






关于BatchSize的一些总结
一、什么是batchsize?
batch(批量),设置batchsize(又简称bs)的目的在于模型训练的过程中每次选择批量的数据进行处理,bs简单理解为一次采样训练的样本数。设置bs的大小与你个人电脑GPU显存有关,bs越大,需求GPU显存越高。
bs的选取直接影响到模型的优化程度以及训练速度
二、为什么需要batchsize?
如果不使用batchsize,每次训练时我们会把全部数据集投入进行训练,小数据集还好,如果是大型数据集,一次载入全部数据可能会内存爆炸。
单次使用全部数据进行训练,得到的梯度下降方向是准确的,但是这种情况下计算得到不同梯度值差别较大,难以使用全局学习率,所以选择使用batchsize来进行单独的梯度更新,这样即使全部数据中包含异常值,也不会对训练造成整体偏差,而是通过bs做局部调整
三、batchsize为何选取2的幂次?
比赛时我们通常不会关心这个问题,因为前人的经验告诉我们选取16,32,64,128等等会提高训练效率,那么为什么要这样选取?
Sebastion Raschka对此的讨论如下:
3.1.内存对齐(理论基础)
由于CPU和GPU的内存架构是以2的幂次进行组织的,或者说,存在一个叫做“内存页”的概念,本质上是一个连续的内存块,然后batchsize为2的幂次时,我们能够方便的将这些批次整齐的放在一个页面上,从而帮助GPU并行处理。这能够做到更好的内存对齐。
简单的来讲,如果内存没有对齐,数据的读取将被编译器拆分为多次操作,这将会降低访存性能。
3.2.矩阵的运算要求(浮点效率)
尽量设置batchsize为8的倍数,由于矩阵运算中,我们通常会用到矩阵乘法,如下两个矩阵A和B相乘时
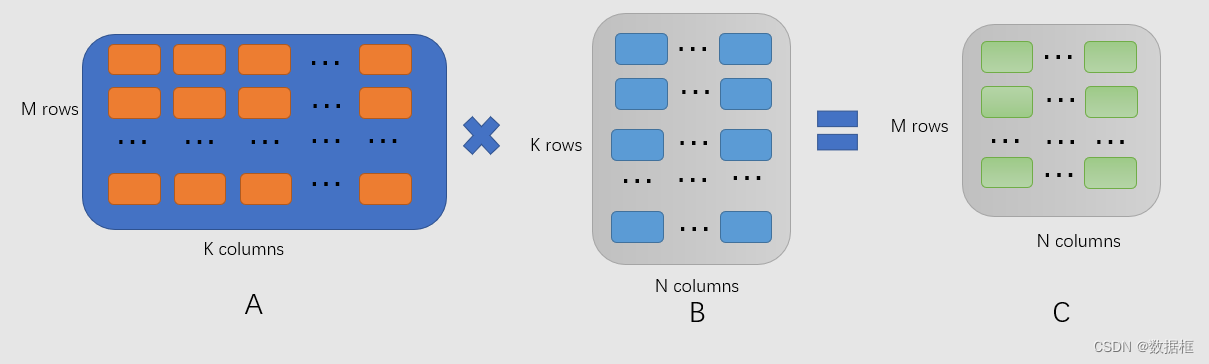
计算A的行向量与B的列向量的点积,每次都由一个 “加” 操作和一个 “乘” 来完成
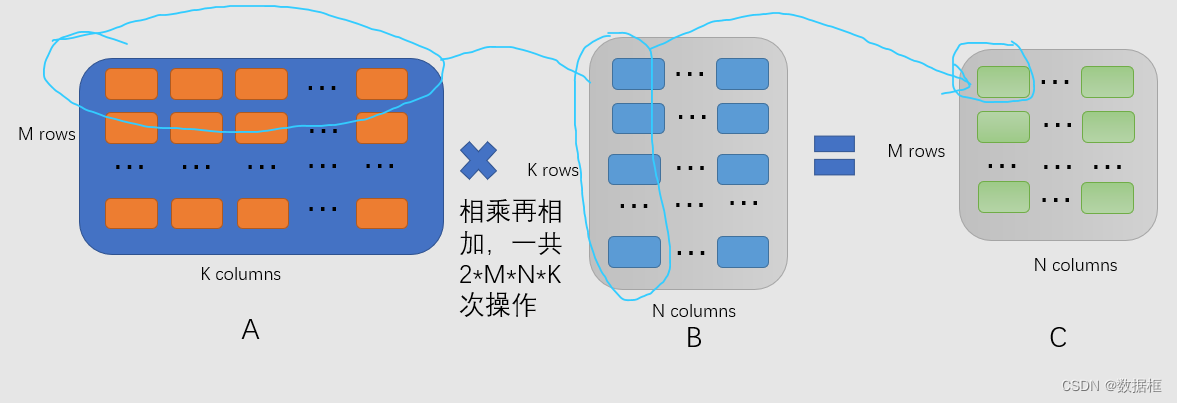
由上图,我们知道一共有2MNK次浮点数运算,当我们在英伟达的GPU上进行FP16混合精度训练的情况下,我们更希望2M满足16的倍数,也即M满足8的倍数,这样效果最佳(N和K由网络架构来决定,而M,也即批次,是由我们自己来决定的超参数),所以我们选择bs时,通常从16,32开始
3.3batchsize的2的幂次总结
不认为选择批大小作为2的幂次或者8的倍数在实践中会产生明显的差异,但是在庞大的超参数选择中,缩小选择的范围,有助于我们去研究网络架构本身,而不是做着从1调到512甚至1024这些看起来玄乎其玄的工作。同时做研究时,我们选择2的幂次而不是随意的选择一些数,这能让我们的研究看起来不像是因为这些小的改动而变得更加精妙。
最佳批大小在很大程度上取决于神经网络架构与损失函数,如果考虑调整超参数作为上分或是科研的重要选择,同时内存限制512批次时,我们可以考虑500而不是256,500的大小也是完全可行的
四、选择大批次好还是小批次好?
4.1 当合理增大批次时
优点
-
内存利用率提高 ,大矩阵乘法的并行化效率提高。
-
单次epoch所需的 迭代次数减少 ,对于相同数据量的处理速度进一步加快。
-
在一定范围内,一般来说 ,Batch_Size 越大,其确定的下降方向越准,引起训练震荡越小。
缺点
1.比较吃GPU显存
2.想要达到相同的精度,batchsize越大,则epoch越多
3.容易收敛到一些local minimum(局部最优)
存在CPU上限
每个epoch的迭代次数以及读取数据是影响时间的关键
大的bs能够减少迭代次数,但是次数减少到一定程度后,由于数据读取的时间较长,进而主要卡在了读取数据,所以大批次不一定能带来速度增益
4.2 当使用小批次时
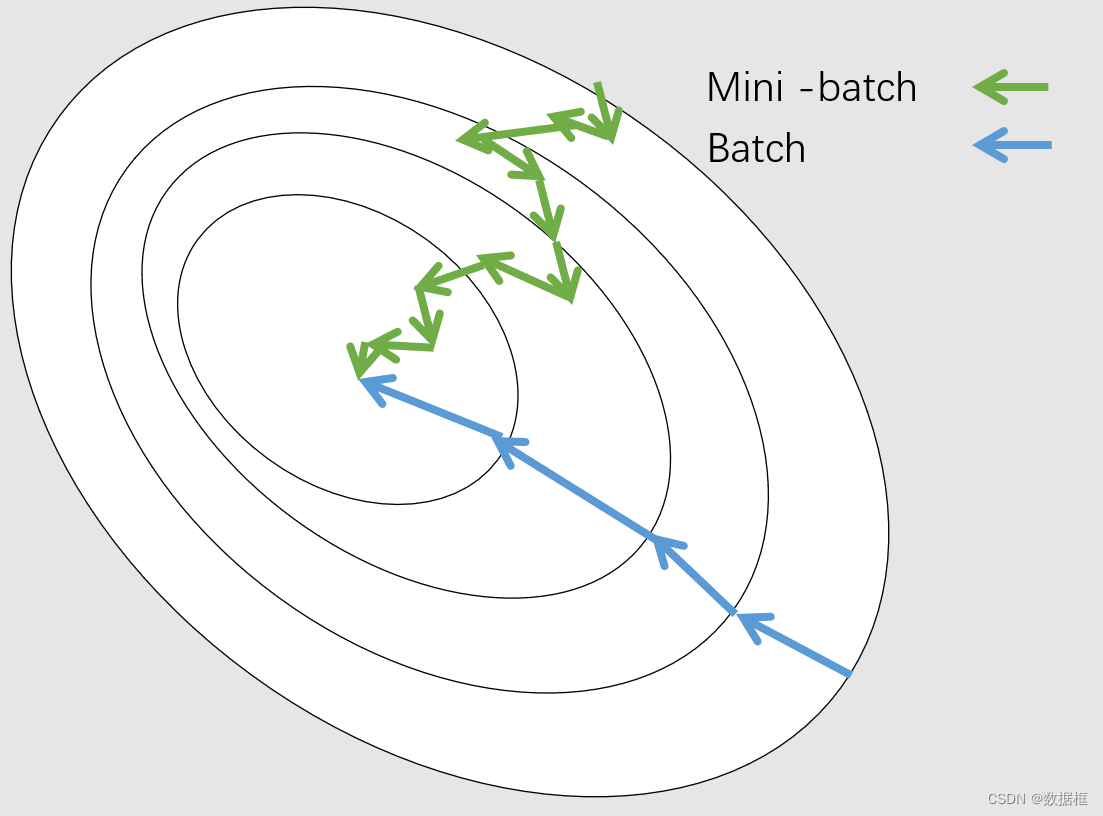
1.如果批次太小,如下图,可能比下图绿色更为严重,每次计算的梯度方向都与上一次偏差较大,横冲直撞,导致难以收敛
2.batchsize太小时,训练速度很慢
batchsize 的正确选择是为了在内存效率和内存容量之间寻找最佳平衡,所以过大和过小都不好
五、batchsize越大为何网络梯度越准确?
我们都知道,对数据进行采样的时候,采样越多,得到的数据越准确,越能代表整体,就还是如同上图,假如我们一次选取一个小的batch,可能会有大的偏差,导致梯度方向不是两点一线的准确方向,而使用大的batchsize对梯度求平均,能更好的代表当前点的梯度方向,从而更加准确。
六、batchsize大小与学习率的关系
batchsize越大,设置学习率也要相应增大,batchsize越小,学习率相应越小,从上图也能看出,小bs迈的步子要小一点,避免跳过最优,大的bs步子大一点,防止训练缓慢(大的bs梯度更准确,不如小的bs那样比较摸瞎,所以大胆走,走的快)
引用:
https://sebastianraschka.com/blog/2022/batch-size-2.html
https://mp.weixin.qq.com/s/kECCkKTWEr5kVpZihP_hew















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









