







Patch-GAN (Discriminative Network)
Patch-GAN可以在对抗学习中被用作discriminator,参考Markovian Generative Adversarial Networks结构中的Discriminative network部分(图1)进行Pytorch代码实现。网络结构的具体细节可参考下述文献:
[1] Li, C. , and M. Wand . “Precomputed Real-Time Texture Synthesis with Markovian Generative Adversarial Networks.” European Conference on Computer Vision Springer, Cham, 2016.
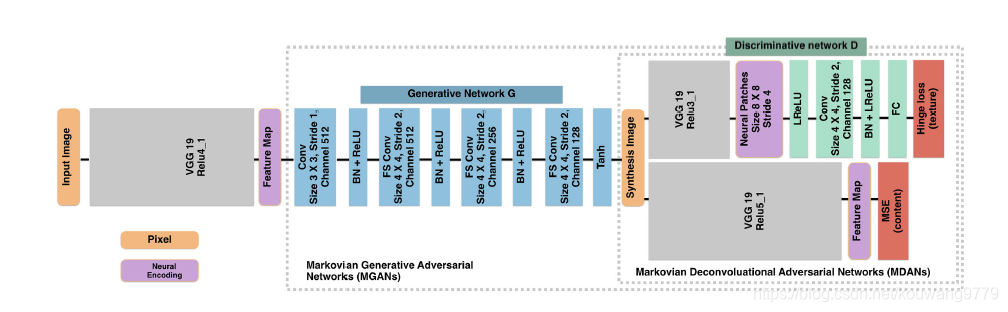
图1 Markovian GAN
Pytorch代码实现
Discriminative Network
class Discriminative_Net(nn.Module):
def __init__(self, in_channel, out_channel, kernel_size=4, padding=1, bias=True, stride=2, in_features=128*4*4, out_features=1):
super().__init__()
self.in_channel = in_channel
self.out_channel = out_channel
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
self.bias = bias
self.in_features = in_features
self.out_features = out_features
self.Discriminator = Discriminator(in_channel=in_channel, out_channel=out_channel, stride=stride,
in_features=in_features, out_features=out_features, kernel_size=kernel_size, padding=padding)
def forward(self, input): # input: 2*1*512*512
vgg19_relu3_1_net = vgg19_bn(layer_name='Relu3_1')
vgg19_relu3_1_net = vgg19_relu3_1_net.cuda()
vgg19_relu3_1 = vgg19_relu3_1_net(input, layer_name='Relu3_1') # 2*256*128*128
patches = Neural_Patches(vgg19_relu3_1, patches_size=8, stride=4) # list [2*256*8*8,...,2*256*8*8] list中有31*31=961个元素
patches = torch.cat(patches,0) # 所有8*8的patches在batchsize维度上进行合并 961*256*8*8
# Sobel
patches_sobel = sobel_conv2d(patches, patches.shape[0], patches.shape[1]) # 961*256*8*8
patches = torch.cat((patches,patches_sobel), 1) # 961*512*8*8
classification_score_texture = self.Discriminator(patches) # 961*1
return classification_score_texture
Sobel卷积
def sobel_conv2d(im, batchSize, channelNum):
sobel_kernel_h = np.array([[1,2,1], [0,0,0], [-1,-2,-1]], dtype='float32') # emphasize horizontal edges
sobel_kernel_h = torch.from_numpy(sobel_kernel_h).type(torch.FloatTensor)
sobel_kernel_h = sobel_kernel_h.repeat(channelNum,channelNum,1,1)
weight = Variable(sobel_kernel_h).cuda()
edge_detect_h = F.conv2d(Variable(im), weight, padding=1) # weight的size相当于kernel的size为3
sobel_kernel_v = np.array([[1,0,-1], [2,0,-2], [1,0,-1]], dtype='float32') # emphasize vertical edges
sobel_kernel_v = torch.from_numpy(sobel_kernel_v).type(torch.FloatTensor)
sobel_kernel_v = sobel_kernel_v.repeat(channelNum,channelNum,1,1)
weight = Variable(sobel_kernel_v).cuda()
edge_detect_v = F.conv2d(Variable(im), weight, padding=1)
edge_detect = edge_detect_h + edge_detect_v
return edge_detect
Neural Patches函数
def Neural_Patches(img, patches_size=8, stride=4):
patches = []
times = (img.shape[-1]-(patches_size-stride))/stride
for row in range(int(times)):
for col in range(int(times)):
patches.append(img[:, :, row*(patches_size-stride):patches_size+row*(patches_size-stride), col*(patches_size-stride):patches_size+col*(patches_size-stride)])
return patches
Discriminator
class Discriminator(nn.Module):
def __init__(self, in_channel, out_channel, stride, in_features, out_features, kernel_size, padding, bias=True):
super().__init__()
self.in_channel = in_channel
self.out_channel = out_channel
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
self.bias = bias
self.in_features = in_features
self.out_features = out_features
self.add_module('bn',nn.BatchNorm2d(self.out_channel))
self.add_module('relu',nn.ReLU(inplace=True))
self.add_module('LeakyRelu',nn.LeakyReLU(inplace=True))
self.add_module('conv',nn.Conv2d(self.in_channel,self.out_channel,kernel_size=self.kernel_size,
stride=self.stride,padding=self.padding,bias=self.bias))
self.add_module('FC',nn.Linear(self.in_features, self.out_features))
self.add_module('sigmoid',nn.Sigmoid()) # 将discriminator的输出控制在[0,1]
def forward(self, input_patches):
# input_patches = torch.cat(input_patches,0) # 所有8*8的patches在batchsize维度上进行合并
out = self.LeakyRelu(input_patches) # 961*512*8*8
out = self.conv(out) # 961*128*4*4
out = self.bn(out) # 961*128*4*4
out = self.relu(out) # 961*128*4*4
out = self.FC(out.reshape((out.shape[0],out.shape[1]*out.shape[2]*out.shape[3]))) # 961*1
out = self.sigmoid(out) # 961*1
return out
vgg19_bn函数的实现见博文:
https://blog.csdn.net/kouwang9779/article/details/118801860















 1678
1678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









