






摘要
作者在自动驾驶的场景下提出了一种生成真实世界的对抗样本的方法。作者没有使用传统的DNN分类器作为目标模型而是使用了一些自动驾驶中的导航模型,作者采用的攻击方法的效果应该没有adversarial patch那样直接,但是足以对自动驾驶产生一定的负面影响。
模型

模型由四个部分组成:一个编码器
ε
\varepsilon
ε;一个生成器
g
g
g;一个判别器
D
D
D,和目标模型
f
f
f
- 编码器E代表目标自动驾驶模型f的卷积层,该模型以3D张量为输入,并用于提取视频的特征(原始特征和扰动特征)。
- 生成器 g g g的输入为原始视频片段 X o r i g X_{orig} Xorig经由编码器 ε \varepsilon ε抽取出的特征,输出为对抗样本(道路标识) S a d v S_{adv} Sadv。
- 判别器 D D D的输入为 S a d v S_{adv} Sadv和真实的路标样本 S o r i g S_{orig} Sorig,然后就是GAN的那一套,区分真伪,鼓励生成器生成外观上和真实路标一致的样本。
- 图片里面的mapping说的好听一点就是透视图映射方法,其实就是把原视频里面每一帧上的正方形道路标志的四个角的坐标找出来,然后把生成的 S a d v S_{adv} Sadv按照坐标贴到原视频的每一帧里面去,然后得到生成的视频 X a d v X_{adv} Xadv。
损失函数
- 对抗损失
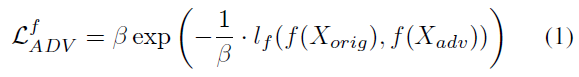
其中 l f l_f lf是一个距离函数m, β \beta β是一个清晰度参数。 - GAN损失
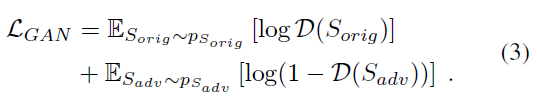
- 最终的目标函数

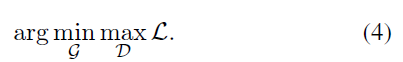
实验
评估的指标没有使用攻击成功率,而是用了自动驾驶导航角度的均方误差和最大误差来评估。
- digital scenarios


- physical-world scenarios

















 436
436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









