




BiGRU双向门控循环单元分类预测+特征贡献SHAP分析,通过特征贡献分析增强模型透明度,Matlab代码实现,引入SHAP方法打破黑箱限制,提供全局及局部双重解释视角
主要功能
实现基于双向门控循环单元(BiGRU) 的分类模型,用于多类别数据分类,包含完整流程:
- 数据预处理(打乱、分层划分、归一化)
- BiGRU模型构建与训练
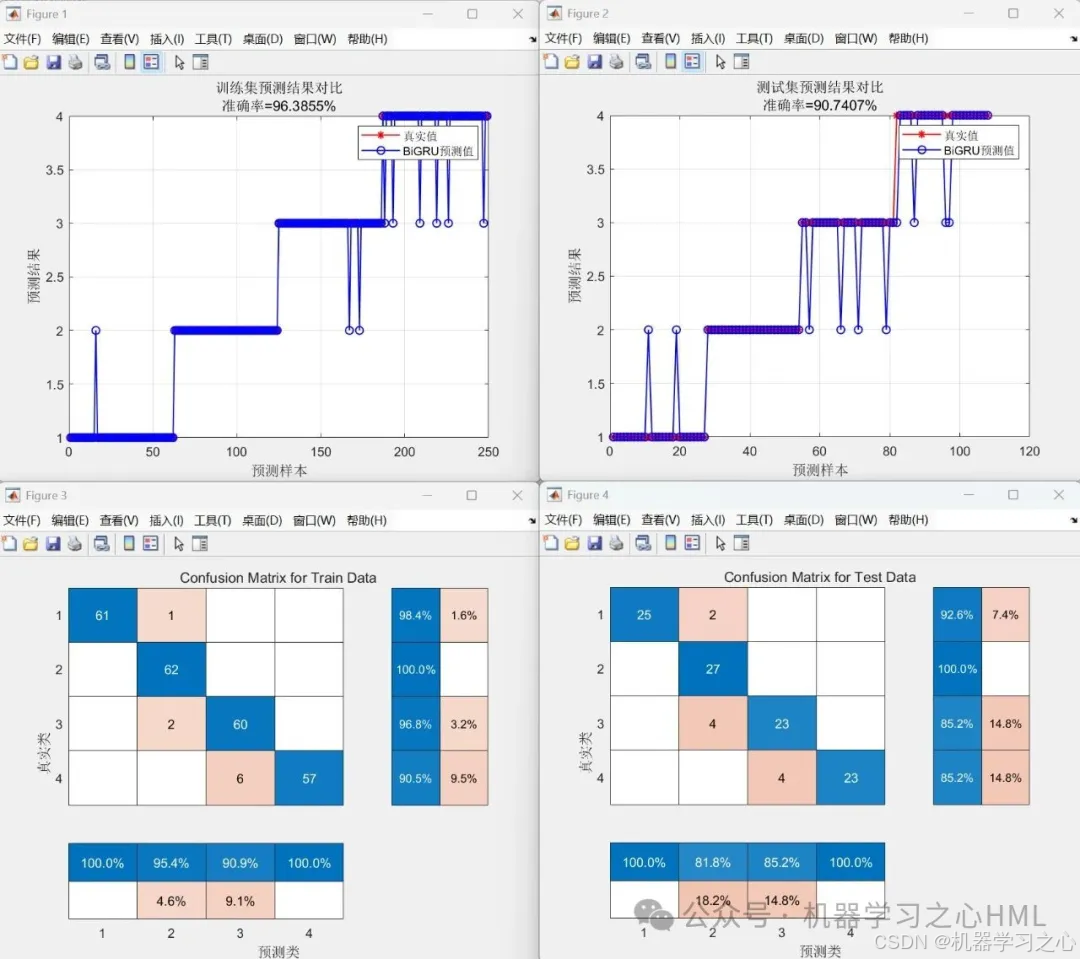
- 性能评估(准确率、混淆矩阵)
- 可解释性分析(SHAP值计算与可视化)
算法步骤
-
数据准备
- 导入Excel数据集(最后一列为类别标签)
- 打乱数据顺序(
randperm) - 分层抽样:按类别比例70%划分训练集/测试集
-
数据预处理
- 归一化特征(
mapminmax到[0,1]区间) - 数据平铺
- 标签转换为分类类型(
categorical)
- 归一化特征(
-
BiGRU模型构建
使用自定义翻转层(FlipLayer) 实现双向序列处理 -
模型训练
- 优化器:Adam(初始学习率0.01)
- 批大小:50
- 最大轮次:100(50轮后学习率减半)
- 监控训练进度
-
预测与评估
- 计算训练/测试集准确率
- 绘制预测结果对比曲线
- 生成混淆矩阵
-
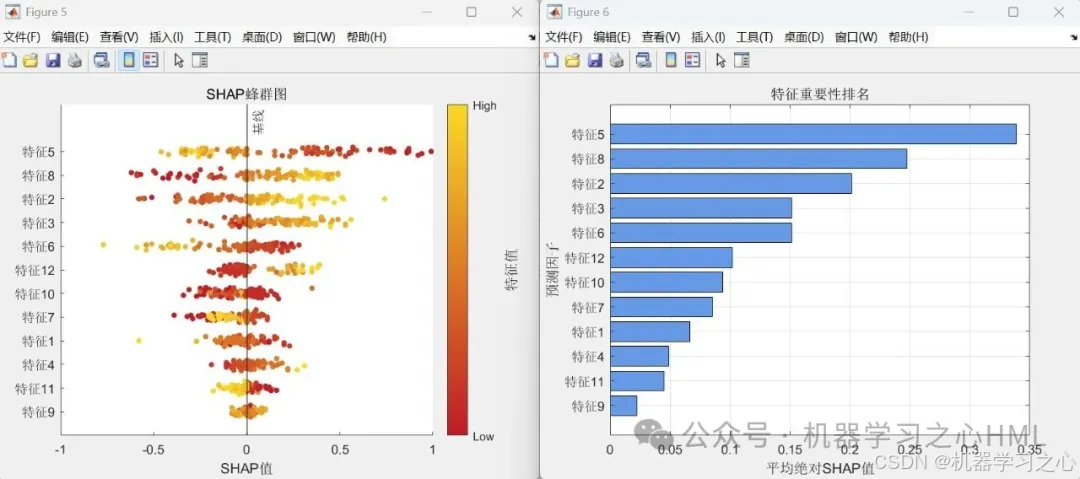
SHAP可解释性分析
- 基于测试样本计算SHAP值
- 生成三图:
- SHAP摘要图(特征重要性分布)
- 特征重要性条形图
- 特征依赖图
技术路线
| 模块 | 关键技术 |
|---|---|
| 数据划分 | 分层抽样(按类别比例拆分) |
| 数据归一化 | mapminmax 动态归一化(保留参数供测试集使用) |
| 网络结构 | 双向GRU + 自定义翻转层 + 特征拼接(Concatenation) |
| 训练优化 | Adam优化器 + 分段学习率下降 + 批训练 |
| 可解释性 | SHAP值计算 |
关键参数设定
| 参数 | 值 | 作用 |
|---|---|---|
num_size | 0.7 | 训练集占比 |
numHiddenUnits | 40 | GRU隐藏层神经元数 |
MiniBatchSize | 50 | 批大小 |
MaxEpochs | 100 | 最大训练轮次 |
InitialLearnRate | 0.01 | 初始学习率 |
LearnRateDropPeriod | 50 | 学习率下降周期 |
LearnRateDropFactor | 0.5 | 学习率下降因子 |
运行环境要求
MATLAB版本:2020b及以上(依赖confusionchart和深度学习工具箱)
应用场景
-
多分类时序问题
- 适用数据维度:
num_dim维时序特征 + 单列类别标签 - 示例场景:
- 信号分类
- 工业设备故障诊断
- 模式识别
- 适用数据维度:
-
模型可解释性需求场景
- 需明确特征贡献度的领域(如医疗诊断、金融风控)
数据集




















 648
648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











