







Tips for Deep Learning
针对training set和testing set上的performance分别提出针对性的解决方法
- 在training set上准确率不高: new activation function:ReLU、Maxout adaptive learning rate:Adagrad、RMSProp、Momentum、Adam
- 在testing set上准确率不高:Early Stopping、Regularization or Dropout
1,training set上准确率不高的解决方案-New activation function
activation function(激活函数)是用来加入非线性因素的,解决线性模型所不能解决的问题.
激活函数作用:参见https://www.zhihu.com/question/22334626
- 如果不用激励函数(其实相当于激励函数是f(x) = x)或使用线性函数作为激活函数,在这种情况下你每一层节点的输入都是上层输出的线性函数,输出都是输入的线性组合,与没有隐藏层效果相当。
- 线性的表达能力太有限了,很多数据无法进行线性分割,即使经过多层网络的叠加,y=ax+b无论叠加多少层最后仍然是线性的,增加网络的深度根本没有意义。
- 引入非线性函数作为激励函数,这样深层神经网络表达能力就更加强大(不再是输入的线性组合,而是几乎可以逼近任意函数)。
1,梯度消失和梯度爆炸
第一种解释:
参考:
https://blog.csdn.net/baidu_29782299/article/details/52742773
https://www.cnblogs.com/xxlad/p/11283104.html
当network很深的时候,在靠近input的地方,这些参数的gradient(即对最后loss function的微分)是比较小的;而在比较靠近output的地方,它对loss的微分值会是比较大的.为什么会这样呢? 因为在靠近输入层时,根据反向传播,梯度的计算是一直相乘的,靠近output的梯度相乘的数比较少.


因此当你设定同样learning rate的时候,靠近input的地方,它参数的update是很慢的;而靠近output的地方,它参数的update是比较快的
所以在靠近input的地方,参数几乎还是random的时候(没来得及更新),output就已经根据这些random的结果找到了一个local minima,然后就converge(收敛)了
这个时候你会发现,参数的loss下降的速度变得很慢,你就会觉得gradient已经接近于0了,于是把程序停掉了,由于这个converge,是几乎base on random的参数,所以model的参数并没有被训练充分,那在training data上得到的结果肯定是很差的.
第二种解释:

2,利用整流/修正线性单元(ReLU)作为激活函数,以解决解决梯度消失问题
ReLU函数表达式:

RELU是分段线性函数,怎么实现非线性呢?所谓非线性,就是一阶导数不为常数; 线性就是一阶导数为常数.
ReLU的导数为:
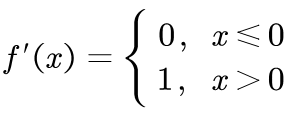
显然,ReLU的导数不是常数,所以ReLU是非线性的。
ReLU还可以令神经网络更加thinner: 因为output=0的neuron对整个network是没有任何作用的,因此可以把它们从network中拿掉. 剩下的input等于output是linear时,你整个network就是a thinner linear network。由于output=input,不会像sigmoid function一样使input产生的影响逐层递减


下图是应用ReLU激活函数后的特征图变换。

3,Maxout——能自动学习激活函数(随着参数更新,激活函数一直改变)
Maxout的想法是,让network自动去学习它的activation function,那Maxout network就可以自动学出ReLU,也可以学出其他的activation function,这一切都是由training data来决定的.
Maxout可以被看做是一个新的neuron,它的过程就好像在一个layer上做Max Pooling一样,它和原来的network不同之处在于,它把原来几个“neuron”的input按一定规则组成了一个group(如何分组由你自己决定的,它就是network structure里一个需要被调的参数),然后并没有使它们通过activation function得到output,而是选取其中的最大值当做这几个“neuron”的output.
Maxout是如何构造出ReLU这个activation function的呢?Z2的w,b设置为0
除了ReLU,Maxout还可以实现更多不同的activation function: 如果Z2的w,b不是0, 那么Maxout根据每一个Neural的不同的wight和bias,就可以得到不同的activation function; 这些wight和bias参数,Maxout network都可以自己学习出来,因此它是一个Learnable Activation Function
How to train Maxout?
理论上max函数无法微分, 但是事实上,只要可以给出训练数据,我们就可以用梯度下降来train网络。为什么呢?请往下看.
只要给出训练数据,Max函数就能够运作起来,然后选出最大值,未被选定的就可以从网络中拿掉,从而得到一个比较细长的linear network.
这样训练Maxout就转变成了:根据每笔training data使用Backpropagation的方法去训练留下来的thiner linear network的参数.
这个时候你也许会有一个问题,如果按照上面的做法,那岂不是只会train留在network里面的那些参数,剩下的参数该怎么办?那些被拿掉的参数(weight)岂不是永远也train不到了吗?事实不是如此,因为不同的输入数据(training data),得到的z的值是不同的,max value是不一样的,被maxout选择留下来的参数也就不一样,由于我们有很多很多笔training data,所以network的structure在训练中不断地变换,实际上最后每一个weight参数都会被train到.
2,training set上准确率不高的解决方案-Adaptive learning rate
参见我的另一个博文: 机器学习入门-第三天 https://blog.csdn.net/king52113141314/article/details/106038779
3,testing set上准确率不高的解决方案-Early Stopping
当在Training set上的loss逐渐减小的时候,在Testing set上的loss反而可能上升.
假如知道testing set 上的loss变化,你应该停在不是training set最小的地方,而是testing set最小的地方(如图所示),可能training到这个地方就停下来。但是testing set实际上是未知的东西(尽管它是有label的set)。所以我们会用validation set模拟 testing set,什么时候validation set最小,什么时候training停下来。
4,testing set上准确率不高的解决方案-正则化Regularization
首先看我的博文:机器学习入门-第二天,正则化https://blog.csdn.net/king52113141314/article/details/106015484
regularization就是在原来的loss function上额外增加1个regularization term.
1,L2 regularization

通常我们在做regularization的时候,新加的term里是不会考虑bias这一项的,因为加regularization的目的是为了让我们的function更平滑,而bias通常是跟function的平滑程度没有关系的,bias只是函数的上下左右移动.

在update参数的时候,每次都会把参数乘以一个小于1的值,因此使用L2 regularization可以让weight每次都变得更小一点,这就叫做Weight Decay(权重衰减).
2, L1 regularization
L1是在Loss函数加上绝对值之和。当w为正时,更新后的w变小。当w为负时,更新后的w变大——因此它的效果就是让w往0靠,使网络中的权重尽可能为0,也就相当于减小了网络复杂度,防止过拟合.
Q:你的第一个问题可能会是,绝对值不能微分啊,该怎么处理呢?
A:实际上绝对值就是一个V字形的函数,在V的左边微分值是-1,在V的右边微分值是1,只有在0的地方是不能微分的,那真的走到0的时候就胡乱给它一个值,比如0,就ok了
如果w是正的,那微分出来就是+1,如果w是负的,那微分出来就是-1,所以这边写了一个w的sign function(就是符号函数,其功能是取某个数的符号(正或负)),它的意思是说,如果w是正数的话,这个function output就是+1,w是负数的话,这个function output就是-1.

L1和L2,虽然它们同样是让参数的绝对值变小,但它们做的事情其实略有不同:
- L1使参数绝对值变小的方式是每次update减掉一个固定的值
- L2使参数绝对值变小的方式是每次update乘上一个小于1的固定值
当参数w的绝对值比较大的时候,L2会让w减小得更快,而L1每次update只让w减去一个固定的值,train完以后可能还会有很多比较大的参数;当参数w的绝对值比较小的时候,L2的w减小速度就会变得很慢,train出来的参数平均都是比较小的,而L1每次下降一个固定的value,train出来的参数是比较sparse的,这些参数有很多是接近0的值,也会有很大的值.
小结: 在deep learning里面,regularization的重要性往往没有SVM这类方法来得高,因为我们在做neural network的时候,通常都是从一个很小的、接近于0的值开始初始参数的,而做update的时候,通常都是让参数离0越来越远,但是regularization要达到的目的,就是希望我们的参数不要离0太远.
Early Stopping会减少update的次数,其实也会避免你的参数离0太远,这跟regularization做的事情是很接近的
所以在neural network里面,regularization的作用并没有SVM来的重要,SVM其实是explicitly把regularization这件事情写在了它的objective function(目标函数)里面,SVM是要去解一个convex optimization problem,因此它解的时候不一定会有iteration的过程,它不会有Early Stopping这件事,而是一步就可以走到那个最好的结果了,所以你没有办法用Early Stopping防止它离目标太远,你必须要把regularization explicitly加到你的loss function里面去.
5,testing set上准确率不高的解决方案-Dropout
dropout也是为了简化神经网络结构的目的,但L1、L2正则化是通过修改代价函数来实现的,而Dropout则是通过修改神经网络本身来实现的。
1,Training
在training的时候,每次update参数之前,我们对每一个neuron(也包括input layer的“neuron”)做sampling(抽样) ,每个neuron都有p%的几率会被丢掉,如果某个neuron被丢掉的话,跟它相连的weight也都要被丢掉; 实际上就是每次update参数之前都通过抽样只保留network中的一部分neuron来做训练.
注:每次update参数之前都要做一遍sampling,所以每次update参数的时候,拿来training的network structure都是不一样的;你可能会觉得这个方法跟前面提到的Maxout会有一点像,但实际上,Maxout是每一笔data对应的network structure不同,而Dropout是每一次update的network structure都是不同的(每一个minibatch对应着一次update,而一个minibatch里含有很多笔data)
Dropout真正要做的事情,就是要让你在training set上的结果变差,但是在testing set上的结果是变好的.
2,Testing
在使用dropout方法做testing的时候要注意两件事情:
- testing的时候不做dropout,所有的neuron都要被用到
- 假设在training的时候,dropout rate是p%,从training data中被learn出来的所有weight都要乘上(1-p%)才能被当做testing的weight使用
3,为什么dropout有效?
直观理解,训练时条件苛刻,实际操作时就会轻松很多,效果也更好.比如原本60分钟要做完的试卷,你平时都严格控制在50分钟完成,剩10分钟检查,这样考试的时候就会从容,而且因为有检查时间,得到更高的分数.
4,为什么从training data中被learn出来的所有weight都要乘上(1-p%)才能被当做testing的weight使用?
5,Dropout 有效的另一种解释:dropout是一种终极的ensemble的方法
打靶有两种情况:
- 一种是因为bias大而导致打不准(参数过少)
- 另一种是因为variance大而导致打不准(参数过多)
如果今天有一个很复杂的model,往往是bias准,但variance很大。若很复杂的model有很多,虽然variance很大,但bias很准,最后平均下来,bias也很小,结果就很准(这是经验结论,需要后续理论解释)。所以ensemble做的事情就是利用这个特性。我们从原来的training data里面sample出很多subset,然后train很多个model,每一个model的structure甚至都可以不一样;在testing的时候,丢了一笔testing data进来,使它通过所有的model,得到一大堆的结果,然后把这些结果平均起来当做最后的output. 如果你的model很复杂,这一招往往是很有用的,那著名的random forest(随机森林)也是实践这个精神的一个方法,也就是如果你用一个decision tree,它就会很弱,也很容易overfitting,而如果采用random forest,它就没有那么容易overfitting.
在training network的时候,每次拿一个minibatch出来所训练的network都是不同的
按照ensemble这个方法的逻辑,在testing的时候,你把那train好的一大把network通通拿出来,然后把手上这一笔testing data丢到这把network里面去,每个network都给你吐出一个结果来,然后你把所有的结果平均起来,就是最后的output. 由于network实在太多了,这样运算量太大了.
dropout最神奇的地方是,当你并没有把这些network分开考虑,而是用一个完整的network,这个network的weight是用之前那一把network train出来的对应weight乘上(1-p%),然后再把手上这笔testing data丢进这个完整的network,得到的output跟network分开考虑的ensemble的output,是惊人的相近.
6,为什么dropout的output跟network分开考虑的ensemble的output很接近?
以下图为例说明: 这边想要呈现的是,在这个最简单的case里面,用不同的network structure做ensemble这件事情,跟我们用一整个network,并且把weight乘上一个值而不做ensemble所得到的output,其实是一样的.
值得注意的是,只有是linear的network,才会得到上述的等价关系,如果network是非linear的,ensemble和dropout是不equivalent的;但是,dropout最后一个很神奇的地方是,虽然在non-linear的情况下,它是跟ensemble不相等的,但最后的结果还是会work
如果network很接近linear的话,dropout所得到的performance会比较好,而ReLU和Maxout的network相对来说是比较接近于linear的,所以我们通常会把含有ReLU或Maxout的network与Dropout配合起来使用.
参考:
https://sakura-gh.github.io/ML-notes/ML-notes-html/13_Tips-for-Deep-Learning.html
https://www.cnblogs.com/xxlad/p/11283104.html
https://datawhalechina.github.io/leeml-notes/#/chapter18/chapter18?id=regularization
题后记:
一个有用的总结:https://zhuanlan.zhihu.com/p/138111411
- 神经网络可以看成“线性组合-非线性激活函数-线性组合-非线性激活函数…”这样的较为复杂网络结构机器学习:为了解决一些难以用人工写逻辑来解决的问题。
- 非监督学习与监督学习的区别:监督学习需要有正确的数据来引导,而非监督学习是单纯从数据中寻找规律。
- 学习的目的是不断减少预测值与实际值的偏差,具体表现在参数的矫正。
- 梯度下降算法:在n维坐标系中任意取一个点,沿着下降最快的一条路线找到最低点(不同的起点可能有不同的局部最低点),每一次下降都将对所有数据进行迭代。
- 随机梯度下降算法:为了应对大量数据,此算法在寻找最低点的时候,每一次寻找都是在上一次基础上进行的,因此只会对数据进行一次遍历,但得到的值会在最小值的周围,不一定是最小值。
- 直接通过求解析式来得到最小值
- 梯度下降具体算法是:依次对代价函数中的参数求偏导,最后使每个参数减去学习率乘以那个值,直到代价函数收敛为止。
- 多项式回归虽然能够解决非线性问题,但需要人工构造非线性的特征,但神经网络可应付样本非线性可分的情况,又同时能够自动构造非线性。
- 由于L-SVM是线性分类器,所以不能解决样本线性不可分的问题。于是后来人们引入了核函数的概念,于是得到了K-SVM(K是Kernel的意思)。从本质上讲,核函数是用于将原始特征映射到高维的特征空间中去,并认为在高为特征空间中能够实现线性可分。
- 之所以使用sigmoid函数是因为直接使用感知机的话,由于只会输出0和1,那么神经网络中轻微的改变就可能导致结果的巨大变化,而sigmoid函数是非线性的,也是连续的。
- 另一个原因是sigmoid函数可以将结果映射到0-1区间中。其计算公式为f(wx+b)。
- 感知机的工作原理是输入值乘以权值,然后与偏移值b进行比较,从而决定输出是1还是0,而sigmoid感知机将会在计算与b的差值之后再进行函数变换,从而体现出程度的概念。
- 局部加权回归:是一个非参数学习算法,之所以是非参数,是因为它是基于样本数量进行回归的,在xy坐标系中,当给定一个x0,将根据周围几个点拟合出一条直线,从而得到预测的值,然后计算误差,再根据类似于高斯函数的分布(加权)对样本的坐标进行调整。注意一点,每一个样本数据的输入都会对所有的样本坐标进行加权调整(回归)。















 337
337











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









