






 本文介绍了CoquiTTS,一个开源的语音合成工具,包括其基本参数和常用命令,如切换conda环境、列出模型、指定模型名称进行语音合成。还提供了模型下载链接和处理pipinstall错误的提示。文章还包含了CoquiTTS的安装与测试过程。
本文介绍了CoquiTTS,一个开源的语音合成工具,包括其基本参数和常用命令,如切换conda环境、列出模型、指定模型名称进行语音合成。还提供了模型下载链接和处理pipinstall错误的提示。文章还包含了CoquiTTS的安装与测试过程。
官网文档:
Synthesizing Speech - TTS 0.12.0 documentation 基本参数解释
coquiTTS,github地址
https://github.com/coqui-ai 里面有http服务配置,待测试
本 wen 连 接 :
https://blog.csdn.net/konnysnow/article/details/129850145
常用命令
1,切换conda环境
conda activate xxx
2,列出可用的模型,如果本机器已经下载,会显示【already downloaded】
tts --list_models
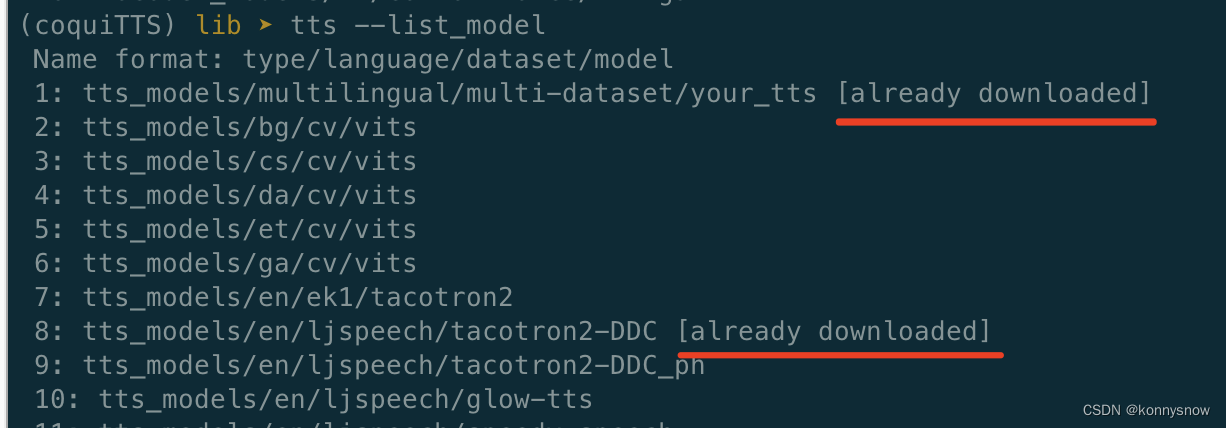
3,通过:--model_name指定模型名称,就是上面list列出的模型名
tts --text "Text for TTS" \
--model_name "<type>/<language>/<dataset>/<model_name>" \
--out_path folder/to/save/output.wav
4,手动下载模型,指定模型路径、config文件,config文件里需要修改stats_path位置。
tts --model_path "/Users/xxx/tts/model/cn/model_file.pth.tar" --config_path "/Users/xxx/tts/model/cn/config.json" --out_path "/Users/xxx/tts/output/sound8.wav" --text "感觉之前电影演的那种智能陪伴型机器人快出来了。嗯嗯,gpt在进化一下应该能满足了。把人本身当成训练的模型,这样下去 什么大数据推荐算法都是垃圾。有点可怕,精准拿捏[旺柴]。"
5,常用模型的下载链接
v0.6.1_models/tts_models--en--ljspeech--tacotron2-DDC.zip
v0.6.1_models/tts_models--zh-CN--baker--tacotron2-DDC-GST.zip

















 4342
4342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









