






Streamlit
这一节学习使用streamlit搭建前端
首先下载这个包,在你IDE里面也可以
pip install streamlit
然后建一个文件,比如就叫helloworld.py,然后写代码进去
对于一个专注于数据科学内容的人来讲,前端仿佛那么遥不可及,所以我们应该第一步就做出一些尝试,这能很好的增强我们的信心,以及让我们更好的熟悉流程
我始终认为不管做什么,自己上手跑一遍是一个良好的开端,哪怕所有的代码看起来都如此复杂,所以,为了让自己没那么困,我们跑的第一个代码有必要“大道至简”。
import streamlit as st
st.set_page_config(page_title="Hello Streamlit") # 页名
st.title('This is your first Streamlit page!') # 标题
我们在终端跑一下
streamlit run helloworld.py
可以看到截图如下
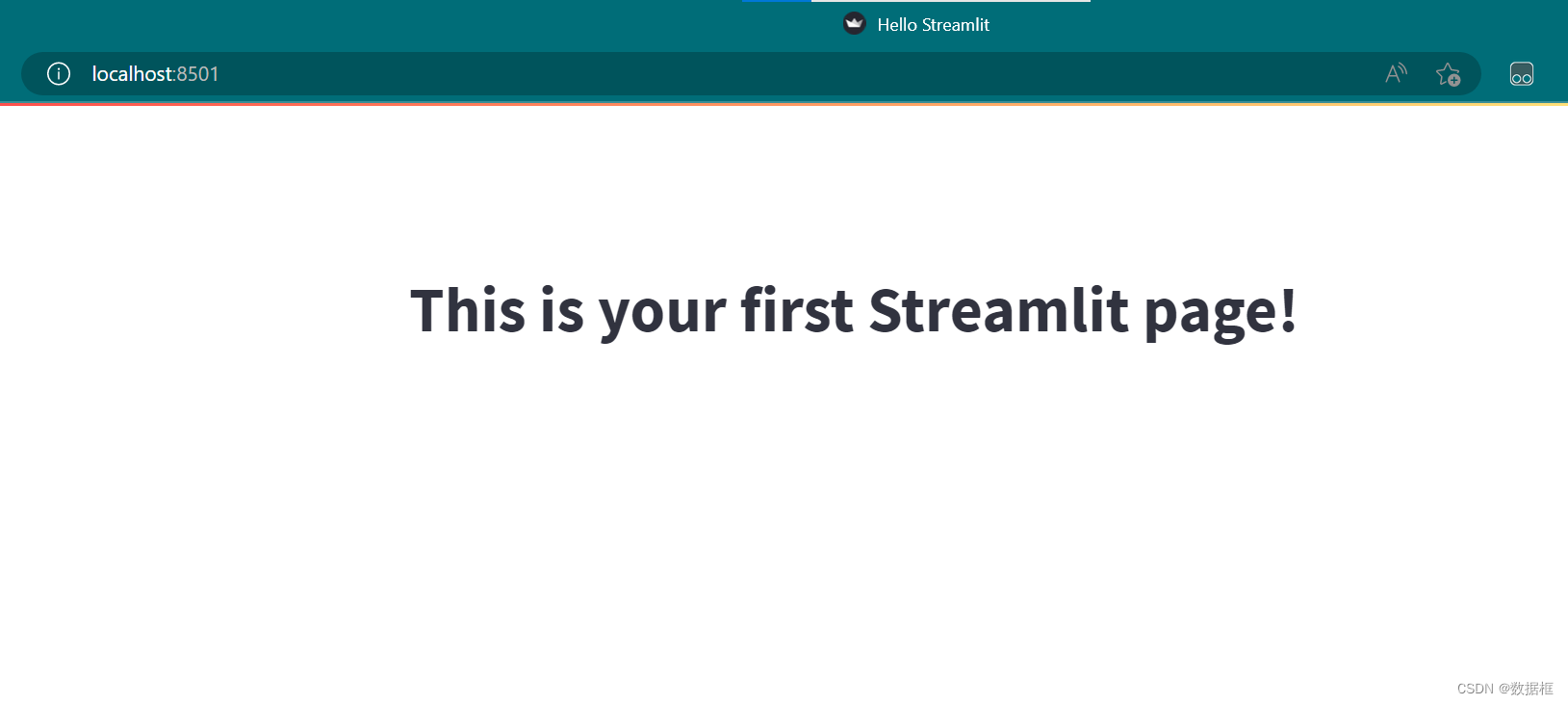
确实是非常简单,我们可以看到这是个网页,我们设置了页名和文章标题名字
所以我们接下来做什么?
谨记、不要局限于大部头字典,我们永远也学不会所有知识,我们只需要靠大脑记住常用的东西,或者说方法而并非知识,这就像是一个文件夹,我们只需要知道如何打开它,知识就触手可及
所以我们好歹定一个目标
比如,我想在上面上传一些数据,可以用作登记信息,思路开阔一些,做一个疫情登记表如何?
为此我们需要定下一个结构,以包含所有的工程
- 姓名
- 性别
- 年龄
- 今天是否做过核酸
我们简单构想这些功能,这就是一个框架,现在我们列出每一项功能要怎么做
我需要:
- 输入(姓名)
- 选择(性别、是否做核酸、年龄)
- 点击按钮(提交)
其他的就是装饰了
现在我们访问它的文档Get started - Streamlit Docs
我们可以在官方文档发现很多有趣的东西,只需要点开API referencce,我确保你能快速上手!
现在我们找一找文本输入该怎么做

它真的我哭死,非常好找,点开那个Text input,甚至有时候都不用点开,如果你足够熟悉,只是偶尔需要一点提示,因为这个函数直接写在了图标上!
我们点开它,然后是熟悉的函数API格式,往下有他的例子!!
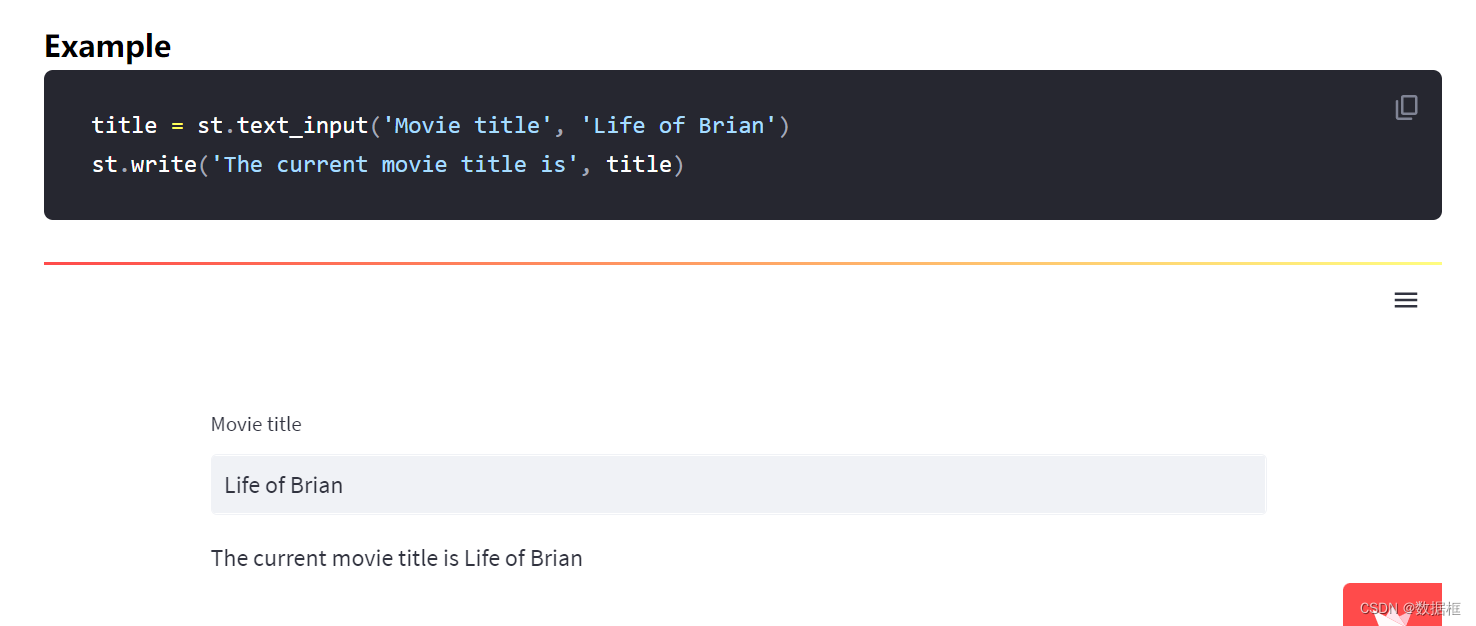
于是我们的应该这么写
name = st.text_input('name', 'please input your name')
下面如法炮制,我们能快速找到我们需要的功能API,包括
- 检查框:
st.checkbox('I agree') - 选择框:
sex = st.selectbox('sex',('man', 'woman')) - 滑动窗口框:
age = st.slider('How old are you?', 0, 130, 25)
代码放在这了
import streamlit as st
st.set_page_config(page_title="Hello Streamlit")
st.title('This is your first Streamlit page!') # 标题
st.write('we will capture your location information.are you agree?')
if st.checkbox('I agree'):
name = st.text_input('name', 'please input your name')
sex = st.selectbox('sex',('man', 'woman'))
age = st.slider('How old are you?', 0, 130, 25)
st.write("I'm ", age, 'years old')
NA = st.selectbox(
'Have you ever done nucleic acid today?',
('yes', 'No'))
st.button('submit')
我们先来看看我们实现了什么
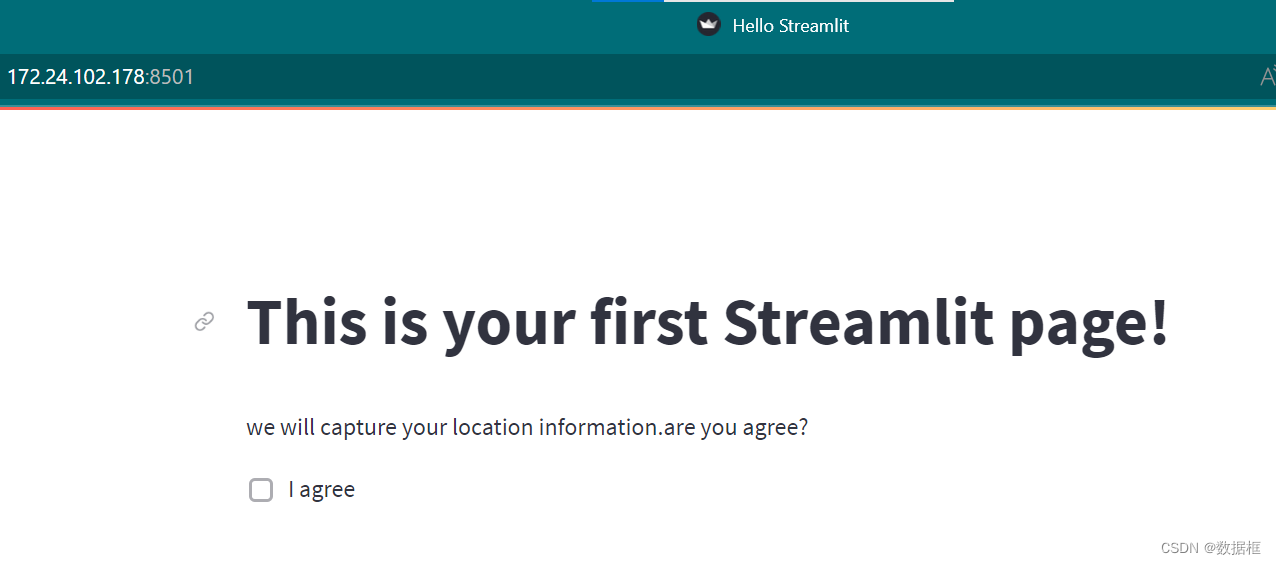
一个检查框,如果我们不勾上它,就没法看到后面的内容
因此我们勾上它(这代表代码里面的if语句生效了,我们能够借此运行后面的代码,更有意思的是,如果我们再次点击这个检查框,它会继续隐藏后续内容,真是一点都不好骗的小家伙)
看看,如此简洁
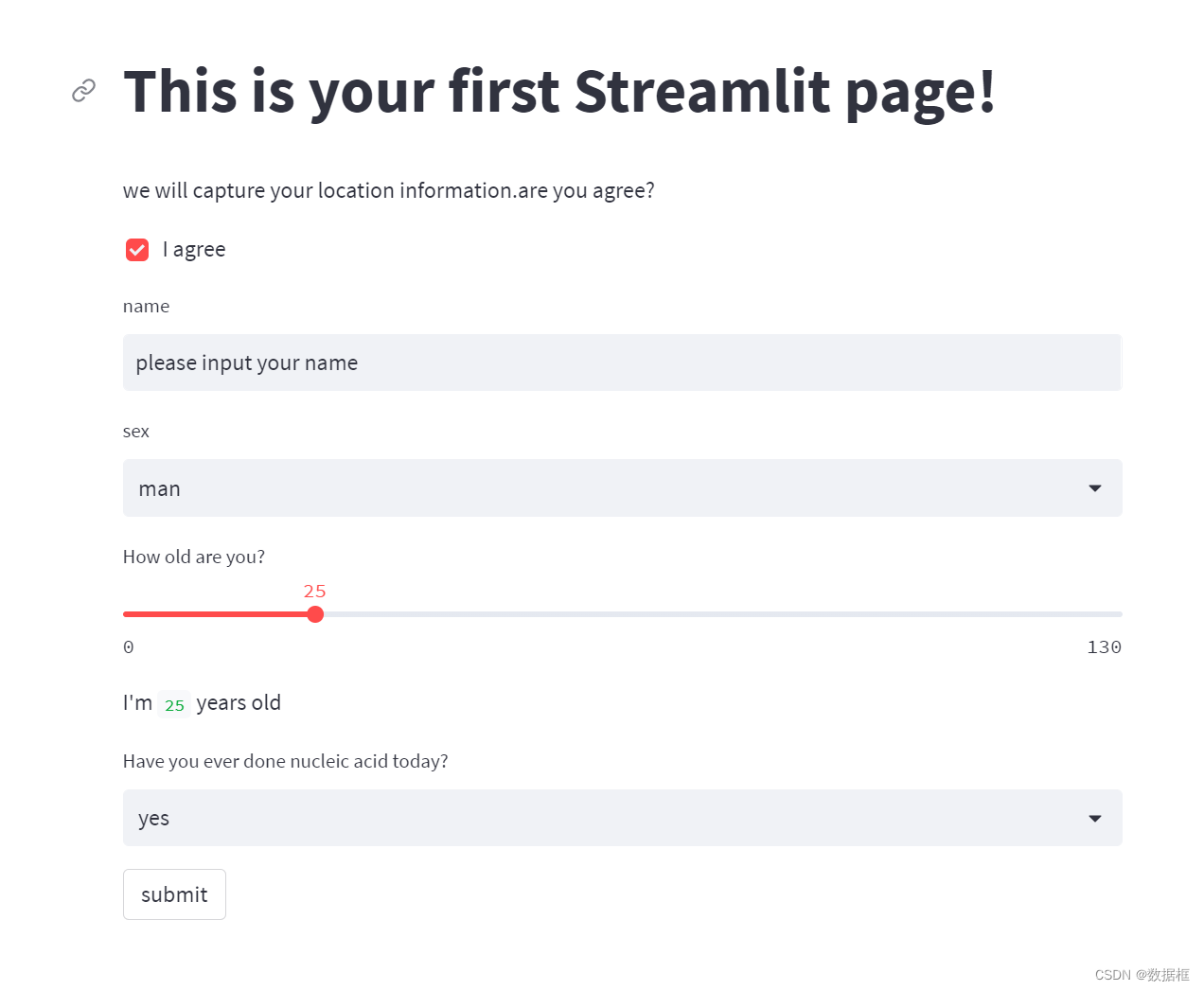
这个选项框可比我经常填的表要好看多了
今天先分享到此
我没有分享应该怎么用streamlit,或者像个字典一样,搬运工,放上许多函数。有时候我们要学会自己去翻文档,你只需要一个翻译软件,比如百度翻译,支持划译,重要的是,亲自动手尝试,自己去做实验,或者说,在做一个东西前,确保目标明确,有逻辑架构,从一而终。
百度有时候无法解决那1%需要你自己实验的任务,所以翻文档吧
下面是VCED前端的代码
VCED前端代码
# 导入需要的包
import streamlit as st
from jina import Client, DocumentArray, Document
import json
import os
import time
import uuid
VIDEO_PATH = f"{os.getcwd()}/data"
# 视频存储的路径
if not os.path.exists(VIDEO_PATH):
os.mkdir(VIDEO_PATH)
# 视频剪辑后存储的路径
if not os.path.exists(VIDEO_PATH + "/videos/"):
os.mkdir(VIDEO_PATH + "/videos")
# GRPC 监听的端口
port = 45679
# 创建 Jina 客户端
c = Client(host=f"grpc://localhost:{port}")
# 设置标签栏
st.set_page_config(page_title="VCED", page_icon="🔍")
# 设置标题
st.title('Welcome to VCED!')
# 视频上传组件
uploaded_file = st.file_uploader("Choose a video")
video_name = None # name of the video
# 判断视频是否上传成功
if uploaded_file is not None:
# preview, delete and download the video
video_bytes = uploaded_file.read()
st.video(video_bytes)
# save file to disk for later process
video_name = uploaded_file.name
with open(f"{VIDEO_PATH}/{video_name}", mode='wb') as f:
f.write(video_bytes) # save video to disk
video_file_path = f"{VIDEO_PATH}/{video_name}"
uid = uuid.uuid1()
# 文本输入框
text_prompt = st.text_input(
"Description", placeholder="please input the description", help='The description of clips from the video')
# top k 输入框
topn_value = st.text_input(
"Top N", placeholder="please input an integer", help='The number of results. By default, n equals 1')
# 根据秒数还原 例如 10829s 转换为 03:04:05
def getTime(t: int):
m,s = divmod(t, 60)
h, m = divmod(m, 60)
t_str = "%02d:%02d:%02d" % (h, m, s)
print (t_str)
return t_str
# 根据传入的时间戳位置对视频进行截取
def cutVideo(start_t: str, length: int, input: str, output: str):
"""
start_t: 起始位置
length: 持续时长
input: 视频输入位置
output: 视频输出位置
"""
os.system(f'ffmpeg -ss {start_t} -i {input} -t {length} -c:v copy -c:a copy -y {output}')
# 与后端交互部分
def search_clip(uid, uri, text_prompt, topn_value):
video = DocumentArray([Document(uri=uri, id=str(uid) + uploaded_file.name)])
t1 = time.time()
c.post('/index', inputs=video) # 首先将上传的视频进行处理
text = DocumentArray([Document(text=text_prompt)])
print(topn_value)
resp = c.post('/search', inputs=text, parameters={"uid": str(uid), "maxCount":int(topn_value)}) # 其次根据传入的文本对视频片段进行搜索
data = [{"text": doc.text,"matches": doc.matches.to_dict()} for doc in resp] # 得到每个文本对应的相似视频片段起始位置列表
return json.dumps(data)
# search
search_button = st.button("Search")
if search_button: # 判断是否点击搜索按钮
if uploaded_file is not None: # 判断是否上传视频文件
if text_prompt == None or text_prompt == "": # 判断是否输入查询文本
st.warning('Please input the description first!')
else:
if topn_value == None or topn_value == "": # 如果没有输入 top k 则默认设置为1
topn_value = 1
with st.spinner("Processing..."):
result = search_clip(uid, video_file_path, text_prompt, topn_value)
result = json.loads(result) # 解析得到的结果
for i in range(len(result)):
matchLen = len(result[i]['matches'])
for j in range(matchLen):
print(j)
left = result[i]['matches'][j]['tags']['leftIndex'] # 视频片段的开始位置
right = result[i]['matches'][j]['tags']['rightIndex'] # 视频片段的结束位置
print(left)
print(right)
start_t = getTime(left) # 将其转换为标准时间
output = VIDEO_PATH + "/videos/clip" + str(j) +".mp4"
cutVideo(start_t,right-left, video_file_path, output) # 对视频进行切分
st.video(output) #将视频显示到前端界面
st.success("Done!")
else:
st.warning('Please upload video first!')















 377
377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









