrderTraverse(T->rchild);
//printf("%c",T->data); //后序遍历
}
//层序遍历
void LevelOrderTraverse(BiTree T){
LinkQueue Q; //准备好队列
BiTree p;
EnQueue(Q, T);
while(!IsEmpty(Q)){
DeQueue(Q, p);
visit(p);
if(p->lchild!=NULL)
EnQueue(Q, p->lchild);
if(p->rchild!=NULL)
EnQueue(Q, p->rchild);
}
}
- 中序遍历,非递归实现,利用栈来实现
其他两种遍历同理可行
void __OrderTraverse(BiTree BT)
{
BiTree T = BT;
stack S[Maxsize];
while(T||!isEmpty(S)){
while(T){
Push(S,T);
//printf("%c",T->Data);先序遍历
T=T->left;
}
if(!isEmpty(S)){
T=Pop(S);
//printf("%c",T->Data);中序遍历
T=T->right;
}
}
}
线索二叉树
在二叉树中,每个叶节点都会有两个空指针,拿满二叉树来举例,空指针的数量约为已用指针的两倍,大大浪费了空间,为了利用这个空间,出现了线索二叉树(Threaded Binary Tree)
为了区分是指针是孩子还是前驱/后继,追加tag来标记
中序遍历线索化:
对于每次递归,p指向的自己,pre指向的中序访问中访问的前一个
而所做的,将叶结点的左指针指向前一个,右指针指向后一个
如果为左斜二叉树,这样就变成双向链表了
线索二叉树提高了遍历效率,特别是中序遍历,
typedef int ElemType;
typedef enum { Link, Thread }PointerTag;
typedef struct BiThrNode
{
ElemType data;
struct BiThrNode* lchild, * rchild;
PointerTag ltag, rtag;//左右标签,上面枚举的
}BiThrNode,*BiThrTree;
BiThrNode* pre;
void Threading(BiThrTree p)
{
if (p!=NULL)
{
Threading(p->lchild);
if (!p->lchild)//将p指向pre
{
p->ltag = Thread;
p->lchild = pre;
}
if (!pre->rchild)//将pre指向p
{
pre->rtag = Thread;
pre->rchild = p;
}
pre = p;//pre更新
Threading(p->rchild);
}
}
二叉搜索树
(BST,Binary Search Tree)又称二叉排序树,因为元素按顺序存储,左子树结点值 < 根结点值 < 右子树结点值,二分查找,最大查找次数为树的深度
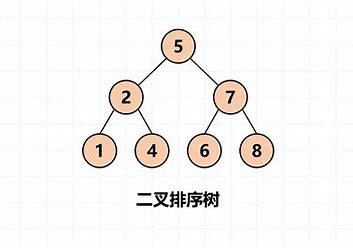
- 查找
typedef struct BSTNode{
int key;
struct BSTNode *lchild, *rchild;
}BSTNode, *BSTree;
BSTNode *BST_Search(BSTree T, int key){
while(T!=NULL && key!=T->key){
if(key < T->key) T=T->lchild;
else if(key > T->key) T=T->rchild;
else return T;
}
return NULL;
}
插入同理,先找到位置,直接挂为叶结点
对于同一集合以不同顺序给出,会生成不同的二叉搜索树,导致数据一边倒(左),查找效率就并没有提升,此时出现了平衡二叉树(右)
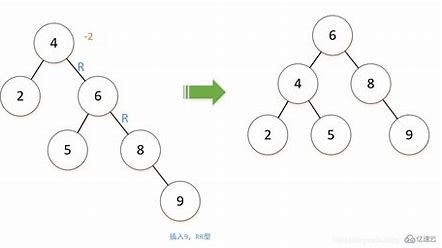
平衡二叉树
Balanced Binary Tree,又称AVL,发明者的名字
平衡因子 Balance Factor B L = h l − h r BL=h_l-h_r BL=hl−hr 左右子树的高度差不超过1
解决二叉搜索树的缺点,实现效率最大化,搜索数据的时间复杂度为 l o g 2 n log_2n log2n,远小于 n n n
插入时的平衡调整
平衡改变后的三个数,将中间值作为新的父结点,将它的子结点分给原来的父节点
如下两种调整
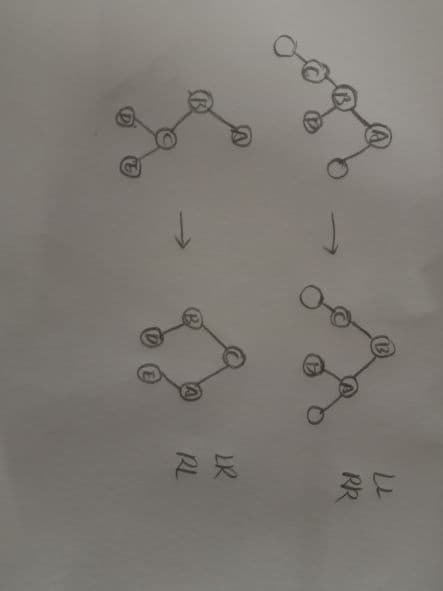
红黑树
RBT(red-black tree),解决了AVL调整时太浪费时间,牺牲一点平衡换来性能的优越
堆
即优先队列(Priority Queue),新加入的元素按照优先级分到相应优先级的队列,
用完全二叉树存储,最大堆:任何结点值是子树结点的最大值,最小堆反之,下面只说最大堆
- 插入新元素
加到完全二叉树末尾,然后与父节点比较,当新元素比父节点大时,交换值,以次类推
typedef struct heap{
ElemType Arr[MAX_SZIE+1];//顺序表存储完全二叉树
//第一个位置来存放哨兵(一个上界),用于后面插入时循环
int size,capacity;//当前使用量,总容量
}Heap;
void Insert(Heap H;Elemtype e){
if(IsFull(H))return;//先判断是否已满
int i=size+1;
Elem[i]=e;
for(;H->arr[i/2]<e;i/=2)
swap(H->arr[i],H->arr[i/2]);
}
- 删除最大元素
删除最大值(根节点)后,将最后一个元素替补根节点位置,然后与子结点比较,如果子结点较大,则交换,以此类推
插入和删除的复杂度都为 O ( l o g n ) O(logn) O(logn),
- 建立堆
-
每次将新元素插入原本的堆中,共n次,时间复杂度 n l o g n nlogn nlogn
-
先建立起完全二叉树,从最小规模的堆依次调整堆,时间复杂度 O ( n ) O(n) O(n)
哈夫曼树
最优二叉树
结点的权 : 自己设的,一般用整数表达(cpu计算整数效率更高)
结点的带权路径长度 : 路径长度*该节点的权
树的带权路径长度(Weighted Path Length of Tree,简称WPL) : 所有叶结点的带权路径长度之和
哈夫曼树 : 当有n个结点(都作叶结点,且每个节点都有各自的权值)试图构建一棵树时,当WPL最小时,则称这棵树为哈夫曼树
原则 : 权重越大越靠近根节点
构建步骤 : 每次取权最小的叶结点两个作为中间结点的子节点,并将权的和赋值给中间结点,使其与未取出的最小结点一起参与下一次选取
A-E的权为1-5
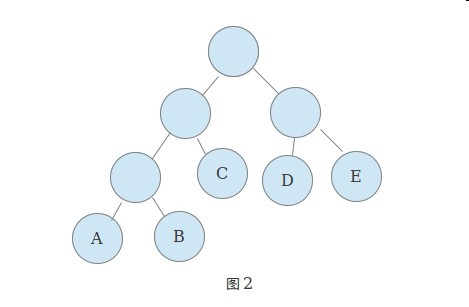
- 利用最小堆进行构建
每次取权重最小的两个进行构建,并将权重和插入最小堆中,循环此过程
HuffmanTree Huffman(MinHeap H)
{/*假设H->Size个权值已经存在H->data[]->Weight里*/
int i,num;
HuffmanTree T;//构建的哈夫曼树
BuildMinHeap( H ); //将H->data[]按权值调整为最小堆
/*此处必须将H->Size的值交给num,因为后面做DeleteMin()和 Insert()函数会改变H->Size的值*/
num = H->Size;
for(i=1; i<num; i++){ //做 H->Size-1次合并 //此处教科书有问题!原书直接为H->Size
T = NewHuffmanNode(); //建立一个新的根结点
T->Left = DeleteMin(H); //从最小堆中删除一个节点,作为新T的左子结点
T->Right = DeleteMin(H); //从最小堆中删除一个节点,作为新T的右子结点
T->Weight = T->Left->Weight+T->Right->Weight; //计算新权值
//printf("%3d 0x%x 0x%x\n",T->Weight,T->Left,T->Right);
Insert(H,T); //将新T插入到最小堆
}
T = DeleteMin(H);
return T;
}
- 利用权重构造元素组+中间数组进行构建
//huffmanCoding.c
#include <stdio.h>
#include <limits.h>
#include <string.h>
#include <stdlib.h>
#define N 6
typedef struct huffNode
{
int weight;//权重
int lchild, rchild, parent; //与一个结点相连接的其他结点的下标值
}HTNode, * HuffTree;
typedef char** HuffCode;//用来储存每个叶结点的编码
//找出数组中无父节点且权值最小的两个节点下标,分别用s1和s2保存
void select(const HuffTree& HT, int n, int& s1, int& s2);
//HT:哈夫曼树,HC:哈夫曼编码,w:构造哈夫曼树节点的权值,n:构造哈夫曼树节点的个数
void HuffmanCode(HuffTree& HT, HuffCode& HC, int* w, int n);
int main()
{
char key[N] = { '0','A','B','C','D','E' };//第0个元素保留不用
int w[N] = { 0,1,2,4,5,6 }; //第0个元素保留不用
HuffTree HT;
HuffCode HC;
HuffmanCode(HT, HC, w, N - 1);
for (int i = 1; i < N; i++)
printf("%c:%s\n", key[i], HC[i]);
printf("\n");
return 0;
}
void select(const HuffTree& HT, int n, int& s1, int& s2)
{
s1 = s2 = 0;
int min1 = INT_MAX;//最小值,INT_MAX在<limits.h>中定义的
int min2 = INT_MAX;//次小值
for (int i = 1; i <= n; ++i)
{
if (HT[i].parent == 0)
{//筛选没有父节点的最小和次小权值下标
if (HT[i].weight < min1)
{//如果比最小值小
min2 = min1;
s2 = s1;
min1 = HT[i].weight;
s1 = i;
}
else if ((HT[i].weight >= min1) && (HT[i].weight < min2))
{//如果大于等于最小值,且小于次小值
min2 = HT[i].weight;
s2 = i;
}
else;//如果大于次小值,则什么都不做
}
}
}
void HuffmanCode(HuffTree& HT, HuffCode& HC, int* w, int n)
{//1.初始化 2.构建哈夫曼树 3.获取哈夫曼编码表
//1.初始化
int s1,s2;
int m = 2 * n - 1;//n个叶结点,n-1个中间结点
HT = (HuffTree)malloc((m + 1) * sizeof(HTNode)); //0单元未使用
for (int i = 1; i <= n; i++)
HT[i] = { w[i],0,0,0 };//初始化前n个叶节点
for (int i = n + 1; i <= m; i++)
HT[i] = { 0,0,0,0 }; //初始化后n-1个中间结点
//2.构建哈夫曼树
for (int i = n + 1; i <= m; i++)
{
select(HT, i - 1, s1, s2);//w数组和新的结点构成的数组中寻找最小的两个
//将最小的两个连接到后面的中间节点上
HT[s1].parent = i;
HT[s2].parent = i;
HT[i].lchild = s1;
HT[i].rchild = s2;
HT[i].weight = HT[s1].weight + HT[s2].weight;//将子树的权的和赋给中间结点,参与下一次select
}
//3.获取哈夫曼编码表
HC = (char**)malloc((n) * sizeof(char*));//哈夫曼编码表
char* code = (char*)malloc(n * sizeof(char)); //暂存结点编码
int c, f, j;//c表示当前结点,f表示当前节点的父节点,j用于内层循环
for (int i = 1; i <= n; i++)
{
//从叶子扫描到根,判断c是f的左孩子(0)还是右孩子(1),并给上标记
for (c = i, f = HT[c].parent,j = 0; f != 0; c = HT[c].parent, f = HT[c].parent, j++)
{
if (HT[f].lchild == c) code[j] = '0';
else if (HT[f].rchild == c) code[j] = '1';
else;
}
code[j] = '\0';
HC[i] = (char*)malloc(strlen(code) * sizeof(char)+1);//需要拷贝'\0'
memcpy(HC[i], code,strlen(code)+1);
}
}
输出编码
A:000
B:100
C:10
D:01
E:11
用途 : 无损压缩
先处理文件,得出每个单位的出现频率(权重),由此构建一个字符-编码表
然后将源文件根据这张表转换为01代码
解压时也是根据这张表来读取文件
哈夫曼编码
按照频率进行编码后101010110101110110…,如何断开
设计的时候已经设计好了,因为每个码都是叶结点,则按照哈夫曼寻找到叶结点后就断开,开始解码下一个
集合
正数集合,利用父亲表示法,将所有根节点设为-1

typedef struct{
ElemType Data;
int Parent;//父节点下标
}SetType;
//查集,找到根结点
int Find(SetType S[],ElemType x){
for(int i=0;i<MaxSize && S[i].Data!=X;i++);//在集合中寻找需要的数据x
if(i>=MaxSize)return -1;//没找到
for(;S[i].Parent>=0;i=S[i].Parent);
return i;
}
//并集,将多个树的根节点指向其中一个,最好把小的树指向大树,尽可能减小树的高度
void Union(SetType S[],ElemType x1,ElemType x2){
int root1,root2;
root1=Find(S,x1);
root2=Find(S,x2);
if(root1!=root2)s[root2].Parent = root1;
}
FT
- file transfer,判断每个电脑是否已经连通,意思是把把集合连接成一个树
- 集合简化,因为是有限个集合,可以将构造两个数组(键值对),这里就分成data和parent两个数组
- 在本题中,下标即代表电脑编号,值即代表父节点
TSSN too simple sometimes naive很傻很天真
int Find(SetType S[],int x){
for(; S[x]>0; x=S[x]);
return x;
}
void Union(SetType S[],int x1,int x2){//默认不在一起
S[Find(x1)]=Find(x2);
}
缺陷: 1️⃣ 可以形成斜树,高度不断增加,就会失去树的优势2️⃣查找根节点时比较朴实
- 按秩归并
改进: Union时将矮的树依附到高的树上,将根节点原本的-1用来记录数的大小(高度或规模)
最坏情况树高为 l o g n logn logn
//高度
if(root2高度>root1高度)
s[root1]=root2;
else {
if(二者等高) s[root1]--;//因为负数表示高度
s[root2]=root1;
}
//规模
if(s[root1]>s[root2]){
s[root1]+=s[root2];
s[root2]=root1;
}else{
s[root2]+=s[root1];
s[root1]=root2;
}
- 路径压缩
左边转化为右边,因为
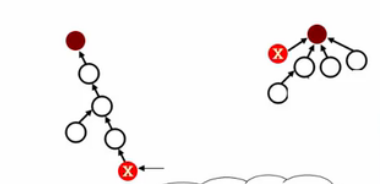
int Find(SetType S[],int x){
if(s[x]<0)return x;
else return s[x]=Find(s,s[x]);
}
图(graph)
多对多
- 图 G 由顶点集 V (vertex)和边集 E (edge)组成,记为$ G = ( V , E )$
$V = { v_1 , v_2 , … , v_n } $,用 ∣ V ∣ ∣ V ∣ ∣V∣表示图 G 中顶点的个数,也称图 G 的阶
E = ( u , v ) ∣ u ∈ V , v ∈ V E = { ( u , v ) ∣ u ∈ V , v ∈ V } E=(u,v)∣u∈V,v∈V,用 ∣ E ∣ ∣ E ∣ ∣E∣表示图 G 中边的条数。
注意:线性表可以是空表,树可以是空树,但图不可以是空,即V一定是非空集。- 无向图:边全是无向边 ,无向边记为$ ( v , w )或 (w, v)$ 点的度是依赖它的边的个数
有向图:边全是有向边(弧),弧记为 $< v,w > $,顶点v称为弧尾(tail),顶点w称为弧头(head) 以点为弧尾的弧的数目称为出度,同理,为头的叫入度- 网(network): 带权图,即每个结点都有权
- 简单图:① 不存在重复边; ② 不存在指向自己的边
- 完全图: 无向图 :任意两个点之间都存在边,共有 C n 2 C_n^2 Cn2条边, 有向图为 2 C n 2 2C_n^2 2Cn2(弧为来回两个)
- 对于图的边$ ( v , w )$ v,w互为邻接点,而边依附于邻接点,或者说边与点相关联
- 连通图: 无向图所有点之都具有路径,无向图中的具有极大顶点数的连通图子图称为连通分量(可以不包含某些边)
- 强连通图: 有向图所有点之间都存在路径,有向图中具有极大强连通图叫做强连通分量
- 连通图的生成树: 含有全部顶点(n个),去掉闭环条边(n-1条),成为树(可以有多种去法)
存储
-
邻接矩阵表示法
int Graph[maxn][maxn]; -
邻接链表表示法 对每个结点建立链表来存储它的边
vector来存点,pair来存边 vector <pair<int,int> > Graph[maxn];
链表只适合很稀疏的情况,因为一个结点需要的空间多
遍历
按照不同的顺序访问,并利用visited数组来记录结点的访问状态
时间复杂度 N为顶点,E为边
邻接表 O ( N + E ) O(N+E) O(N+E) 邻接矩阵 O ( N 2 ) O(N^2) O(N2)
深度优先遍历
DFS Depth_First_Search,类似树的先序遍历
从一个结点开始,每次都向一个方向访问,递归访问
伪代码如下
void DFS(Vertex V)
{
visited[V]=TRUE;//访问后标记
for(V的每个邻接点W)
if(!visit[W])
DFS[W];
}
广度优先遍历
BFS Breadth_First_Search,类似树的层序遍历
从一个结点开始,访问完与它相连的所有点,然后对访问了的结点递归访问,类似层序遍历
//Q为队列
void BFS(Vertex V)
{
visited[V]=TRUE;
Enqueue(V,Q);
while(!IsEmpty(Q)) {
V=Dequeue(Q);
for(V的每个邻接点W)
if(!visited[W]){
visited[W]=TRUE;
Enquene(W,Q);
}
}
}
最小生成树(贪心)
贪心算法:每一步都是当前最优解
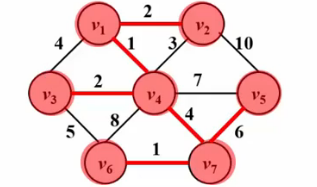
拓扑排序
Activity on Vertex AOV网络 活动在顶点上
排课的先后顺序,点天赋的前置天赋,
拓扑序 v到w存在一条路径,路径的顶点序列
拓扑排序,获得拓扑序的过程
合理拓扑序是一个有向无环图 (Directed Acyclic Graph DAG)
先构建树,再广度优先搜索,选择没有前驱顶点(入度为0)
Activity on Edge AOE 每一个边代表一个工序 网络计划图














 33万+
33万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









