







elasticsearch系列文章
深入elasticsearch(一):搭建elasticsearch环境及安装elasticsearch_head插件
深入elasticsearch(二):springboot通过jestClient操作es
es选主流程源码解析
es采用类Bully算法来当做主节点选举的算法,同时避免了当发生网络分区等异常情况下出现脑裂的问题。
Bully算法:
Leader选举的基本算法之一。它假定所有节点都有一个唯一的ID,使用该ID对节点进行排序。任何时候,当前的Leader都是节点中ID最高的那个。该算法实现简单,但当Leader节点网络故障或者不稳定时会有问题。比如,Master负载过重假死,集群选举第二大的ID为Leader,这时原来的Master恢复,再次被选为新主,然后再循环。。。
ES通过推迟选举,直到当前的Master失效后才重新选举,当前Master不失效,就不重新选主,但是这样容易产生脑裂,所以,又通过一个法定得票人数参数配置来解决脑裂问题。
选主流程主要位于ZenDiscovery中,主要为:
- 选举临时Master,如果本节点当选,则等待其他节点确认Master
- 如果其他节点当选,则尝试加入集群,然后启动节点失效探测。
主要源码在ZenDiscovery#innerJoinCluster中,选举临时Master的代码在**findMaster()**中,我们从选举临时Master开始分析
选举临时Master
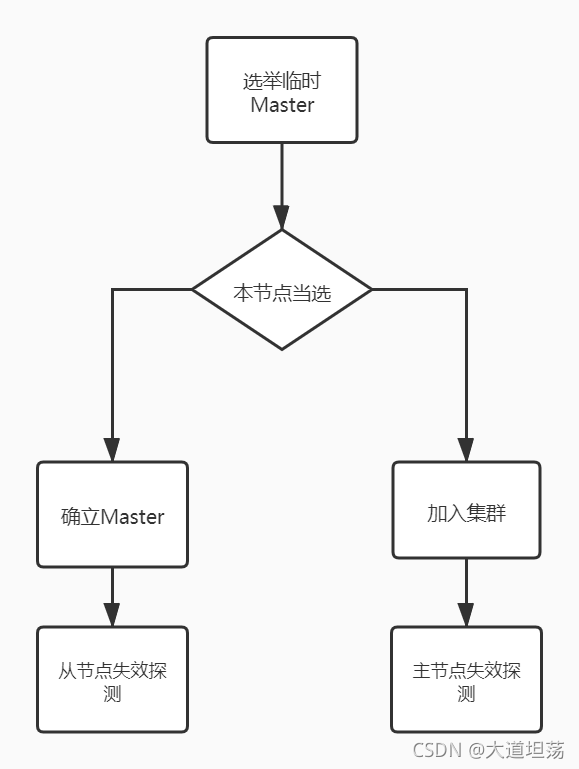
结合图片顺着顺序来看代码:
private DiscoveryNode findMaster() {
logger.trace("starting to ping");
//获取所有节点列表(不包含自己)
List<ZenPing.PingResponse> fullPingResponses = pingAndWait(pingTimeout).toList();
if (fullPingResponses == null) {
logger.trace("No full ping responses");
return null;
}
if (logger.isTraceEnabled()) {
StringBuilder sb = new StringBuilder();
if (fullPingResponses.size() == 0) {
sb.append(" {none}");
} else {
for (ZenPing.PingResponse pingResponse : fullPingResponses) {
sb.append("\n\t--> ").append(pingResponse);
}
}
logger.trace("full ping responses:{}", sb);
}
final DiscoveryNode localNode = clusterService.localNode();
// add our selves
assert fullPingResponses.stream().map(ZenPing.PingResponse::node)
.filter(n -> n.equals(localNode)).findAny().isPresent() == false;
//单独添加当前节点到节点列表里
fullPingResponses.add(new ZenPing.PingResponse(localNode, null, clusterService.state()));
// 通过masterElectionIgnoreNonMasters参数来判断是否忽略没有候选资格的节点
final List<ZenPing.PingResponse> pingResponses = filterPingResponses(fullPingResponses, masterElectionIgnoreNonMasters, logger);
//活动主节点列表,一般为1或者null
List<DiscoveryNode> activeMasters = new ArrayList<>();
for (ZenPing.PingResponse pingResponse : pingResponses) {
// 添加除了自己以外的所有主节点到activeMasters里
if (pingResponse.master() != null && !localNode.equals(pingResponse.master())) {
activeMasters.add(pingResponse.master());
}
}
// 有竞选主节点资格的节点列表
List<ElectMasterService.MasterCandidate> masterCandidates = new ArrayList<>();
for (ZenPing.PingResponse pingResponse : pingResponses) {
if (pingResponse.node().isMasterNode()) {
masterCandidates.add(new ElectMasterService.MasterCandidate(pingResponse.node(), pingResponse.getClusterStateVersion()));
}
}
//如果当前没有存活节点,则有资格的候选节点开始进行选举
if (activeMasters.isEmpty()) {
// 判断是否满足最小节点数设置 discovery_zen_minmum_master_nodes 配置的值,如果值小于1,直接返回true,否则判断候选节点数是否满足配置。
if (electMaster.hasEnoughCandidates(masterCandidates)) {
//满足条件后开始正式的选举过程
final ElectMasterService.MasterCandidate winner = electMaster.electMaster(masterCandidates);
logger.trace("candidate {} won election", winner);
return winner.getNode();
} else {
return null;
}
} else {
assert !activeMasters.contains(localNode) : "local node should never be elected as master when other nodes indicate an active master";
// lets tie break between discovered nodes
return electMaster.tieBreakActiveMasters(activeMasters);
}
}
static List<ZenPing.PingResponse> filterPingResponses(List<ZenPing.PingResponse> fullPingResponses, boolean masterElectionIgnoreNonMasters, Logger logger) {
List<ZenPing.PingResponse> pingResponses;
if (masterElectionIgnoreNonMasters) {
pingResponses = fullPingResponses.stream().filter(ping -> ping.node().isMasterNode()).collect(Collectors.toList());
} else {
pingResponses = fullPingResponses;
return pingResponses;
}
public boolean hasEnoughCandidates(Collection<MasterCandidate> candidates) {
if (candidates.isEmpty()) {
return false;
}
if (minimumMasterNodes < 1) {
return true;
}
assert candidates.stream().map(MasterCandidate::getNode).collect(Collectors.toSet()).size() == candidates.size() :
"duplicates ahead: " + candidates;
return candidates.size() >= minimumMasterNodes;
}
public MasterCandidate electMaster(Collection<MasterCandidate> candidates) {
assert hasEnoughCandidates(candidates);
List<MasterCandidate> sortedCandidates = new ArrayList<>(candidates);
sortedCandidates.sort(MasterCandidate::compare);
return sortedCandidates.get(0);
}
临时Master的选举流程如下:
-
获取所有节点列表fullPingResponses(不包含自己),最后单独把自己加入到fullPingResponses中。
-
过滤fullPingResponses,如果discovery.zen.master_election.ignore_non_master_pings参数设置为true的则过滤掉没有候选Master资格的节点,默认是false。
-
构建两个节点列表:
- activeMasters列表:存储存活主节点列表,遍历fullPingResponses,将每个节点认为的主节点(不包含自己)加入到activeMasters中。
为什么不把 自己加入到节点列表是因为防止在没有其他节点的情况下自行选举。 - masterCandidates:把所有有候选资格的节点加入到masterCandidates中。
4.如果activeMasters为空,则从masterCandidates开始选举,选举成功返回选举好的节点,不成功返回空,如果activeMasters不为空,则直接从activeMasters选取版本号最大、id最小的节点充当临时主节点。

- activeMasters列表:存储存活主节点列表,遍历fullPingResponses,将每个节点认为的主节点(不包含自己)加入到activeMasters中。
以下代码是当发生选举时依赖的排序规则 compare()是选举中的排序规则方法,从代码中可以看出,当存在多个候选节点数据时是根据版本号,和nodeId来进行选择的。
public static int compare(MasterCandidate c1, MasterCandidate c2) {
// we explicitly swap c1 and c2 here. the code expects "better" is lower in a sorted
// list, so if c2 has a higher cluster state version, it needs to come first.
int ret = Long.compare(c2.clusterStateVersion, c1.clusterStateVersion);
if (ret == 0) {
ret = compareNodes(c1.getNode(), c2.getNode());
}
return ret;
}
确立Master或者加入集群
当临时节点Master选举出来后, 有两个分支:
- 当前节点被选举成临时主节点
- 当前节点不是临时主节点。
当前节点被选举成临时主节点
private void innerJoinCluster() {
DiscoveryNode masterNode = null;
final Thread currentThread = Thread.currentThread();
nodeJoinController.startElectionContext();
while (masterNode == null && joinThreadControl.joinThreadActive(currentThread)) {
//获取临时节点
masterNode = findMaster();
}
if (!joinThreadControl.joinThreadActive(currentThread)) {
return;
}
if (clusterService.localNode().equals(masterNode)) {
//满足选举成功的最小投票节点数,electMaster.minimumMasterNodes()-1 是因为当前节点已经成为候选节点了
final int requiredJoins = Math.max(0, electMaster.minimumMasterNodes() - 1);
// 等到足够多投票人数或者超时进行下一轮选举
nodeJoinController.waitToBeElectedAsMaster(requiredJoins, masterElectionWaitForJoinsTimeout,
new NodeJoinController.ElectionCallback() {
@Override
public void onElectedAsMaster(ClusterState state) {
joinThreadControl.markThreadAsDone(currentThread);
// 启动NodesFD,监控集群内其他节点状态,每隔一秒发送心跳
nodesFD.updateNodesAndPing(state);
}
@Override
public void onFailure(Throwable t) {
//开始新一轮选举
joinThreadControl.markThreadAsDoneAndStartNew(currentThread);
}
}
);
} else {
}
}
public void waitToBeElectedAsMaster(int requiredMasterJoins, TimeValue timeValue, final ElectionCallback callback) {
final CountDownLatch done = new CountDownLatch(1);
final ElectionCallback wrapperCallback = new ElectionCallback() {
@Override
public void onElectedAsMaster(ClusterState state) {
done.countDown();
callback.onElectedAsMaster(state);
}
@Override
public void onFailure(Throwable t) {
done.countDown();
callback.onFailure(t);
}
};
ElectionContext myElectionContext = null;
try {
//选举的核心流程,
synchronized (this) {
assert electionContext != null : "waitToBeElectedAsMaster is called we are not accumulating joins";
myElectionContext = electionContext;
//设置容器选举时基本属性
electionContext.onAttemptToBeElected(requiredMasterJoins, wrapperCallback);
//判断有选举资格的人数是否满足最小选举人数,如果满足,开始准备成为主节点,像集群内提交主节点信息,及发布最新集群状态
checkPendingJoinsAndElectIfNeeded();
}
try {
if (done.await(timeValue.millis(), TimeUnit.MILLISECONDS)) {
return;
}
} catch (InterruptedException e) {
}
// 当该节点30s内没有完成选举,则放弃本轮选举,发布选举失败信息,通知集群内的其他节点开始新一轮临时Master选举
failContextIfNeeded(myElectionContext, "timed out waiting to be elected");
} catch (Exception e) {
logger.error("unexpected failure while waiting for incoming joins", e);
if (myElectionContext != null) {
failContextIfNeeded(myElectionContext, "unexpected failure while waiting for pending joins [" + e.getMessage() + "]");
}
}
}
private synchronized void checkPendingJoinsAndElectIfNeeded() {
assert electionContext != null : "election check requested but no active context";
final int pendingMasterJoins = electionContext.getPendingMasterJoinsCount();
// 接收到的有选举资格的投票数是否满足最少投票数
if (electionContext.isEnoughPendingJoins(pendingMasterJoins) == false) {
//logger
} else {
// 成为主节点,发布集群状态
electionContext.closeAndBecomeMaster();
// 清空选举容器,防止后续再次选举的时候导致累加
electionContext = null;
}
}
当本节点被选为主节点的时候主要执行以下流程:
-
等待其他有候选资格的节点投票,满足最小投票数则成为主节点。
-
如果超时(30s)或者选举时发生异常,则放弃本轮选举,开始进行新一轮选举。
-
选举成功后,发布集群状态,清空选举容器。
-
开启节点失效探测,定期(1s)探测每个节点的状态,当节点个数不满足最小投票数的时候,放弃主节点身份。
当前节点不是主节点
// 停止接受其他节点的join,
nodeJoinController.stopElectionContext(masterNode + " elected");
// 发送join请求到到被认定是临时Master的节点
final boolean success = joinElectedMaster(masterNode);
// 通过集群状态来更新完成连接,在主节点选举的源码中我们知道主节点选举完成之后会更新整个集群的状态,其他从节点就根据集群状态来进行下一步。
final DiscoveryNode finalMasterNode = masterNode;
clusterService.submitStateUpdateTask("finalize_join (" + masterNode + ")", new LocalClusterUpdateTask() {
@Override
public ClusterTasksResult<LocalClusterUpdateTask> execute(ClusterState currentState) throws Exception {
if (!success) {
//集群状态失败,停止当前选举,重新开始下一轮
joinThreadControl.markThreadAsDoneAndStartNew(currentThread);
return unchanged();
}
if (currentState.getNodes().getMasterNode() == null) {
joinThreadControl.markThreadAsDoneAndStartNew(currentThread);
return unchanged();
}
//如果发布集群状态的主节点和期待选举的主节点不一致,则停止当前选举,重新开始选举加入到新的集群里
if (!currentState.getNodes().getMasterNode().equals(finalMasterNode)) {
return joinThreadControl.stopRunningThreadAndRejoin(currentState, "master_switched_while_finalizing_join");
}
joinThreadControl.markThreadAsDone(currentThread);
return unchanged();
}
@Override
public void onFailure(String source, @Nullable Exception e) {
logger.error("unexpected error while trying to finalize cluster join", e);
joinThreadControl.markThreadAsDoneAndStartNew(currentThread);
}
});
// 当收到新的集群状态时,开启对主节点的失效探测链接
private class NewPendingClusterStateListener implements PublishClusterStateAction.NewPendingClusterStateListener {
@Override
public void onNewClusterState(String reason) {
processNextPendingClusterState(reason);
}
}
作为从节点参与选举的这个流程相对来说简单一点,主要分为:
- 停止接收其他节点的join。
- join主节点。
- 当主节点选举完成发布集群状态的时候,通过接收集群状态来完成自己的链接。
唯一需要注意的是,在接收到集群状态的时候,会自动开启对主节点失效探测链接。
节点失效探测
节点失效探测作为触发选举和下线不可用节点必不可少的依据,在es中,分为主节点失效探测NodesFaultDetection,和从节点失效探测MasterFaultDetection。这里我们重点讲述主节点失效探测,因为主节点开启的失效探测机制中包含了现是保证ES不会脑裂的重要功能。
NodesFaultDetection是主节点发布集群状态之后,启动的失效探测实现类,以下代码省略和脑裂不相关的代码
@Override
public ClusterTasksResult<Task> execute(final ClusterState currentState, final List<Task> tasks) throws Exception {
final ClusterState remainingNodesClusterState = remainingNodesClusterState(currentState, remainingNodesBuilder);
final ClusterTasksResult.Builder<Task> resultBuilder = ClusterTasksResult.<Task>builder().successes(tasks);
// 判断当前连通的节点里,剩余有候选资格的节点是否满足最少投票数
if (electMasterService.hasEnoughMasterNodes(remainingNodesClusterState.nodes()) == false) {
// 获取当前有候选资格的节点数
final int masterNodes = electMasterService.countMasterNodes(remainingNodesClusterState.nodes());
// 执行放弃主节点操作
rejoin.accept(LoggerMessageFormat.format("not enough master nodes (has [{}], but needed [{}])",
masterNodes, electMasterService.minimumMasterNodes()));
return resultBuilder.build(currentState);
} else {
return resultBuilder.build(allocationService.deassociateDeadNodes(remainingNodesClusterState, true, describeTasks(tasks)));
}
}
主节点对从节点以每秒探测一次的频率监控集群内节点情况,当某一次节点探测失败时,会触发对当前存活节点的判断,如果小于法定投票人数,则当前主节点会放弃主节点身份,进行下一轮选举。
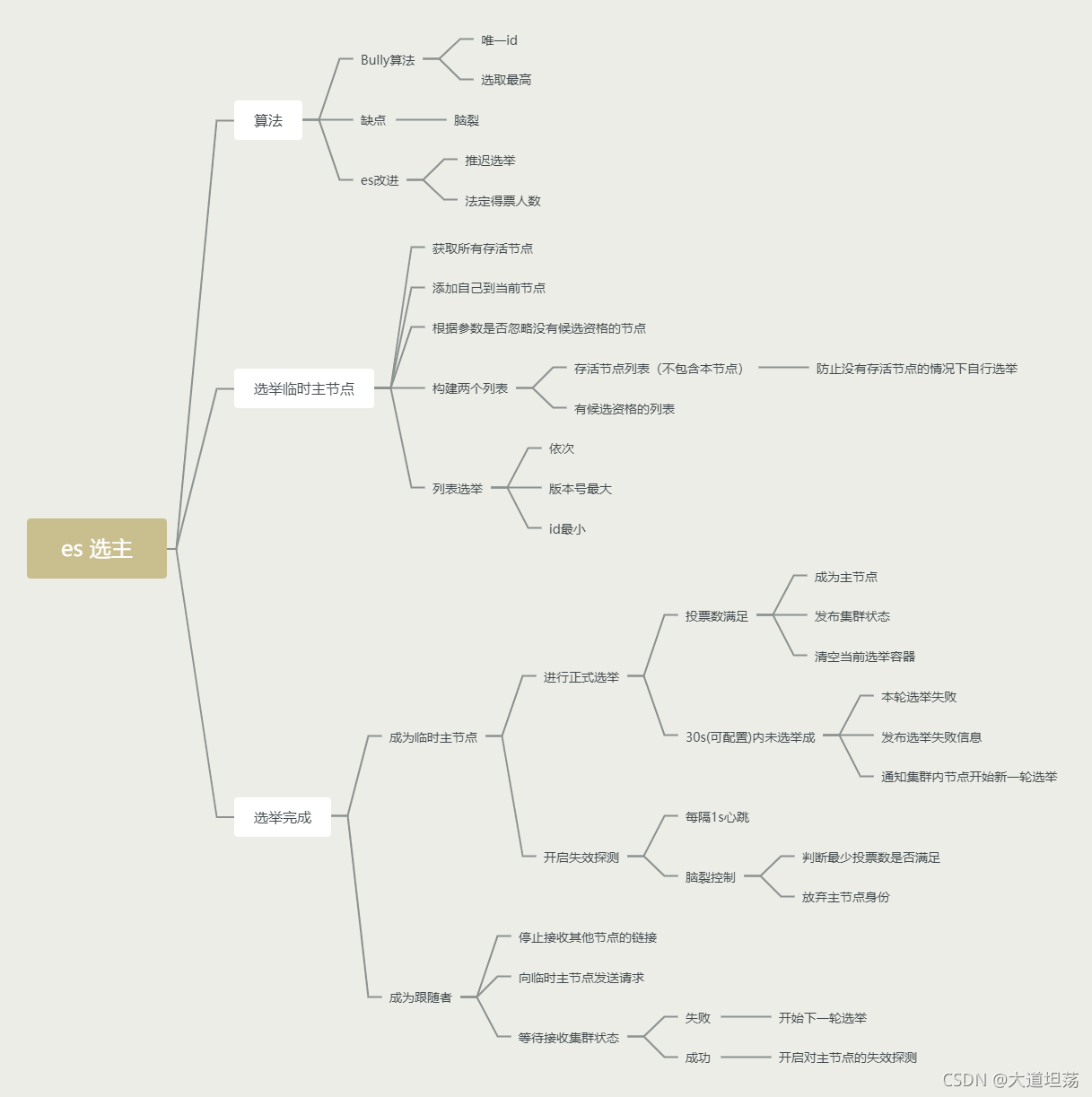
知识谱














 5592
5592











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









