







- ID3、C4.5算法都是基于信息论的熵模型,CART分类树算法使用基尼系数来替代信息增益比,基尼系数代表了模型的不纯度,基尼系数越小,则不纯度越低,体征越好。这和信息增益是相反的。
在分类问题中,假设又K个类别,第K个类别的概率为P,则基尼系数的表达式为:
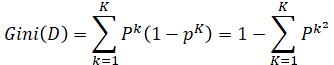
对于二分问题来说
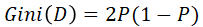

- 对于样本D,如果根据特征A的某个值a,把D分成D1和D2两部分吧,则在特征A的条件下,D的基尼系数表达式为:
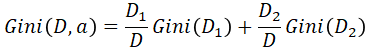
决策树的损失函数

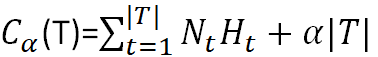
- 节点经验熵
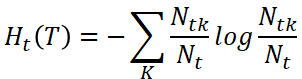
- 原式第一项
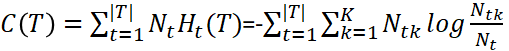
CART树的剪枝(正则化)
- α为正则化参数,这和线性回归的正则化一样,α越大对应着剪枝越厉害
- C(T)为训练数据的预测误差,分类树的用基尼系数度量,回归树是均方差
- |Tt| 是子树T的叶节点的数量
from sklearn.tree import export_graphviz #决策树可视化
from sklearn.linear_model import LogisticRegression #逻辑回归
from sklearn.tree import DecisionTreeClassifier #分类决策树
from sklearn.tree import DecisionTreeRegressor #回归决策树
from IPython.display import Image #IPython 显示图像
import pydotplus #将决策树结构化显示
param = {'max_depth':[3,5,6,7,8,9],'min_samples_split':[2,3,4,5,6]} #设定参数
clf = DecisionTreeClassifier() #树模型,学习器
grid = GridSearchCV(clf,param,cv=10,refit=True,verbose=2) #将学习器传入,进行交叉验证找到最秀的参数
#refit :找到最秀参数后refit重新拟合
#verbose : 输出日志
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











