







1,机器学习概念通俗理解:
当前有一些数据(即输入), 我们想找一个函数来处理这些输入数据, 以获得一个我们想知道的事件的结果(即输出). 而机器学习就是找这个函数的一种方法.
参见:
李宏毅深度学习课程http://speech.ee.ntu.edu.tw/~tlkagk/index.html
https://www.cnblogs.com/subconscious/p/4107357.html
https://www.cnblogs.com/subconscious/p/5058741.html
http://blog.pluskid.org/?page_id=683
2,机器学习的步骤
-
机器学习想要找的函数长什么样: 受神经元启发,我们一般认为这些函数是由W(weight)和B(bias)为参数的函数,以θ(w,b)代表函数参数,X代表输入数据:
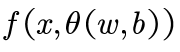
-
不同的θ就意味着不同的函数f, 我们如何来确定到底哪一个参数集θ对应的函数f才是最优的, 机器学习引入了损失函数来作为判断标准。注意:误差函数(error)=代价函数(cost function)=目标函数(objective function)=损失函数(loss function)。
-
针对不同的θ对应的f使用训练数据(就是输入-输出数据对,不含θ数据)来训练,然后能获得对应该θ的最小损失函数的值。
-
所谓的学习过程就是不断改变θ,重复第3步来得到非常多的损失函数值,这些损失函数值中最小的就是我们要找的函数f。此步骤用线性代数就可以求解得到最优θ。
-
那么θ的值有无穷多个,我们要依次全部试一遍来获得最优f吗? 答案是不需要,我们随意选定一个初始θ,然后可以使用梯度下降法来让机器以一定的学习速率来更改和遍历θ。
3,梯度下降法的理解:
参见https://www.jianshu.com/p/c7e642877b0e
- 此公式的意义是:J是关于Θ的一个函数,即损失函数,我们当前所处的位置为Θ0点,要从这个点走到J的最小值点,也就是山底。首先我们先确定前进的方向,也就是梯度的反向,然后走一段距离的步长,也就是α,走完这个段步长,就到达了Θ1这个点!
-
为什么要梯度要乘以一个负号?
梯度前加一个负号,就意味着朝着梯度相反的方向前进!梯度的方向实际就是函数在此点上升最快的方向!而我们需要朝着下降最快的方向走,自然就是负的梯度的方向,所以此处需要加上负号。 -
α是什么含义?
α在梯度下降算法中被称作为学习率或者步长,意味着我们可以通过α来控制每一步走的距离。



机器学习主要包括:
///回归算法
线性回归
逻辑回归
多元自适应回归(MARS)
本地散点平滑估计(LOESS)
//基于实例的学习算法
K - 邻近算法(kNN)
学习矢量化(LVQ)
自组织映射算法(SOM)
局部加权学习算法(LWL)
///正则化算法
岭回归(Ridge Regression)
LASSO(Least Absolute Shrinkage and Selection Operator)
Elastic Net
最小角回归(LARS)
///决策树算法
分类和回归树(CART)
ID3 算法 (Iterative Dichotomiser 3)
C4.5 和 C5.0
CHAID(Chi-squared Automatic Interaction Detection()
随机森林(Random Forest)
多元自适应回归样条(MARS)
梯度推进机(Gradient Boosting Machine, GBM)
/贝叶斯算法
朴素贝叶斯
高斯朴素贝叶斯
多项式朴素贝叶斯
AODE(Averaged One-Dependence Estimators)
贝叶斯网络(Bayesian Belief Network)
///基于核的算法
支持向量机(SVM)
径向基函数(Radial Basis Function ,RBF)
线性判别分析(Linear Discriminate Analysis ,LDA)
聚类算法
K - 均值
K - 中位数
EM 算法
分层聚类
关联规则学习
Apriori 算法
Eclat 算法
///神经网络
感知器
反向传播算法(BP)
Hopfield 网络
径向基函数网络(RBFN)
深度学习
深度玻尔兹曼机(DBM)
卷积神经网络(CNN)
递归神经网络(RNN、LSTM)
栈式自编码算法(Stacked Auto-Encoder)
//降维算法
主成分分析法(PCA)
主成分回归(PCR)
偏最小二乘回归(PLSR)
萨蒙映射
多维尺度分析法(MDS)
投影寻踪法(PP)
线性判别分析法(LDA)
混合判别分析法(MDA)
二次判别分析法(QDA)
灵活判别分析法(Flexible Discriminant Analysis,FDA
///集成算法
Boosting
Bagging
AdaBoost
堆叠泛化(混合)
GBM 算法
GBRT 算法
随机森林
///其他算法
特征选择算法
性能评估算法
自然语言处理
计算机视觉
推荐系统
强化学习
迁移学习这里推荐另一位博客作者的学习笔记:https://www.cnblogs.com/xxlad/p/11198853.html















 167
167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









