









目录
概述
Prometheus 几乎已成为监控领域的事实标准,它自带高效的时序数据库存储tsdb,可以让单台 Prometheus 能够高效的处理大量的数据,还有友好并且强大的 PromQL 语法,可以用来灵活的查询各种监控数据以及配置告警规则,同时它的 pull 模型指标采集方式被广泛采纳,非常多的应用都实现了 Prometheus 的 metrics 接口以暴露自身各项数据指标让 Prometheus 去采集,很多没有适配的应用也会有第三方 exporter 帮它去适配 Prometheus,所以监控系统我们通常首选用 Prometheus,所以我们的监控系统的方案也都围绕promtheus展开。
why thanos?
首先抛出几个问题:
众所周知,Prometheus 本身只支持单机部署,没有自带支持集群部署,也就不支持高可用以及水平扩容。
那么在多个k8s集群的场景下,必然存在多个prometheus实例,如何聚合多个prometheus的查询,形成统一的监控面板的展示,并且为这些个prometheus提供集中的后端存储就成为了问题。
多容器集群下的prom拆分
一般来说对prometheus的拆分有以下两种情况:
1.k8s集群之间相互隔离,需要在每个集群部署prom实例
2.单个prometheus上存储空间受限,在大规模集群需要监控的情况下,需要通过从服务纬度拆分或者对大规模服务做分片等手段来将大体量服务的监控数据拆分到多个 Prometheus 实例
我们属于前者,但不排除在试点aws eks后的业务大规模扩展,所以在以容器集群为纬度的拆分依旧能支撑这种情况,如果未来出现单个k8s集群的规模特别大的情况,需要在1.的基础上以2.为出发点在集群内部的prometheus进行拆分,因此从拓展性角度来说,对架构能否支撑这种横向扩展也提出了要求。
拆分引入的新问题
对 Prometheus 进行拆分部署,一方面使得 Prometheus 能够实现水平扩容,另一方面也加剧了监控数据落盘的分散程度,使用 Grafana 查询监控数据时我们也需要添加许多数据源,而且不同数据源之间的数据还不能聚合查询,监控页面也看不到全局的视图,造成查询混乱的局面。
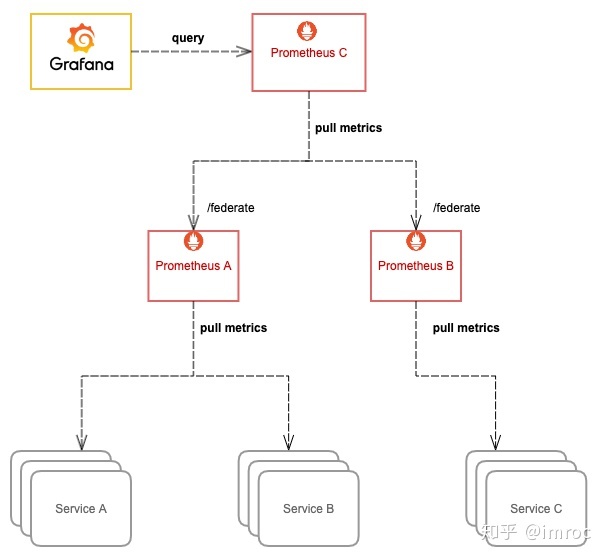
1.一种方法是采用prom集群联邦方案,本质上是采集级联,简单来说,就是将多个 Prometheus 实例采集的数据再用另一个 Prometheus 采集汇总到一起,这样也意味着需要消耗更多的资源。
通常我们只把需要聚合的数据或者需要在一个地方展示的数据用这种方式采集汇总到一起。这种方案适用于大规模集群,比如 Kubernetes 节点数过多,cadvisor 的数据分散在多个 Prometheus 实例上,我们就可以用这种方式将 cadvisor 暴露的容器指标汇总起来,以便于在一个地方就能查询到集群中任意一个容器的监控数据或者某个服务背后所有容器的监控数据的聚合汇总以及配置告警;又或者多个服务有关联,比如通常应用只暴露了它应用相关的指标,但它的资源使用情况(比如 cpu 和 内存) 由 cadvisor 来感知和暴露,这两部分指标由不同的 Prometheus 实例所采集,这时我们也可以用这种方式将数据汇总,在一个地方展示和配置告警。
2.另外一种方法是更换存储引擎,去做集中的数据存储,prometheus官方意识到自己本地存储不具备高可用性,所以通过支持第三方存储来补足这点的手段。
支持的远端存储:
- AppOptics: write
- AWS Timestream: read and write
- Azure Data Explorer: read and write
- Azure Event Hubs: write
- Chronix: write
- Cortex: read and write
- CrateDB: read and write
- Elasticsearch: write
- Gnocchi: write
- Google BigQuery: read and write
- Google Cloud Spanner: read and write
- Graphite: write
- InfluxDB: read and write
- Instana: write
- IRONdb: read and write
- Kafka: write
- M3DB: read and write
- New Relic: write
- OpenTSDB: write
- PostgreSQL/TimescaleDB: read and write
- QuasarDB: read and write
- SignalFx: write
- Splunk: read and write
- Sysdig Monitor: write
- TiKV: read and write
- Thanos: read and write
- VictoriaMetrics: write
- Wavefront: write
我们可以让 Prometheus 不负责存储,仅采集数据并通过 remote write 方式写入远程存储的 adapter,远程存储使用 OpenTSDB 或 InfluxDB 这些支持集群部署的时序数据库,Prometheus 配置:
remote_write: - url: http://10.0.0.2:8888/write然后 Grafana 添加我们使用的时序数据库作为数据源来查询监控数据来展示,架构图:
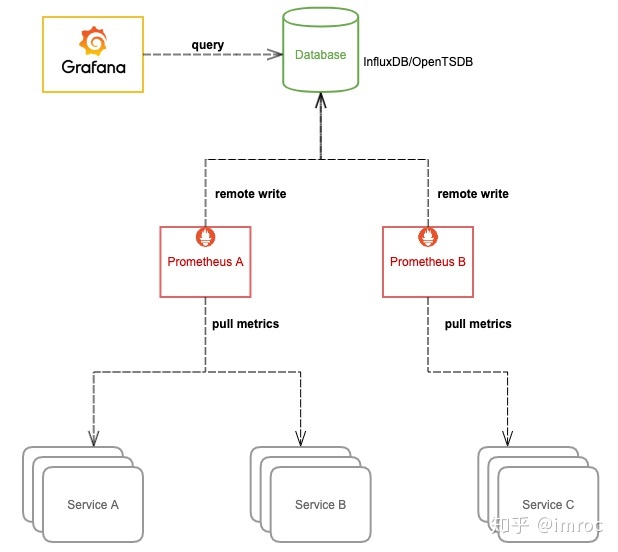
由其它支持存储水平扩容的时序数据库来存储庞大的数据量,这样我们就可以将数据集中到一起。不过这样的话,我们就无法使用友好且强大的 PromQL 来查询监控数据了,必须使用我们存储数据的时序数据库所支持的语法来查询。
k8s下prom的高可用
通过前面的拆分方案将 Prometheus 进行了分布式改造,但并没有解决 Prometheus 本身的高可用问题,即如果其中一个实例挂了,数据的查询和完整性都将受到影响。
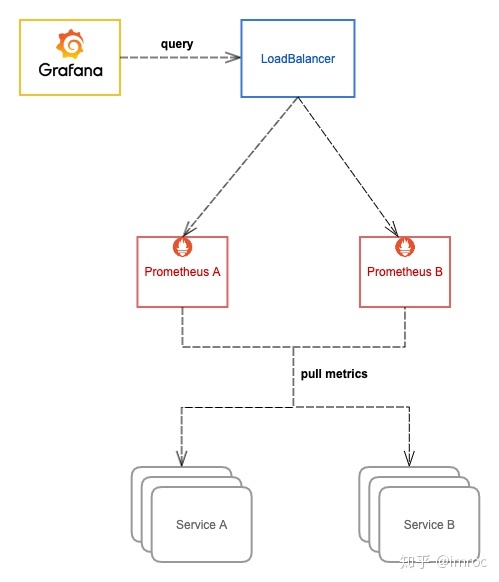
所以可以将所有 Prometheus 实例都使用两个相同副本,分别挂载数据盘,它们都采集相同的服务,所以它们的数据是一致的,查询它们之中任意一个都可以,所以可以在它们前面再挂一层负载均衡,所有查询都经过这个负载均衡分流到其中一台 Prometheus,如果其中一台挂掉就从负载列表里踢掉不再转发。
这里的负载均衡可以根据实际环境选择合适的方案,在 Kubernetes 环境,通常使用 Kubernentes 的 Service,由 kube-proxy 生成的 iptables/ipvs 规则转发。
另外,如果使用 Istio,还可以用 VirtualService,由 envoy sidecar 去转发。
通过以上拆分方案,在一定程度上解决了在多容器集群环境下的需求,但操作和运维复杂度比较高,并且考虑到以后纳管的集群可能扩张,当规模上去后相应的存储压力也会变大,随之而来的就是成本的增加,不能够很好的支持数据的长期存储(long term storage)。对于一些时间比较久远的监控数据,我们通常查看的频率很低,但也希望能够低成本的保留足够长的时间,数据如果全部落盘到磁盘成本是很高的,并且容量有限,即便利用水平扩容可以增加存储容量,但同时也增大了资源成本,不可能无限扩容,所以需要设置一个数据过期策略,也就会丢失时间比较久远的监控数据。
对于这种不常用的冷数据,最理想的方式就是存到廉价的对象存储中,等需要查询的时候能够自动加载出来。Thanos 可以帮我们解决这些问题,它完全兼容 Prometheus API,提供统一查询聚合分布式部署的 Prometheus 数据的能力,同时也支持数据长期存储到各种对象存储以及降低采样率来加速大时间范围的数据查询。
总结一下,就是Thanos 可以帮我们简化分布式 Prometheus 的部署与管理,并提供了一些的高级特性:全局视图,长期存储,高可用。
thanos架构

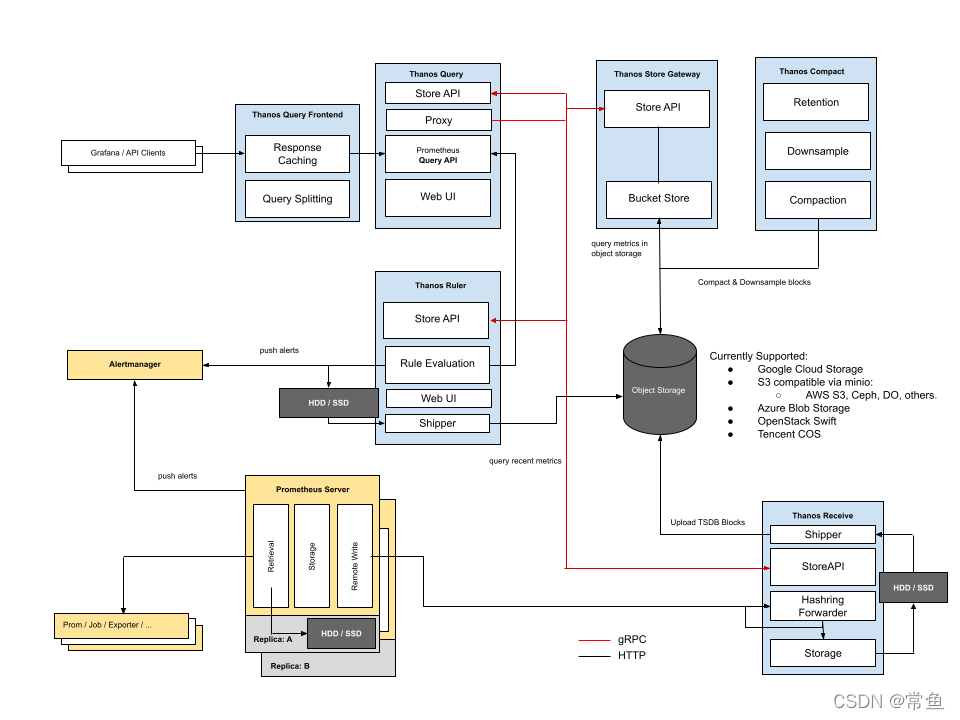
组件
遵循KISS和 Unix 理念,Thanos 由一组组件组成,每个组件都扮演一个特定的角色。
- Sidecar:连接 Prometheus,将其数据提供给 Thanos Query 查询,并且/或者将其上传到对象存储,以供长期存储。
- Store Gateway:在云存储桶内提供指标。
- Compactor:将对象存储中的数据进行压缩和降低采样率,加速大时间区间监控数据查询的速度。
- Receiver:从 Prometheus 的远程写入 WAL 接收数据,将其公开和/或上传到云存储。
- Ruler/Rule:对监控数据进行评估和告警,还可以计算出新的监控数据,将这些新数据提供给 Thanos Query 查询并且/或者上传到对象存储,以供长期存储。
- Querier/Query:实现了 Prometheus API,将来自下游组件提供的数据进行聚合最终返回给查询数据的 client (如 grafana),类似数据库中间件。
- Query Frontend:实现 Prometheus 的 v1 API 代理它到查询,同时缓存响应和可选的查询天分割。
架构的剖析见
Always make sure to run Prometheus as recommended by Prometheus team, so:
- Put Prometheus in the same failure domain. This means same network, same datacenter as monitoring services.
- Use persistent disk to persist data across Prometheus restarts.
- Use local compaction for longer retentions.
- Do not change min TSDB block durations.
- Do not scale out Prometheus unless necessary. Single Prometheus is highly efficient (:
prometheus官方在部署运行上提出了以上要求
1.把prom运行在同一个数据中心
2.使用持久盘
3.采用本地压缩策略
4.不要修改tsdb最小块
5.不要横向扩展prom
thanos的最佳实践
thanos官方提供了不同架构的两种模式:sidecar和receiver模式
这里说一下题外话,除了 Thanos 之外,还有一个名为 Cortex 的开源项目也是一种比较流行的解决 Prometheus 不足的解决方案,Thanos 最初只支持 sidecar 的安装模式,而 Cortex 更喜欢基于 push 或者远程写的方式来收集指标数据,但早在2019年,这两个项目其实就进行了合作,在互相学习之后,Thanos 引入了 Receiver 组件,而 Cortex 的块存储则也构建在了几个核心的 Thanos 组件之上。
经过两年的维护后,thanos的receiver组件也已渐渐成熟,官方也已经将receiver模式的架构纳入到快速上手文档中。
Thanos - Highly available Prometheus setup with long term storage capabilities
Thanos Sidecar模式
为了实现高可用性,多个 Prometheus 实例与 Sidecar 组件一起运行,这些 Prometheus 实例都从目标上独立抓取指标,默认情况下,抓取的 TSDB 块数据块被存储在 Prometheus 提供的持久化卷中。
此外 Sidecar 在 Prometheus 的远程读 API 之上实现了 Thanos 的 Store API,从而可以从 Thanos Querier 组件中去查询 Prometheus 中的时间序列数据,此外,Sidecar 还可以配置为每隔两小时将 TSDB 块上传到对象存储,每两小时创建一次块,存储在 Bucket 桶中的数据可以使用 Thanos Store 组件进行查询,这同样实现了 Store API,都可以被 Thanos Querier 发现。
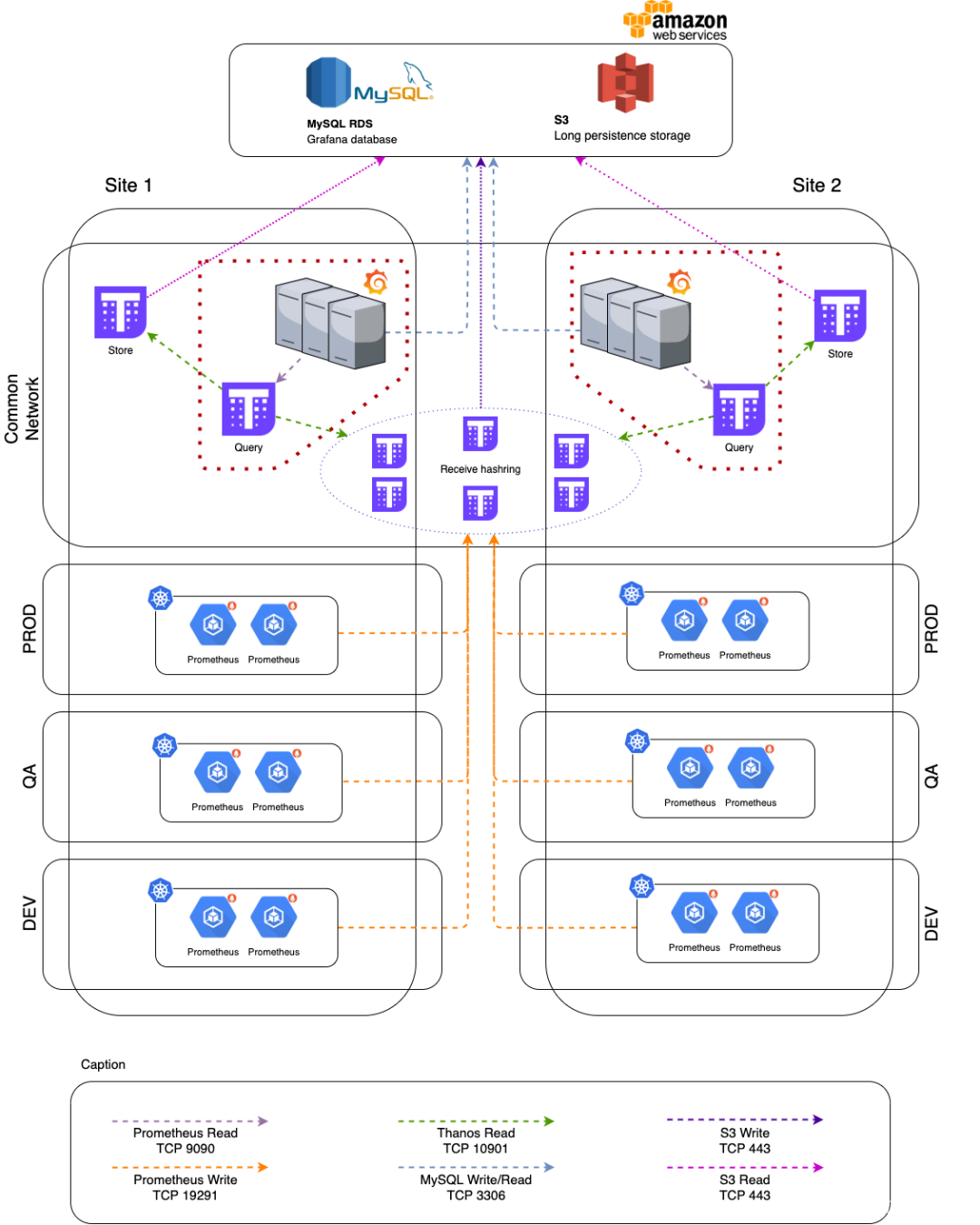
Thanos Receiver模式
Receiver 组件实现了 Prometheus 的远程写 API,直接接收 Prometheus 的数据,Receiver 将数据上传到对象存储 Bucket 中去,并且也有自己的保留期,Querier 被配置为通过 Store 查询 Receiver 和存储桶上的数据。
我找了个一张更清晰明了的图片来帮助理解。
参考
receiver
使用 Thanos+Prometheus+Grafana 打造监控系统 - 云+社区 - 腾讯云
sidecar
打造云原生大型分布式监控系统(三): Thanos 部署与实践 - 知乎
如何使用 Thanos 实现 Prometheus 多集群监控 - 知乎
如何选择
sidecar模式和receiver模式的选择
- 如果你的 Query 跟 Sidecar 离的比较远,比如 Sidecar 分布在多个数据中心,Query 向所有 Sidecar 查数据,速度会很慢,这种情况可以考虑用 Receiver,将数据集中吐到 Receiver,然后 Receiver 与 Query 部署在一起,Query 直接向 Receiver 查最新数据,提升查询性能。
- 如果你的使用场景只允许 Prometheus 将数据 push 到远程,可以考虑使用 Receiver。比如 IoT 设备没有持久化存储,只能将数据 push 到远程。
此外的场景应该都尽量使用 Sidecar 方案。
选择哪种方案完全取决于要实现的 Prometheus HA 和多租户的环境。在需要为单个集群实现 Prometheus HA 或使用 Prometheus Operator 进行特定应用程序监控的情况下,Sidecar 似乎是一个不错的选择,因为它易于操作和集成轻量。Sidecar 也可以通过分层的 Thanos Querier 方法用于多租户。
而如果需要对多租户进行更集中的查看,或者在只有出流量的网络环境中,则可以在考虑推送指标方式后使用 Receiver,不建议通过 Receiver 实现单租户的全局视图。当试图实现具有不同环境限制的多个租户的全局视图时,可以采用同时使用 Sidecar 和 Receiver 的混合方法。
下一章我将详细介绍这套监控方案的实战,聊聊如何部署和使用thanos。


















 2290
2290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











