






这个系列好就不更新了,因为一直也没太惊艳的技术出来,直到这个论文出来:
https://arxiv.org/pdf/2504.16078
感兴趣的读者可以从第一章开始:
https://mp.weixin.qq.com/s?__biz=MzkwMTU3NjYwOA==&mid=2247484530&idx=1&sn=4ac57a2e851c868502c2a965847f5d81&chksm=c0b3e6bdf7c46faba14c0068f09267e0be1bc29fd0929d3da00ae0a79de1104a69160bf1c9b5&token=1015028219&lang=en_US&scene=21#wechat_redirect
如果你玩过开源的Text2video,也就是文生视频,也会感慨AI越来越能整活儿了,但是如果你好奇去各大平台看一圈,基本上视频最大就是在8-10秒左右,甚至有3-5秒的。(sora能到20秒)
当然有兄弟说是算力的问题,这个确实是一个问题,生成视频diffusion的算力确实要比纯text多,但是这个如果有钱也不是问题(后文我们发现其实就算有钱也是问题),但是现在我们谈论的是钱解决不了的问题,一致性
这个一致性指的是多帧一致性


比如这个视频,兵马俑大战美军,打着打着,兵马俑就突然叛变变成美军了

造成这个问题的原因是什么?
首先Diffusion网络是没时间概念的
如果是生图可能还行,我们以一个简单的生图的流程来看
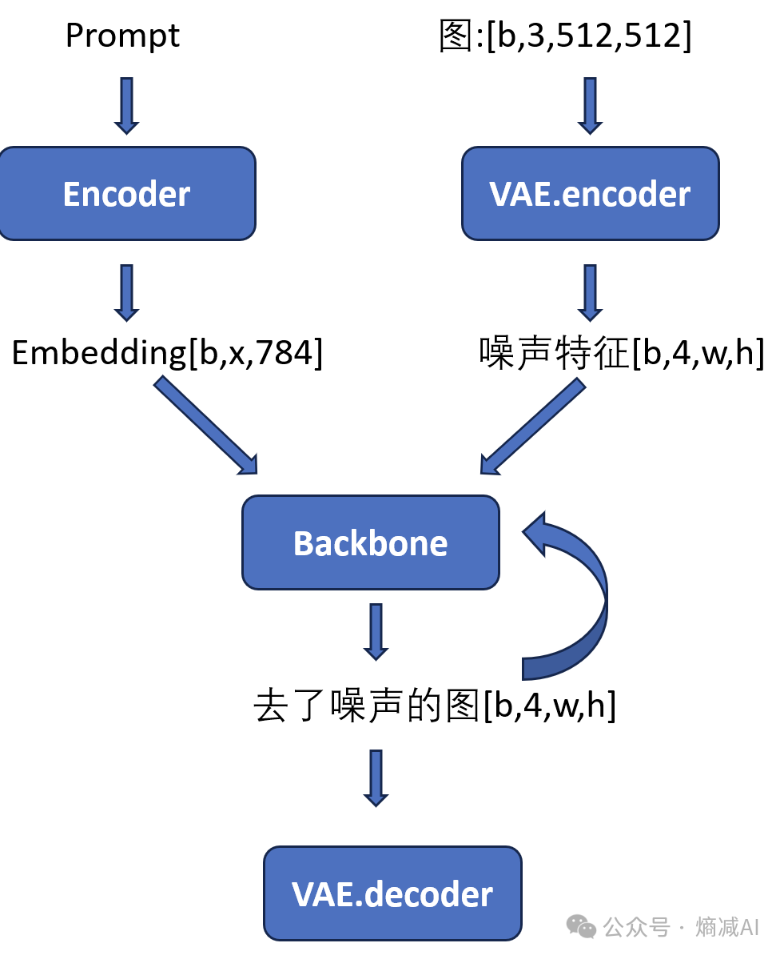
这就是一个典型的SD生图流程,通过对比训练的clip embeddding能力,让text的输入隐式包含很多图像的相似性,很好的配合vae编码的latent,这时latent 相当于Q,被clip embedding的text相当于kv,latent再不断去噪声的过程,把text当作参照,也就是按着prompt的指令来生成相应图片位置的object
上图的backbone从SD早期的unet一直演化到sd3的Dit,除了扩展性和网络架构变了以外,但是本质并没有改变,文生图的领域是不需要时序信息的
上图由halomate.ai,通过prompt直出

但是这个网络面对生视频怎么办呢?
视频的构成是一系列连续的帧,每一帧之间的动作差距很小,但是一致性是要求强一致的,这就要求网络能感知帧的序列关联性,也可以延伸认为是时许关联性。
可是传统的difussion解决方案,从vae到backbone这两部分的网路都没有时间模块
于是人们考虑先从VAE动手
简单的思路
Uniform frame sampling
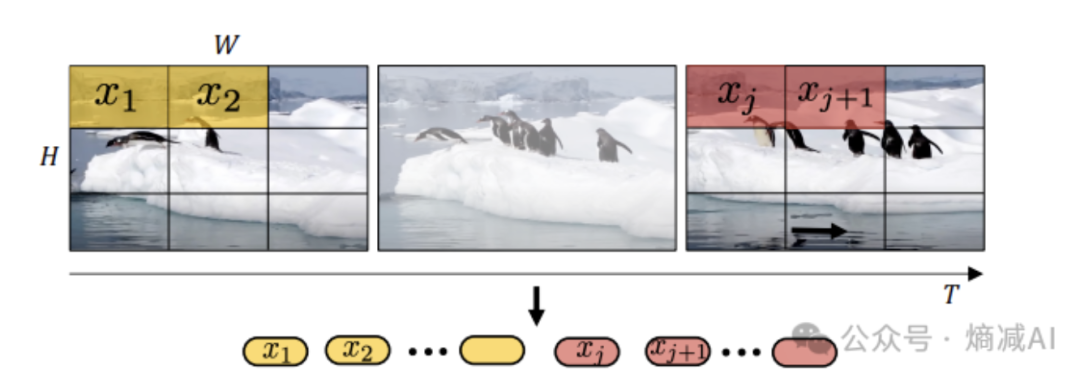
-
原始视频数据 (Top Row): 视频由一系列按时间顺序排列的帧组成(时间轴 T 从左到右)。图中展示了视频中的三帧,但实际上视频包含更多帧。
-
帧采样 (Implicit Step): 虽然没有明确画出“丢弃”的帧,但“Uniform Frame Sampling”这个名字意味着我们不是使用视频中的所有帧。而是按照一个固定的时间间隔(比如每隔 k 帧取一帧,或者每秒取 f 帧)来选择一部分帧。图中展示的第一帧和最后一帧(包含 x1, x2 和 xj, xj+1 的那两帧)就是被采样出来的帧,中间的那帧可能就被跳过了(或者它也是被采样出来的,只是没有突出显示其 patch 而已,但均匀采样的核心在于选择帧的间隔是固定的)。
-
空间分块 (Spatial Patching): 对于每一个被采样出来的帧,将其在空间上分割成 H x W 个不重叠的小块 (patches)。这与 Vision Transformer (ViT) 处理图像的方式类似。图中的 x1, x2, xj, xj+1 就代表这些从对应采样帧中提取出的小块。
-
序列化/展平 (Flattening into Sequence - Bottom Row): 将所有采样帧提取出的空间小块,按照时间和空间的顺序(通常是先时间,再空间,即第一帧的所有块,然后第二帧的所有块...)拼接成一个一维的序列。这个序列 x1, x2, ..., xj, xj+1, ... 就是最终输入给 Transformer 模型的 token 序列。
总结就是个帧采样,然后按着时间顺序给展平称一维的向量了。
成熟的思路
Tubelet embedding
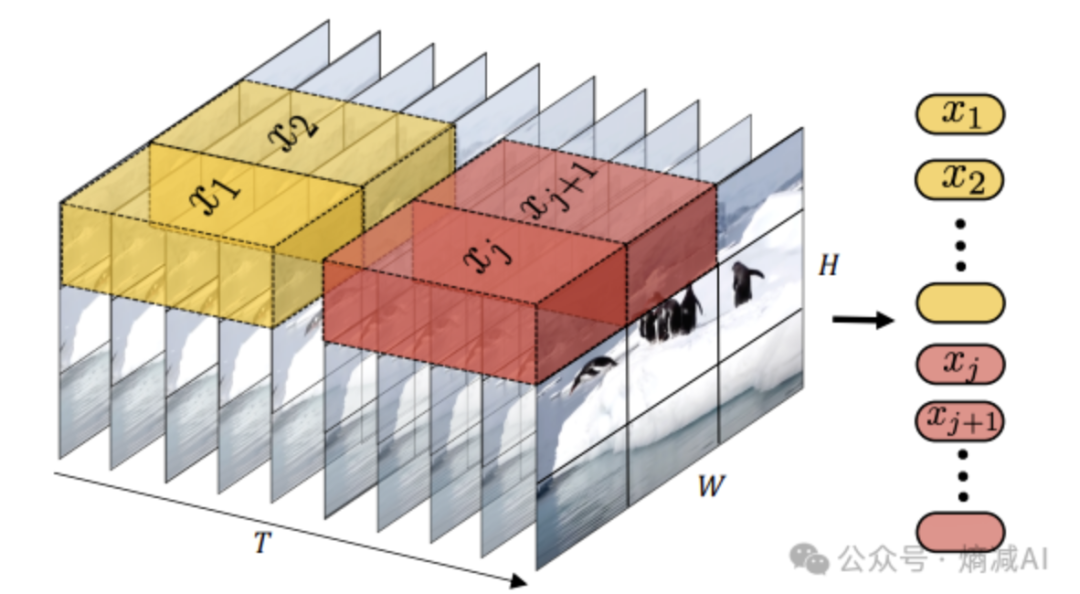
不同于uniform frame sampling,tubelet embedding可是实打实的每一帧都给利用上
令牌基础: 令牌 (x1, x2, ...) 是从视频中提取的三维时空块 (3D spatio-temporal patch),通常称为 "Tubelet"。
-
时间处理:
-
将视频看作一个 3D 数据体(高度 H x 宽度 W x 时间 T)。
-
同时在空间(H, W)和时间(T)维度上进行分块。
-
因此,每个 Tubelet (x1, x2) 本身就跨越了多个连续的帧,并覆盖了一个特定的空间区域。
-
时间信息不仅体现在令牌的顺序上,还内嵌在每个令牌内部,因为它直接捕捉了短时间窗口内的变化。
-
信息单元: 每个令牌携带的是一个短时间段内(Tubelet 的时间深度),某个空间区域的时空视觉信息。它能直接编码局部运动或变化,又因为它是全量的信息,不是采样的,所以效果好。
但是光靠vae能就能解决时序问题吗?那显然不是啊,因为vae它只管把视频(其实是序列帧,比如clip1,clip2,clip3,每个clip比如15帧,实际上我们训练视频模型也都是把视频切好序列帧喂给模型的)给编解码,它不管加噪去噪啊,这个操作都在backbone来做(目前基本都是DIT变种)
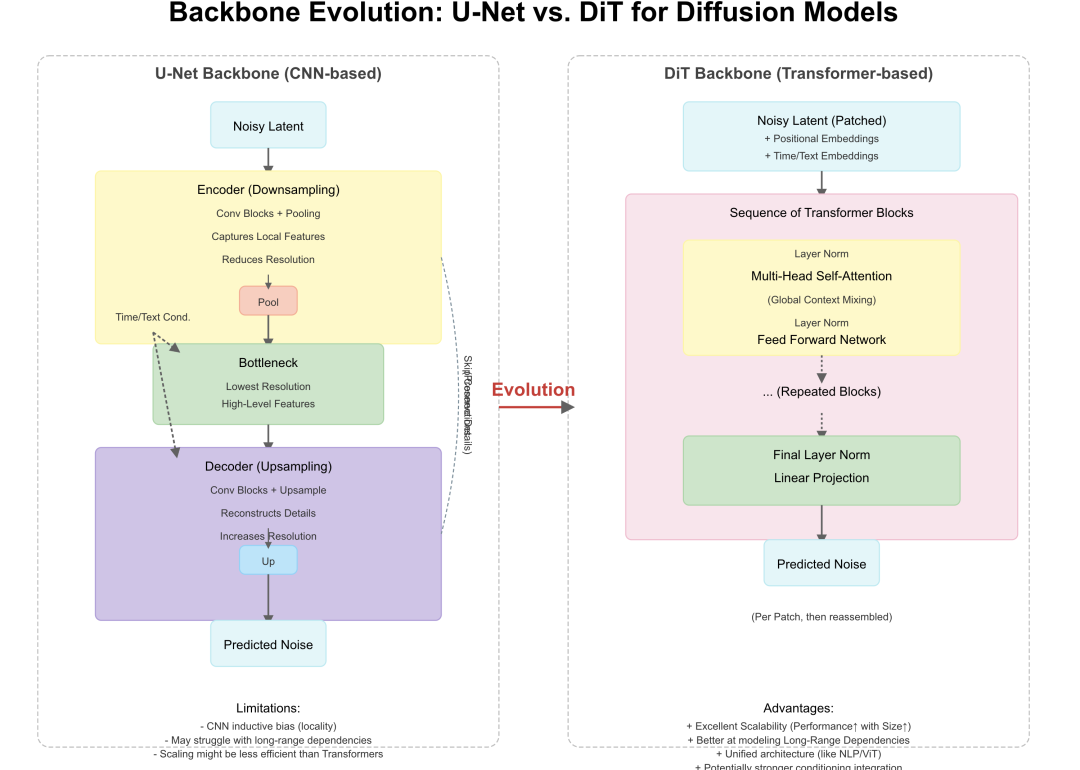
所以backbone必须有时序感知能力,这是通过什么体现出来的?
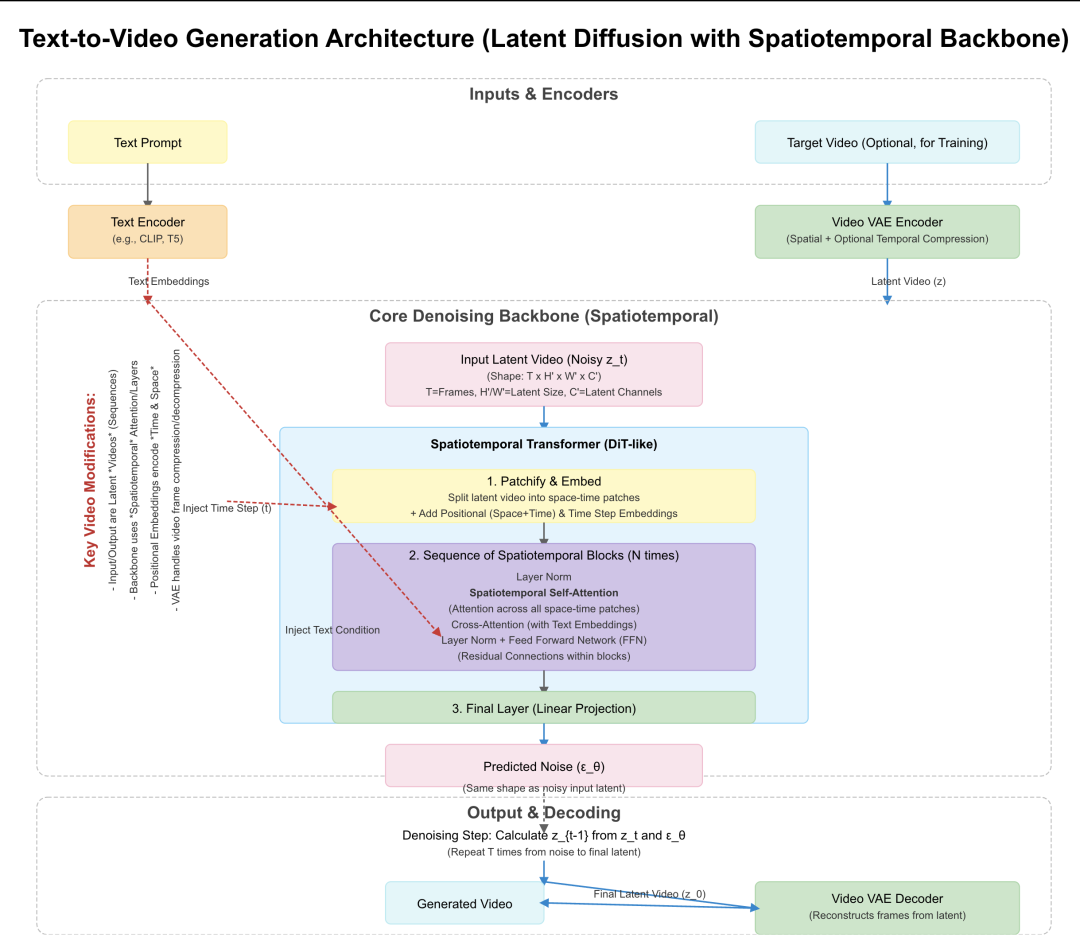
图片由halomate.ai生成
上图是一个基于 Latent Diffusion Model 思想,并采用 Spatiotemporal Transformer (类似 DiT) 作为核心 Backbone 的文生视频网络架构
1. 核心思想:Latent Diffusion for Video
与 Stable Diffusion (文生图) 类似,我们在潜在空间 (Latent Space) 中进行扩散和去噪过程,以大幅降低计算复杂度。
首先需要一个 Video VAE (Variational Autoencoder用我刚才讲的两种编码方式都可以,但是现在大部分都用tubelet的方式),它能将视频帧序列压缩成低维的潜在表示 (Latent Video),并能从潜在表示中解码回视频帧。这个 VAE 需要在大量视频数据上预训练。
2. 输入处理:
Text Prompt: 输入的文本描述通过一个强大的 Text Encoder (如 CLIP 或 T5 的变体,高端的模型来做指令跟随基本都用T5来替代clip了) 转换成文本嵌入 (Text Embeddings)。这些嵌入包含了文本的语义信息,将用于指导视频内容的生成。
Noisy Latent Video (z\_t): 在扩散过程的每一步 `t`,输入是加了噪声的潜在视频 `z_t`。在生成开始时 (t=T),这是一个纯高斯噪声,其形状与 VAE 输出的潜在视频一致 (`NumFrames x LatentHeight x LatentWidth x LatentChannels`,也就是我刚才说的tubelet,然后再加个RGB通道)。
Time Step Embedding: 当前的时间步 `t` 被编码成一个嵌入向量,告知网络当前的噪声水平。
3. 核心 Backbone: Spatiotemporal Transformer (DiT-like)
关键区别: 与处理静态图像的 Backbone (如标准 U-Net 或 ViT/DiT) 不同,视频 Backbone 必须同时处理空间信息 (每帧的内容) 和时间信息 (帧之间的变化和连贯性)。
Patchify 和 Embed: 将输入的潜在视频 `z_t` (T x H' x W' x C') 分割成一系列 时空块 (Spatiotemporal Patches)。例如,每个 Patch 可以是 `p x p` 空间区域跨越 `k` 帧。
Embeddings:
1- 为每个 Patch 添加Spatiotemporal Positional Embeddings 来编码每个 Patch 在原始视频中的空间位置 和 时间位置。这是捕捉时空结构的关键。
2- Time Step Embedding: 告知网络当前去噪阶段,在这就和时序基本彻底关联上了。
Spatiotemporal Transformer Blocks部分:
1) Spatiotemporal Self-Attention: 这是核心。注意力机制作用于所有时空 Patch 序列。这使得模型能够同时关注:
同一帧内不同空间区域的关系 (Spatial Context)。
同一空间区域在不同时间帧的关系 (Temporal Dynamics)。
不同空间区域在不同时间帧的关系 (Complex Motion & Interactions)。
2) Cross-Attention: 将 Text Embeddings 通过交叉注意力机制注入到 Transformer 块中,使得模型能够根据文本描述生成内容和动态。
3)FFN: 这没啥可说的了,就特征转换用的。
4)Output: Backbone 输出预测的噪声 `ε_θ`,其形状与输入的 `z_t` 相同。
4. 去噪过程与输出:
使用预测的噪声 `ε_θ` 和当前的噪声潜在视频 `z_t`,通过扩散模型的采样算法(如 DDPM, DDIM)计算出稍微去噪的潜在视频 `z_{t-1}`。
重复这个过程 T 步,从纯噪声 `z_T` 开始,逐步去噪得到最终的清晰潜在视频 `z_0`。
Video VAE Decoder: 将最终的潜在视频 `z_0` 输入预训练好的 VAE 解码器,重建出像素空间的视频帧序列,即生成的视频。
5. 处理时间维度: Spatiotemporal Transformer 通过其自注意力机制能够显式地建模长距离的时空依赖关系,对于生成连贯、动态符合描述的视频至关重要。当然 也可以使用基于 3D U-Net 的 Backbone,其中卷积层替换为 3D 卷积(同时处理空间和时间维度),并可能加入 Temporal Attention 模块。但目前 Transformer 在建模长距离依赖和可扩展性方面展现出更强的潜力,而且没人用3D unet来做视频,我们也就不解释了。
好了现在一个正常的文生视频的流程我们就讲完了,其实以前我也讲过,相当于在让大家复习一遍。
那我们今天讲的论文有什么过人之处呢?

最大的不同是,它能生成一分钟的视频,同时这个视频有着丰富的情节变化,不想现在的视频,即使10秒20秒也是相对简单的动作和拍摄视角的变化。
但是这个论文的视频我是看过的,非常惊艳就根一个普通的动画片没有任何区别,角色的多帧运动和串场的一致性上,是基本现在所有的模型都无法做到的。
我们刚才讲了在一个现在大部分的text2video的实现方案中,是扩展了self-attention层,让它有时空感知能力也就是所说的
Spatiotemporal Transformer Blocks
它这个论文里的网络相当于另辟蹊径,是这样实现的。
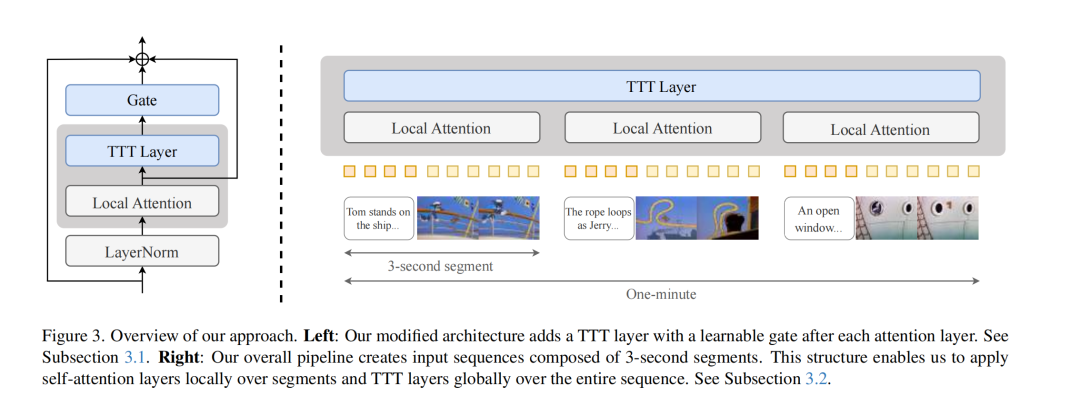
解释一下这个图
-
标准 Transformer 结构: 通常包含交替的attention层+MLP(叫FFN页性)。
-
一个典型的序列建模块大致是:输入
X-> LayerNorm -> Self-Attention -> 输出X'-> 残差连接 (X' + X) -> 输出Y_attn。 -
一个典型的 MLP 块大致是:输入
Y_attn-> LayerNorm -> FFN -> 输出Y_ffn'-> 残差连接 (Y_ffn' + Y_attn) -> 输出Y_final。
-
-
论文把架构给改了,从attn层出来以后不给MLP,中间差了一个类似bi-lstm的rnn
-
输入
X X' = self_attn(LN(X))(自注意力层的输出,注意这里已经包含了 LayerNorm)
Z = gate(TTT, X'; α)(前向 TTT 层处理
X')Z' = gate(TTT', Z; β)(反向 TTT 层处理
Z)Y = Z' + X(最终的残差连接,注意是 TTT 的输出
Z'与块的原始输入X相加)
-
这个双向RNN就是TTT层
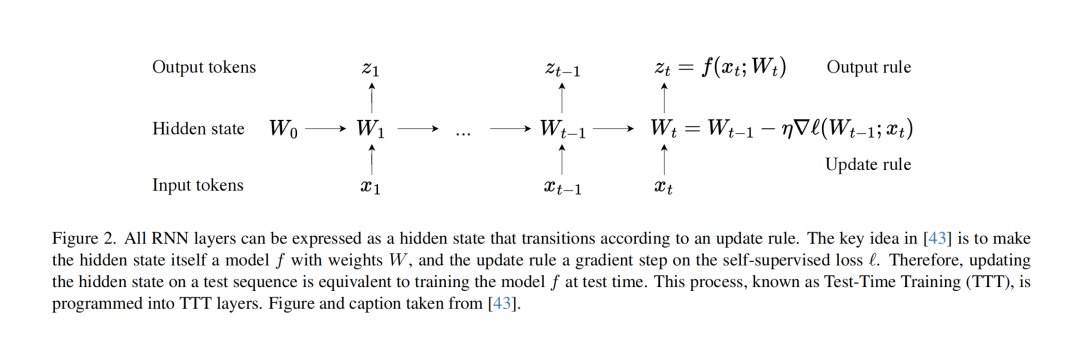
这张图展示了 测试时训练 (Test-Time Training, TTT) 层 的核心工作原理,并将其与通用 RNN(循环神经网络)的概念联系起来。
-
基本结构: 图示了一个按时间步处理序列的过程(从
t=1到t)。它有三个主要部分:- Input tokens (输入标记):
x_1, ...,x_{t-1},x_t,代表按顺序输入的序列元素。 - Hidden state (隐藏状态):
W_0,W_1, ...,W_{t-1},W_t,代表在每个时间步传递的“记忆”或状态。W_0是初始状态。 - Output tokens (输出标记):
z_1, ...,z_{t-1},z_t,代表在每个时间步生成的输出。
- Input tokens (输入标记):
-
与 RNN 的相似之处: 像所有 RNN 一样,当前隐藏状态
W_t依赖于前一个隐藏状态W_{t-1}和当前输入x_t。当前输出z_t则由当前隐藏状态W_t(可能也结合x_t) 决定。 -
TTT 的核心创新 (关键区别):
W_{t-1}上一步的模型权重(即上一个隐藏状态)。
η学习率。
∇ℓ(W_{t-1}; x_t)这是一个 梯度。它是根据当前输入
x_t计算的一个 自监督损失函数ℓ(self-supervised loss),然后对 上一步的权重W_{t-1}求导得到的。
- 隐藏状态是模型权重 (Hidden state is model weights)
TTT 层最关键的思想是,这里的隐藏状态
W_t不再仅仅是一个状态向量,而是代表了一个内部神经网络模型f的权重 (weights)。这就是为什么用W(通常代表权重) 而不是h(通常代表隐藏状态向量) 来表示。 - 更新规则是梯度下降 (Update rule is gradient descent)
隐藏状态的更新方式
W_t = W_{t-1} - η ∇ℓ(W_{t-1}; x_t)不是 传统 RNN 的矩阵运算和激活函数,而是 一步梯度下降。 - 输出规则 (Output rule)
输出
z_t = f(x_t; W_t)是使用 刚刚更新过的模型f(其权重为W_t) 对当前输入x_t进行预测(或处理)得到的结果。
所有 RNN 层都可以看作是一个根据更新规则进行转换的隐藏状态。
TTT 的关键思想是:让隐藏状态本身成为一个带有权重 W 的模型 f,并且 更新规则是在自监督损失 ℓ 上进行的一步梯度下降。
因此,在一个测试序列上更新隐藏状态,就 等同于在测试时训练模型 f。
这个过程被称为 测试时训练 (Test-Time Training, TTT),并被编程到 TTT 层中。
与标准 Transformer 的全局注意力(一次性看到所有输入)或局部注意力(只看到一小段)不同,TTT 层像 RNN 一样,按顺序处理输入序列的各个部分。它一步一步地“读”过整个视频序列。所以对时序建模理论上比传统transformer更有优势,RNN本身对时序感知尤其上下文理解就有优势,只是长程依赖的理解比较差,再加上训不大,所以退出了历史舞台,现在页有RWKV和mamba给rnn招魂,所以TTT不是第一个也不是最后一个,毕竟RNN有自己的时序优势,transformer不成。
另外一个非常重要的因素,就说到我们开头聊的算力的问题
核心区别:如何处理长序列(长上下文)
-
我上文之前描述的架构 (理想化的时空 Transformer):
机制依赖于 全局的时空自注意力 (Global Spatiotemporal Self-Attention)。这意味着整个视频序列中的每一个时空块(Token)都可以直接关注(Attend to)所有其他的时空块。
优点理论上能够完美地捕捉所有时空依赖关系。
缺点 (致命)标准自注意力的计算复杂度与序列长度 N 呈 平方关系 (O(N²))。对于一分钟的视频(论文提到可能超过 30 万个 Token),这种平方复杂度的计算成本对于目前的硬件来说是难以承受的,无论是训练还是推理都过于缓慢且消耗内存,基本就不太实现,其实再有卡你也要考虑是否可商用。
-
论文中的架构 (TTT 增强的 Transformer)
局部自注意力(Local Self-Attention)
预训练 Transformer (CogVideo-X) 中的标准自注意力机制被限制 在视频的短的、独立的 3 秒片段 内运行。这使得每个注意力计算的序列长度可控,避免了全局注意力带来的平方复杂度爆炸。
全局测试时训练 (TTT) 层
在局部注意力层之后 插入了新的 TTT 层。这些 TTT 层作用于 整个 由 3 秒片段拼接而成的 完整序列。关键在于,TTT 层的功能类似于高级的 RNN,其计算复杂度与序列长度 N 呈 线性关系 (O(N)),这和memba的思路也差不多。所以它可以利用rnn的这部分优势,节省计算复杂度,可以生成更长的视频。
这么写大家可能有歧义,这不和现在市面上生成的3秒一个视频然后拼接20个视频成1分钟没区别吗?当然不是,处理/生成片段 1 (0-3秒),模型处理(或开始生成)第一个 3 秒片段。在这个过程中,局部注意力处理片段内部细节,同时TTT 层开始建立它的内部状态 W_0(可以想象成对这 3 秒内容的“总结”或“模型理解”)。处理/生成片段 2 (3-6秒),模型接着处理(或生成)第二个 3 秒片段。 它不是独立进行的。局部注意力处理片段 2 的内部细节,但 TTT 层接收了来自片段 1 的状态 W_0,并结合片段 2 的信息,通过自监督学习更新其状态,得到 W_1 (W_1 = W_0 - η ∇_{W_0} ℓ(X_2; W_0))。这意味着,处理片段 2 时,模型“知道”片段 1 发生了什么,这个“知道”就编码在状态 W_0 里,并影响着 W_1 的形成以及片段 2 的生成/处理。以此类推,就能实现了局部一致性和全局一致性的完美统一。
优势:时序一致性:因为信息(通过 TTT 层的状态 W)在片段间传递,模型被强制要求保持连贯性。它会倾向于让物体、背景、风格等在片段过渡时保持一致或平滑变化,有记忆: TTT 层提供了跨片段的“记忆”。
类比:就像你写一个故事,写第二段时,你会记得第一段写了什么,并在此基础上继续写,确保情节连贯。或者一个动画师一帧一帧地画,确保动作流畅、人物状态一致。
到此,在transformer层加入了TTT层,对文生视频一致性增强的能力解释,基本就告一段落了。于此同时,其实controlnet的作者张吕敏也发了一个新的技术framepack,他从首帧全程attention的思路来解决长视频一致性的问题(多少有点controlnet的思路),这个技术实现解读下一篇来写



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









