






Pandas是目前Python被使用的最多的数据分析的库,常用于金融分析、参数分析、大数据分析、数据预处理、数据治理等工作中,今天我们开始详细学习Pandas库,我知道由很多学者已经学习过基础的Pandas的API和方法,然而还是由很多的初学者对这个库一知半解,所以本文会比较详细的说明这个库中的最重要的一个方法read_xxx,将讲述笔者知道的所有参数,如有新的参数或者理解错误,请在评论区指出,万分感谢。
要想在Python中导入Pandas进行数据分析,你需要首先需要使用Win+R打开系统运行,输入cmd打开控制台,输入:
pip install pandas
如果遇到了No module named 'pandas'的这个问题,首先排查是否下载pandas,然后查看下载的pandas是不是下载在python的工作环境中。基本上可以解决这个问题。
完成Pandas导入到Python中后,下面说一下Pandas的一个核心的方法,read_xxx方法,
这个方法可以读取到多个文件,在一般的工作中,常见格式的文件,Excel,CSV,SQL数据库,JSON文件,HTML文件;
读取的代码如下:
#以pd为变量名将pandas导入到Python中
import pandas as pd
#读取Excel文件代码
df=pd.read_excel("xxxx.xlsx")或者df=pd.read_excel("xxxx.xls")
#读取csv文件代码
df=pd.read_csv("xxxx.csv")
#读取SQL数据库代码
query="数据库查询代码"
df=pd.read_SQL(query,conn)#其中conn为数据库的链接变量
#读取html文件
df=pd.read_html("xxxx.html")
下面是一些笔者学习到一些平常不常见的文件,也能够被Pandas进行的读取
HDF5文件(一种用于存储和组织大量科学数据的文件格式,后缀一般为.h5或hdf5);
Parquet文件(一种用于高效存储列式数据的开放源文件格式),通常用于大规模数据分析。文件后缀通常为.parquer);
Feather文件(一种用于高效存储列式数据的文件格式,通常用于在Python和R之间快速交换数据,文件后缀通常是.feather);
SAS文件(SAS软件的数据文件格式,通常用于存储存储分析数据,文件后缀通常为.sas7bdat);
STATA文件(Stata的统计软件的数据文件格式,通常用于存储统计分析数据,文件后缀一般为.dta);
SPSS文件(SPSS统计软件的数据文件格式,通常用于存储统计分析数据,文件后缀通常为.sav)
Google BigQuery数据:Google BigQuery的数据存储格式,通常在于Google Cloud上村塾当和大规模的数据
Msgpack文件:一种用于跨平台数据交换的二进制格式,通常用于高效地序列化和反序列化数据,文件后缀通常为 .msgpack。
Pickle文件:Python特有的序列化文件格式,用于将Python对象序列化为字节流,文件后缀通常为.pkl或.pickle
Clipboard文件:剪贴板文件是指从剪贴板中复制的数据,通常用于在不同应用程序之间传输数据,没有特定的文件后缀。
读取以上文件的代码如下:
#读取HDF5文件
df = pd.read_hdf('xxxx.h5', 'key')
#读取Parquet文件
df = pd.read_parquet("xxxx.parquet")
#读取Feather文件
df = pd.read_feather('xxxx.feather')
#读取SAS文件
df = pd.read_sas("xxxx.sas7bdat")
#读取STATA文件
df = pd.read_stata("xxxx.dta")
#读取SPSS文件
df = pd.read_spss('file.sav')
#读取Google BigQuery数据
from google.cloud import bigquery
client=bigquery.Client()
query="SELECT * FROM dataset.table"
df = client.query(query).to_dataframe()
#读取Msgpack文件
df = pd.read_msgpack("file.megpack")
#读取Pickle文件
with open('xxxx.pkl','rb') as f:
df=pd.read_pickle(f)接下来是探讨read_xxx这个方法中一些常用和不常用的参数
1、filepath_or_buffer参数,这个参数是需要导入文件的路径,如下图中红框,这个参数并不需要显性的将这个参数写出来。使用方法如下:

2、sep参数,这个参数用于指定一些存在字段分隔符,例如CSV文件使用制表符分隔字段,可以使用sep='\t'来指定分隔符为制表符。这个参数需要显性的写出来,使用的方法如下:

3、header参数,功能是读取数据用作DataFrame的列名,默认为0(即如果不将这个参数显性写出,则默认读取数据中的第一行作为列名),如果你需要读取的数据没有列名,则应该设置为None。
 4、index_col参数,功能是读取数据用作DataFrame的行名,默认为0(即如果不将这个参数咸腥写出来,则默认读取数据中的第一列作为行名),如果你需要读取的数据没有行名,则应该显性的写出这个参数,并设置为None
4、index_col参数,功能是读取数据用作DataFrame的行名,默认为0(即如果不将这个参数咸腥写出来,则默认读取数据中的第一列作为行名),如果你需要读取的数据没有行名,则应该显性的写出这个参数,并设置为None

5、names参数,功能是指定没有的列名的数据新的列名。这个参数需要显性的写出,默认为None
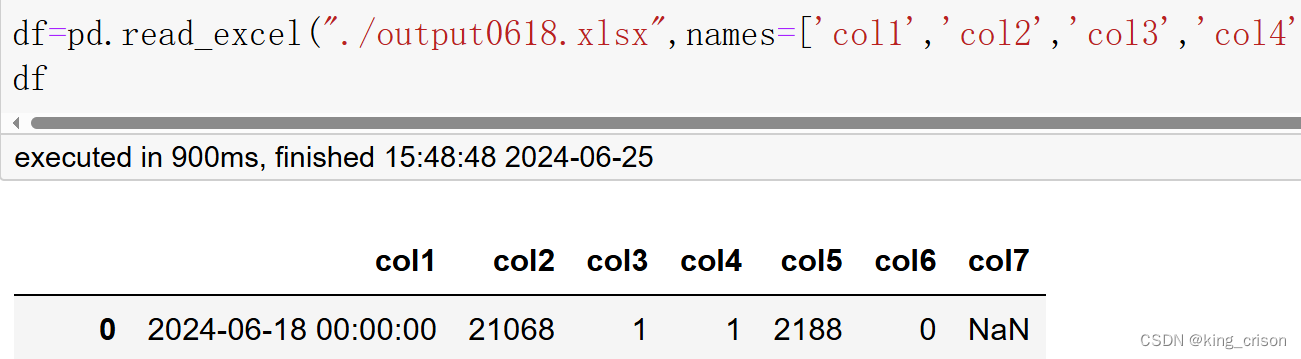
6、parse_dates:尝试将数据解析为日期,默认为False,如果CSV文件或者Excel文件中包含日期列,可以使用parse_date参数将其解析为日期格。

7、dtype:指定每列的数据类型,比如将col2这个列的数据类型修改为’float',注意一定是符合数据类型变化的,文字无法改变为int或者Float,注意dtype后面跟着的是大括号,而不是中小括号。
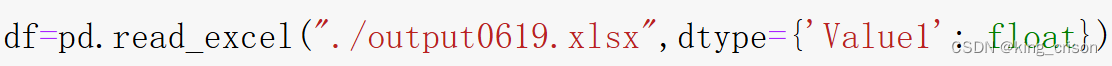
8、skiprows:作用是忽略需要忽略的行数。如果CSV文件或者excel文件的开头包含一些不需要的行,可以使用skiprows参数来忽略这些行,这个参数需要显性写出,如下代码的功能是忽略两行,直接从第三行开始读取。

9、nrows:作用是读取需要读取的行数。如果只需要读取文件的前几行,可以使用nrows参数限制读取的行数。这个参数需要显性写出,如下代码的功能是只读取前5行

10、na_values:用于替换列中NA/NaN值的值。如果CSV文件中的缺失值使用了特定的标识(如-1或NA),可以使用na_values参数将其替换为NaN,例如将列1中的-1值,修改为NAN,将列2中的-999值修改为NaN。这个代码需要显性写出。

以上是笔者学习的,有关read_xxx这个方法可以读取的数据,以及其参数,如果有缺失或者错误,请在评论区指出,学习永无止境。















 1483
1483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









