







在今天的文章中,是需要进行保持登录状态的,如果没有登录状态。会导致xhs博主下的文章数量缺失。
我使用的仍然是selenium远程调试,也就是我之前说的selenium操作已经打开的浏览器。这块内容配置还是挺简单的,大家可以去试试。
今天要实现的功能就是,使用selenium进行获取到xhs指定博主页面下的所有文章链接。
# TODO 实现免登录爬虫
options = Options()
options.add_experimental_option("debuggerAddress", "127.0.0.1:9527")
driver = webdriver.Chrome(options=options)
time.sleep(3)
这块内容就是实现免登录功能,给你三秒钟时间,打开Chrome(你也可以之前打开了)。
url = "https://www.xiaohongshu.com/user/profile/6520e7d10000000024017cfc"
# url = "https://www.xiaohongshu.com/user/profile/6262794f000000002102a1e4"
# 访问某个网页
driver.get(url)
driver.maximize_window()
这块内容就是去访问该网址,并且最大化浏览器页面。方便后续操作。
# TODO 该函数是用来返回每次网页中的链接最后数字,如https://www.xiaohongshu.com/explore/65f23536000000000d00f0cd的65f23536000000000d00f0cd,方便后续构造函数
def get_url_code(content):
url_pattern = re.compile(r'href="/explore/(.*?)"')
matches = url_pattern.findall(content)
return matches
这块内容,就是使用正则表达式,对网页中的每个图文或者视频链接的提取,当然我这里提取的是网页链接的最后片段的数字,后续可以进行拼接,产生可以访问的链接。
temp_height = 0
url_code_list = []
while True:
content = driver.page_source
new_url_list = get_url_code(content)
# print(new_url_list)
url_code_list += new_url_list
# 循环将滚动条下拉
driver.execute_script("window.scrollBy(0,600)")
# sleep一下让滚动条反应一下
time.sleep(1)
# 获取当前滚动条距离顶部的距离
check_height = driver.execute_script(
"return document.documentElement.scrollTop || window.pageYOffset || document.body.scrollTop;")
# 如果两者相等说明到底了
if check_height == temp_height:
print("到底了")
break
temp_height = check_height
print(check_height)
我这段代码的功能就是用来实现滚轮往下滚,直到最底部。
由于xhs等平台,使用的是异步请求,你滚动过后,浏览器中的源代码啥的也会相应产生变化。因此我需要每滚动一次或者几次,就得调用一下content = driver.page_source重新获取一下网页的源代码,然后对其进行获取链接的最后一段字符(后续拼接成网址)。
也就是new_url_list = get_url_code(content)获得了每次的链接最后一段字符。每次返回的都是一个列表。
然后我使用列表相加,将每次获得的最后一段字符,整合到一个大的列表中。后续对其进行去重(按顺序排序)。
这里需要注意的是,window.scrollBy(0,600)的600表示每次滚动的多少,不能太大,否则就会导致一部分数据跳过去了,也不能太小,不然时间耗不起。
然后我需要计算一下是否到底部,没到就继续滚动。
unique_url_code_list = list(Counter(url_code_list))
print(unique_url_code_list)
print(len(unique_url_code_list))
这段代码就是用来对一个列表去重的,COunter可以保证顺序,乱序的后果就是图片乱了,影响较大。我在其他文章中也介绍过两个列表,甚至多个列表按顺序去重的代码,可以学习一下。
# 要添加的字符串
added_string = 'https://www.xiaohongshu.com/explore/'
# 创建一个空列表来存放结果
new_url_list = []
# 循环遍历原始列表,将每个元素加上相同的字符串并存放到新的列表中
for x in unique_url_code_list:
new_url_list.append(added_string+x)
print(new_url_list) # 输出加上相同字符串后的新列表
new_url_list = new_url_list[::-1] # 倒序变成顺序
print(new_url_list)
这段代码就是用来拼接的,将列表中的每个链接最后一段字符拼接上前面的内容,从而变成一个完整的文章网址。
此外,我这里还将链接顺序从现在-过去,转了一下,变成从过去-现在,符合更新文章的逻辑顺序。
当然,也可以将上面的拼接+逆序封装成一个函数。
def get_url_list(unique_url_code_list):
added_string = 'https://www.xiaohongshu.com/explore/'
# 创建一个空列表来存放结果
new_url_list = []
# 循环遍历原始列表,将每个元素加上相同的字符串并存放到新的列表中
for x in unique_url_code_list:
new_url_list.append(added_string + x)
print(new_url_list) # 输出加上相同字符串后的新列表
new_url_list = new_url_list[::-1] # 倒序变成顺序
return new_url_list
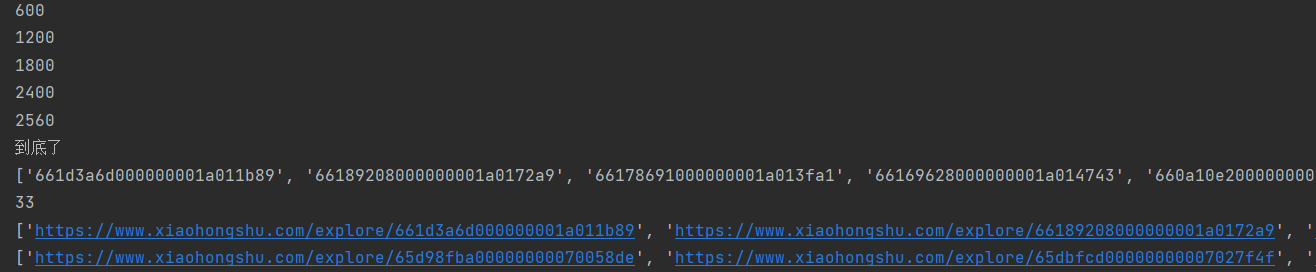
最后的运行结果如下:
















 666
666











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











