









Hadoop分为三种配置模式:独立模式(standalone|local),伪分布模式(Pseudodistributed mode),完全分布式(full distributed)
说在前面
- 工作环境:VMware® Workstation 12 Pro 12.5.6 build-5528349
- linux版本:CentOS-7-x86_64-Minimal-1611.iso
- JDK版本:jdk-8u65-linux-x64.tar.gz
- Hadoop版本:hadoop-2.7.6.tar.gz
温馨提示: 配置完全分布式前请先尝试配置伪分布式,这会对配置完全分布式很有用!
准备工作
说明一:配置完全分布式需要四台主机(至少需要四台,以后可以追加),所以需要准备足够大的磁盘空间(每台虚拟机20G,100G左右差不多,因为到后面估计还要扩容)。由于在伪分布模式的时候已经配置了一台,所以其他三台就从这台克隆就可以了(注意:该文档中的完全分布式配置是基于伪分布模式配置的,所以请先配置伪分布模式!!!当然也可以自行配置,只需要在下面步骤中对伪分布模式的一些修改跳过即可)
一. 修改主机名
说明(我自己的虚拟机情况):
- 主机1ip : 192.168.32.201
//修改主机名为201
$> sudo nano /etc/hostname
//修改hosts文件
$> sudo nano /etc/hosts
127.0.0.1 localhost
192.168.32.201 s201 //主机1 IP 和 主机名 s201
192.168.32.202 s202 //主机2 IP 和 主机名 s202
192.168.33.203 s203 //主机3 IP 和 主机名 s203
192.168.32.204 s204 //主机4 IP 和 主机名 s204
- 主机1用于存放名称节点(namebnode),其他三台主机用于存放数据节点(datanode)
克隆主机
-
克隆三台主机:右键主机1——>管理——>克隆——>克隆自虚拟机当前状态——>创建完整克隆 … 完成(以此方式克隆出另外两台主机)
-
启用共享文件夹(VMware克隆出来的主机已经默认启用了共享文件夹,共享文件夹和主机1相同,如果没有启用,选择设置进行启用就可以了)
-
修改hostname和ip地址(hostanme同上)
//只需要将IPADDR改为静态ip就行
$> sudo nano /etc/sysconfig/network-scripts/ifcfg-ethxxxx
//如下,只需要将IPADDR修改为192.168.32.202,其他设置不用变
iTYPE=Ethernet
BOOTPROTO=static
DEFROUTE=yes
PEERDNS=yes
PEERROUTES=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=no
IPV6_AUTOCONF=no
IPV6_DEFROUTE=no
IPV6_PEERDNS=no
IPV6_PEERROUTES=no
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=1c4e0233-8fca-47f7-9cf5-5aa94e0319fa
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.32.202
NETMASK=255.255.255.0
GATEWAY=192.168.32.2
DNS1=8.8.8.8
DNS2=8.8.4.4
- 重启网络服务
$> service network restart
重启后 ping s201 和 ping www.baidu.com
如果成功,则ip配置没有问题,网络连接也没有问题!
配置完全分布式
上面已经准备好了四台能上网的主机,原料已经备齐,现在就可以动手配置了。
一. 配置SSH(让s201能够无密登录其他三台主机,配置两种用户:本机用户和root用户,配置方式相同)
- 删除所有主机上的 ./ssh 下的所有文件
$> rm -rf /home/centosmin0/.ssh/*
- 在s201主机上重新生成秘钥对
$>ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
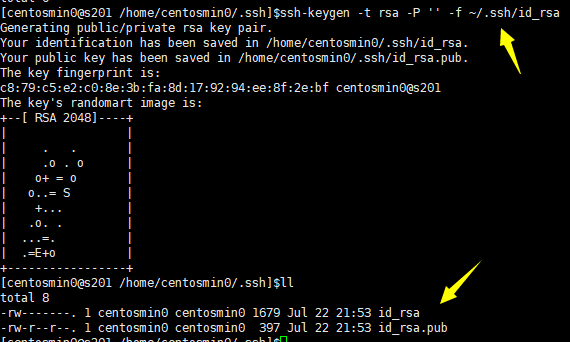
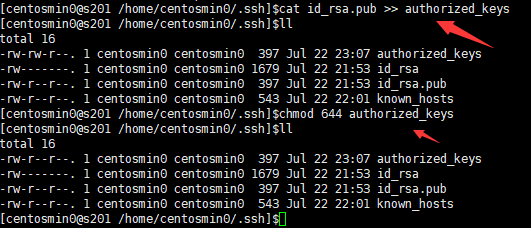
- 主机s201:追加公钥到~/.ssh/authorized_keys文件中,并修改文件的权限为644
$>cd ~/.ssh
$>cat id_rsa.pub >> authorized_keys
$>chmod 644 authorized_keys
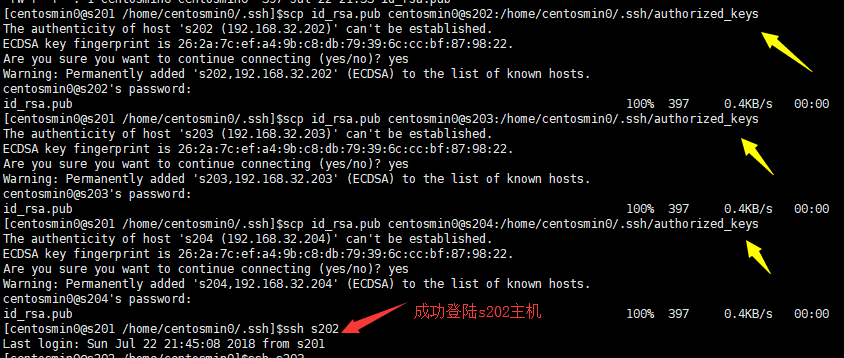
- 将s201的公钥文件id_rsa.pub远程复制到202 ~ 204主机上。并放置在/home/centos/.ssh/authorized_keys下
$>scp id_rsa.pub centosmin0@s202:/home/centosmin0/.ssh/authorized_keys
$>scp id_rsa.pub centosmin0@s203:/home/centosmin0/.ssh/authorized_keys
$>scp id_rsa.pub centosmin0@s204:/home/centosmin0/.ssh/authorized_keys
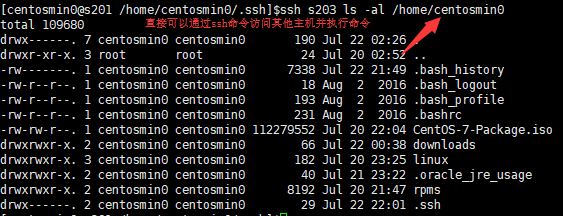
配置成功后,直接可以在主机s201上通过 ssh + 主机名 + 命令 的方式访问其他主机
二. 配置(核心)
-
修改${hadoop_home}/etc/hadoop/ 下的几个配置文件
- 修改core-site.xml配置文件(将hdfs://localhost/ 改为 hdfs://s201/)
//s201为主机名,代表存放名称节点的主机,由其管理其他数据节点 <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://s201/</value> </property> </configuration>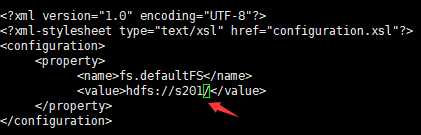
- 修改core-site.xml配置文件(将value值改为3,有三台存放数据节点的主机)
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>dfs.replication</name> <value>3</value> </property> </configuration>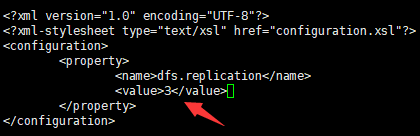
- mapred-site.xml文件不用修改,修改yarn-site.xml(将value值改为主机s201,即保存名称节点的主机)
<?xml version="1.0"?> <configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>s201</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>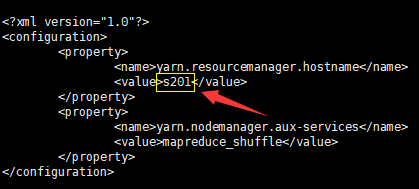
- 修改slaves文件和hadoop-env.sh文件(slaves文件里面记录的是集群里所有DataNode的主机名)
$> nano slaves 添加:s202 s203 s204 $> nano hadoop-env.sh export JAVA_HOME=/soft/jdk- 将以上所有的修改均分配到其他三台主机(s202, s203, s204)
$>cd /soft/hadoop/etc/ $>scp -r full centosmin0@s202:/soft/hadoop/etc/ $>scp -r full centosmin0@s203:/soft/hadoop/etc/ $>scp -r full centosmin0@s204:/soft/hadoop/etc/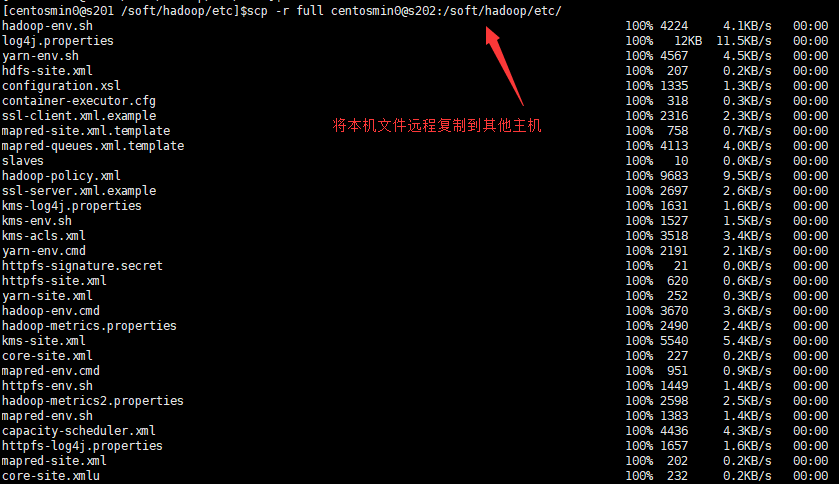
-
删除符号链接(在伪分布模式的时候创建了符号链接hadoop,让其指向了伪分布模式的配置,现在需要将其删除,如果没有配置伪分布模式,可以不用管此步骤,直接跳到下一步)
$>cd /soft/hadoop/etc
$>rm hadoop
$>ssh s202 rm /soft/hadoop/etc/hadoop
$>ssh s203 rm /soft/hadoop/etc/hadoop
$>ssh s204 rm /soft/hadoop/etc/hadoop
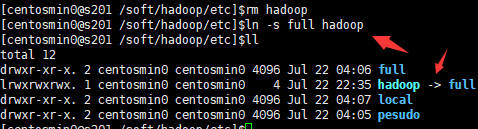
- 创建符号链接
$>cd /soft/hadoop/etc/
$>ln -s full hadoop
$>ssh s202 ln -s /soft/hadoop/etc/full /soft/hadoop/etc/hadoop
$>ssh s203 ln -s /soft/hadoop/etc/full /soft/hadoop/etc/hadoop
$>ssh s204 ln -s /soft/hadoop/etc/full /soft/hadoop/etc/hadoop

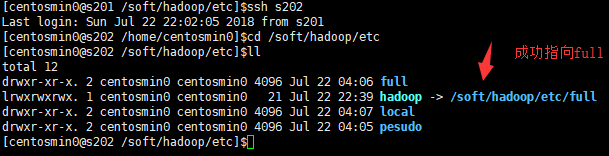
- 删除临时目录文件和hadoop日志
//删除临时目录文件
$>cd /tmp
$>rm -rf hadoop-centosmin0
$>ssh s202 rm -rf /tmp/hadoop-centosmin0
$>ssh s203 rm -rf /tmp/hadoop-centosmin0
$>ssh s204 rm -rf /tmp/hadoop-centosmin0
//删除hadoop日志
$>cd /soft/hadoop/logs
$>rm -rf *
$>ssh s202 rm -rf /soft/hadoop/logs/*
$>ssh s203 rm -rf /soft/hadoop/logs/*
$>ssh s204 rm -rf /soft/hadoop/logs/*
- 格式化文件系统
$>hadoop namenode -format
- 启动hadoop进程
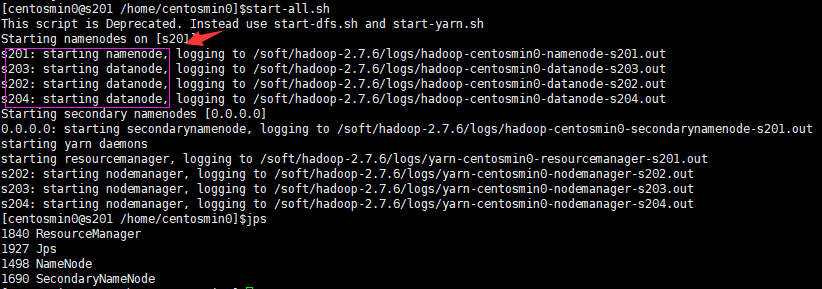
$>start-all.sh
如下图:s201成功启动了namenode进程,s202 ~ s204 成功启动了datanode进程
如下图:在web端查看(192.168.32.201:50070)
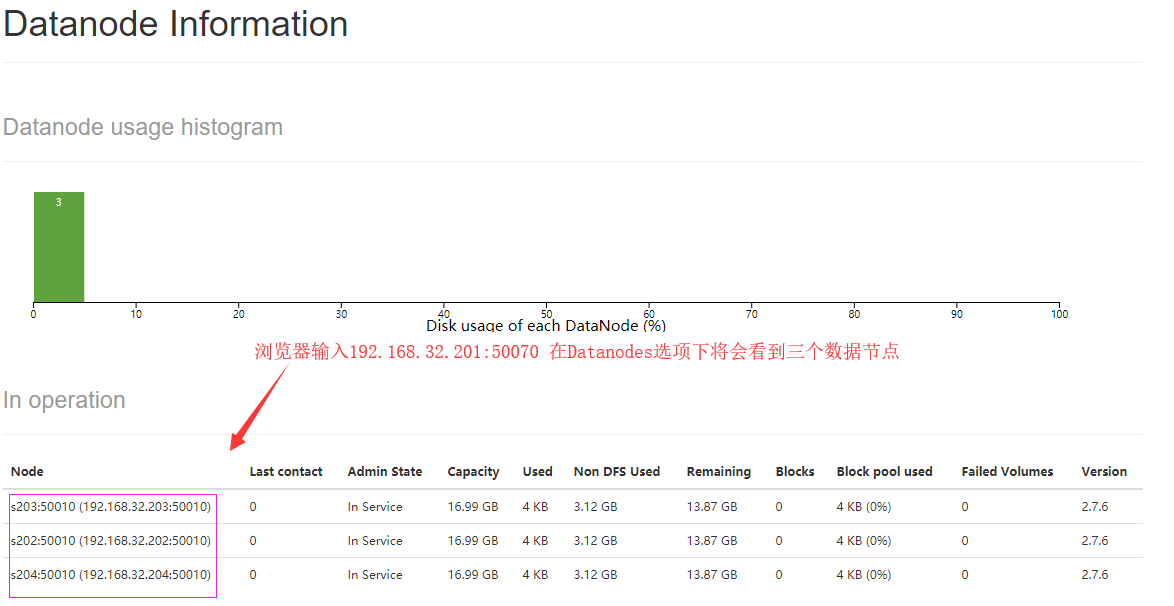
OK,大功告成!!!
调试
如果不幸出错,请按以下步骤进行调试
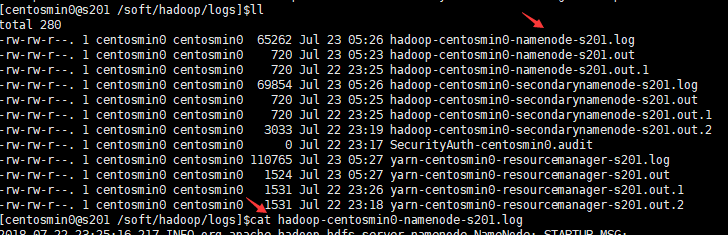
- 查看日志文件(名称节点查看主机s201,数据节点就去对应的数据节点主机查看)
$> cat /soft/hadoop/logs
//假如出现进程被占用的情况,则找到该进程,并杀死该进程
$>netstat -apno | grep 端口
//列出当前进程
$>jps
$> kill -9 进程号
- 删除临时目录文件和hadoop日志
//删除临时目录文件
$>cd /tmp
$>rm -rf hadoop-centosmin0
$>ssh s202 rm -rf /tmp/hadoop-centosmin0
$>ssh s203 rm -rf /tmp/hadoop-centosmin0
$>ssh s204 rm -rf /tmp/hadoop-centosmin0
//删除hadoop日志
$>cd /soft/hadoop/logs
$>rm -rf *
$>ssh s202 rm -rf /soft/hadoop/logs/*
$>ssh s203 rm -rf /soft/hadoop/logs/*
$>ssh s204 rm -rf /soft/hadoop/logs/*
- 格式化文件系统
$>hadoop namenode -format
- 启动hadoop进程
$>start-all.sh
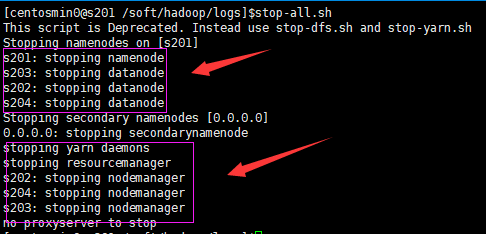
- 对应还有关闭hadoop进程
$>stop-all.sh
提示:善于查看hadoop日志是调试的关键!!!















 8097
8097

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









