







两个问题
-
深度学习中batch size的大小对训练过程的影响是什么样的?
-
有些时候不可避免地要用超大batch,比如人脸识别,可能每个batch要有几万甚至几十万张人脸图像,训练过程中超大batch有什么优缺点,如何尽可能地避免超大batch带来的负面影响?
两个问题的回答
batch size的大小影响深度学习训练过程中的完成每个epoch所需的时间和每次迭代(iteration)之间梯度的平滑程度;
对于一个大小为N的训练集,如果每个epoch中mini-batch的采样方法采用最常规的N个样本每个都采样一次,设mini-batch大小为b,那么每个epoch所需的迭代次数(正向+反向)为 N/b , 因此完成每个epoch所需的时间大致也随着迭代次数的增加而增加。
由于目前主流深度学习框架处理mini-batch的反向传播时,默认都是先将每个mini-batch中每个instance得到的loss平均化之后再反求梯度,也就是说每次反向传播的梯度是对mini-batch中每个instance的梯度平均之后的结果,所以b的大小决定了相邻迭代之间的梯度平滑程度,b太小,相邻mini-batch间的差异相对过大,那么相邻两次迭代的梯度震荡情况会比较严重,不利于收敛;b越大,相邻mini-batch间的差异相对越小,虽然梯度震荡情况会比较小,一定程度上利于模型收敛,但如果b极端大,相邻mini-batch间的差异过小,相邻两个mini-batch的梯度没有区别了,整个训练过程就是沿着一个方向蹭蹭蹭往下走,很容易陷入到局部最小值出不来。
总结下来:batch size过小,花费时间多,同时梯度震荡严重,不利于收敛;batch size过大,不同batch的梯度方向没有任何变化,容易陷入局部极小值。
实验不同batch下MNIST分类模型
-
迭代速度
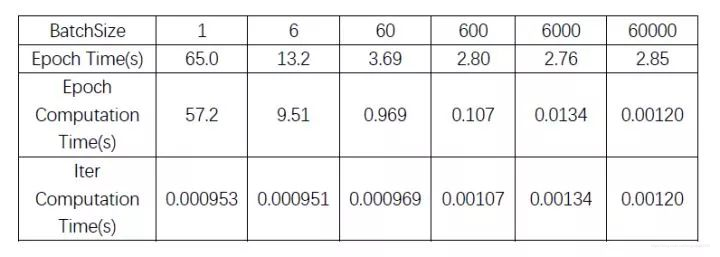
完成每个epoch运算的所需的全部时间主要卡在:1. load数据的时间,2. 每个epoch的iter数量。因此对于每个epoch,不管是纯计算时间还是全部时间,大体上还是大batch能够更节约时间一点,但随着batch增大,iter次数减小,完成每个epoch的时间更取决于加载数据所需的时间,此时也不见得大batch能带来多少的速度增益了。 -
梯度平滑程度
我们再来看一下不同batch size下的梯度的平滑程度,我们选取了每个batch size下前1000个iter的loss,来看一下loss的震荡情况
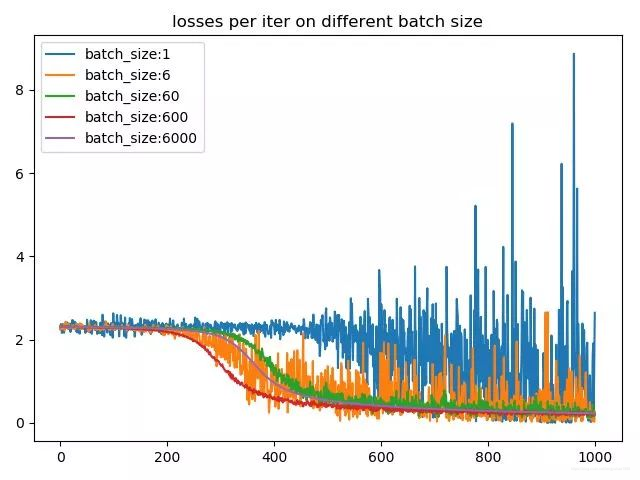
由于现在绝大多数的框架在进行mini-batch的反向传播的时候,默认都是将batch中每个instance的loss平均化之后在进行反向传播,所以相对大一点的batch size能够防止loss震荡的情况发生。从这两张图中可以看出batch size越小,相邻iter之间的loss震荡就越厉害,相应的,反传回去的梯度的变化也就越大,也就越不利于收敛。同时很有意思的一个现象,batch size为1的时候,loss到后期会发生爆炸,这主要是lr=0.02设置太大,所以某个异常值的出现会严重扰动到训练过程。这也是为什么对于较小的batchsize,要设置小lr的原因之一,避免异常值对结果造成的扰巨大扰动。而对于较大的batchsize,要设置大一点的lr的原因则是大batch每次迭代的梯度方向相对固定,大lr可以加速其收敛过程。
- 收敛速度
衡量不同batch size在同样参数下的收敛速度快慢
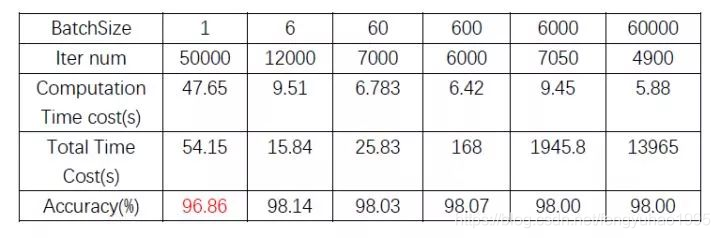
下表中可以看出,在minst数据集上,从整体时间消耗上来看(考虑了加载数据所需的时间),同样的参数策略下 (lr = 0.02, momentum=0.5 ),要模型收敛到accuracy在98左右,batchsize在 6 - 60 这个量级能够花费最少的时间,而batchsize为1的时候,收敛不到98;batchsize过大的时候,因为模型收敛快慢取决于梯度方向和更新次数,所以大batch尽管梯度方向更为稳定,但要达到98的accuracy所需的更新次数并没有量级上的减少,所以也就需要花费更多的时间(可能需要提前终止策略)
不过单纯从计算时间上来看,大batch还是可以很明显地节约所需的计算时间的
介绍一下学习率的自动调整
学习率增加能加快收敛速度,但是过高的学习率会导致梯度变动大
期望的学习率应该是前面大后面小
介绍一个根据Validate上的指标自动减小学习率的算法
torch.optim.lr_scheduler.ReduceLROnPlateau
在发现给定的loss不再降低或者acc不再提高之后,降低学习率
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, verbose=False, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08)
Args:
optimer: 网络的优化器
mode (str): 可选择‘min’或者‘max’,min表示当监控量停止下降的时候,学习率将减小,max表示当监控量停止上升的时候,学习率将减小。默认值为‘min’
factor: 学习率每次降低多少,new_lr = old_lr * factor
patience=10: 容忍网路的性能不提升的次数,高于这个次数就降低学习率
verbose(bool): 如果为True,则为每次更新向stdout输出一条消息。 默认值:False
threshold(float): 测量新最佳值的阈值,仅关注重大变化。 默认值:1e-4
cooldown: 减少lr后恢复正常操作之前要等待的时期数。 默认值:0。
min_lr: 学习率的下限
eps: 适用于lr的最小衰减。 如果新旧lr之间的差异小于eps,则忽略更新。 默认值:1e-8。
应用:
>>> optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
>>> scheduler = ReduceLROnPlateau(optimizer, 'min')
>>> for epoch in range(10):
>>> train(...)
>>> val_loss = validate(...)
>>> # Note that step should be called after validate()
>>> scheduler.step(val_loss)
参考
深入剖析深度学习中Batch Size大小对训练过程的影响
Pytorch(0)降低学习率torch.optim.lr_scheduler.ReduceLROnPlateau类
深度学习调参有哪些技巧?

















 3418
3418

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









