









同一版本的代码用了这么多次,有点过意不去,于是这次我要做较大的改动 ,大家要擦亮眼睛,拭目以待。
,大家要擦亮眼睛,拭目以待。
块并行相当于操作系统中多进程的情况,上节说到,CUDA有线程组(线程块)的概念,将一组线程组织到一起,共同分配一部分资源,然后内部调度执行。线程块与线程块之间,毫无瓜葛。这有利于做更粗粒度的并行。我们将上一节的代码改为块并行版本如下:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
cudaError_t addWithCuda(int *c, const int *a, const int *b, size_t size);
__global__ void addKernel(int *c, const int *a, const int *b)
{
int i = blockIdx.x;
c[i] = a[i] + b[i];
}
int main()
{
const int arraySize = 5;
const int a[arraySize] = { 1, 2, 3, 4, 5 };
const int b[arraySize] = { 10, 20, 30, 40, 50 };
int c[arraySize] = { 0 };
// Add vectors in parallel.
cudaError_t cudaStatus;
int num = 0;
cudaDeviceProp prop;
cudaStatus = cudaGetDeviceCount(&num);
for(int i = 0;i<num;i++)
{
cudaGetDeviceProperties(&prop,i);
}
cudaStatus = addWithCuda(c, a, b, arraySize);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "addWithCuda failed!");
return 1;
}
printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\n",c[0],c[1],c[2],c[3],c[4]);
// cudaThreadExit must be called before exiting in order for profiling and
// tracing tools such as Nsight and Visual Profiler to show complete traces.
cudaStatus = cudaThreadExit();
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaThreadExit failed!");
return 1;
}
return 0;
}
// Helper function for using CUDA to add vectors in parallel.
cudaError_t addWithCuda(int *c, const int *a, const int *b, size_t size)
{
int *dev_a = 0;
int *dev_b = 0;
int *dev_c = 0;
cudaError_t cudaStatus;
// Choose which GPU to run on, change this on a multi-GPU system.
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
goto Error;
}
// Allocate GPU buffers for three vectors (two input, one output) .
cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int));
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
// Copy input vectors from host memory to GPU buffers.
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
// Launch a kernel on the GPU with one thread for each element.
addKernel<<<size,1 >>>(dev_c, dev_a, dev_b);
// cudaThreadSynchronize waits for the kernel to finish, and returns
// any errors encountered during the launch.
cudaStatus = cudaThreadSynchronize();
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaThreadSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
goto Error;
}
// Copy output vector from GPU buffer to host memory.
cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
Error:
cudaFree(dev_c);
cudaFree(dev_a);
cudaFree(dev_b);
return cudaStatus;
}
和上一节相比,只有这两行有改变,<<<>>>里第一个参数改成了size,第二个改成了1,表示我们分配size个线程块,每个线程块仅包含1个线程,总共还是有5个线程。这5个线程相互独立,执行核函数得到相应的结果,与上一节不同的是,每个线程获取id的方式变为int i = blockIdx.x;这是线程块ID。
于是有童鞋提问了,线程并行和块并行的区别在哪里?
线程并行是细粒度并行,调度效率高;块并行是粗粒度并行,每次调度都要重新分配资源,有时资源只有一份,那么所有线程块都只能排成一队,串行执行。
那是不是我们所有时候都应该用线程并行,尽可能不用块并行?
当然不是,我们的任务有时可以采用分治法,将一个大问题分解为几个小规模问题,将这些小规模问题分别用一个线程块实现,线程块内可以采用细粒度的线程并行,而块之间为粗粒度并行,这样可以充分利用硬件资源,降低线程并行的计算复杂度。适当分解,降低规模,在一些矩阵乘法、向量内积计算应用中可以得到充分的展示。
实际应用中,常常是二者的结合。线程块、线程组织图如下所示。
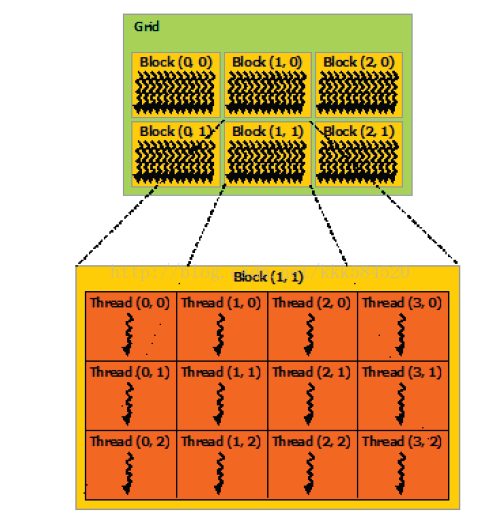
多个线程块组织成了一个Grid,称为线程格(经历了从一位线程,二维线程块到三维线程格的过程,立体感很强啊)。
好了,下一节我们介绍流并行,是更高层次的并行。















 1572
1572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









