







 超级会员免费看
超级会员免费看
Spark MLlib Pipeline
前面我们一起学习了如何在 Spark MLlib 框架下做特征工程与模型训练。不论是特征工程,还是模型训练,针对同一个机器学习问题,我们往往需要尝试不同的特征处理方法或是模型算法。结合之前的大量实例,细心的你想必早已发现,针对同一问题,不同的算法选型在开发的过程中,存在着大量的重复性代码。
以 GBDT 和随机森林为例,它们处理数据的过程是相似的,原始数据都是经过 StringIndexer、VectorAssembler 和 VectorIndexer 这三个环节转化为训练样本,只不过 GBDT 最后用 GBTRegressor 来做回归,而随机森林用 RandomForestClassifier 来做分类。
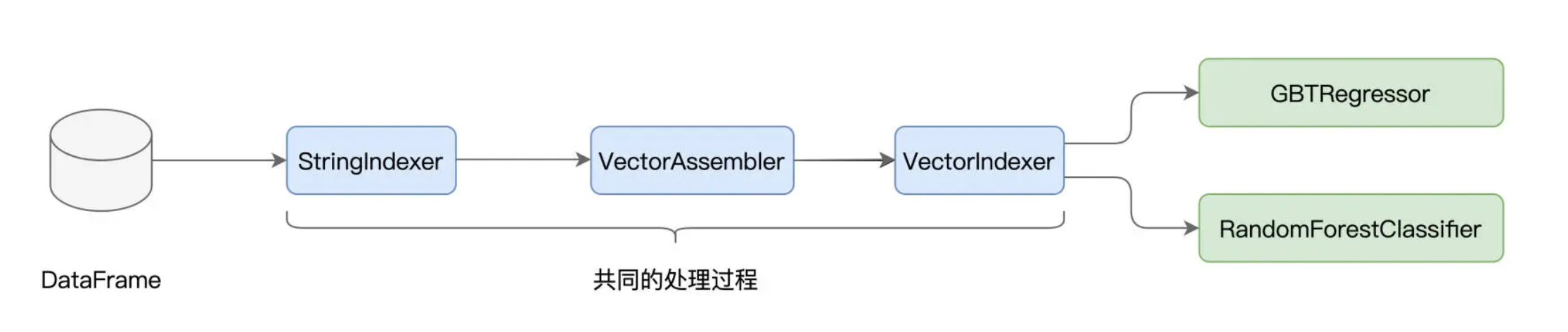
不仅如此,在之前验证模型效果的时候我们也没有闭环,仅仅检查了训练集上的拟合效果,并没有在测试集上进行推理并验证。如果我们尝试去加载新的测试数据集,那么所有的特征处理过程,都需要在测试集上重演一遍。无疑,这同样会引入大量冗余的重复代码。
那么,有没有什么办法,能够避免上述的

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1430
1430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











