







 RLlib是一个基于Ray的开源项目,提供了一种分层并行任务模型来实现高性能、可扩展的强化学习算法。它通过策略计算图、策略评估器和策略优化器抽象,支持分布式策略评估和训练。RLlib在各种强化学习算法中表现出优秀的性能,且具有模块化和普适性。
RLlib是一个基于Ray的开源项目,提供了一种分层并行任务模型来实现高性能、可扩展的强化学习算法。它通过策略计算图、策略评估器和策略优化器抽象,支持分布式策略评估和训练。RLlib在各种强化学习算法中表现出优秀的性能,且具有模块化和普适性。
abstract
RLlib是开源项目Ray的一部分,RLlib官方文档,实现了自顶向下分层控制的强化学习算法,并达到了高性能、可扩展、大量代码重用的特性。
introduction
本文的主要工作如下:
- 为强化学习训练提出了一个通用且模块化的分层编程模型;
- 描述了RLlib这一高度可扩展化的强化学习算法库,以及如何在代码库中快速构建一系列强化学习算法;
- 讨论了这一框架的性能,验证了RLlib在各种强化学习算法中和其他众多框架相比,达到或超过了最优性能;
1.分层并行任务模型
在基于任务的灵活编程模型基础上,通过分层控制和逻辑中控来构建强化学习算法库,基于任务的系统允许在细粒度的基础上,在子程序上异步调度和执行子例程,并在进程间检索和传递结果。
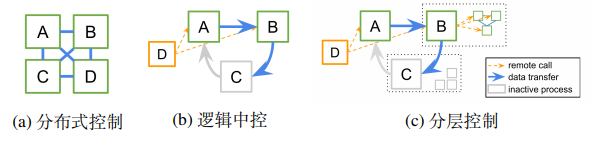
1.1 和已有的分布式ML抽象之间的关系
尽管参数服务器和集体通信操作等抽象模式通常是为分布式控制而制定的,但是也可以在逻辑中控模型中使用。
1.2 通过Ray实现分层控制
在单个机器内,使用线程池和共享内存即可实现此编程模型,当有需要的时候,基础框架也可以扩展到更大的集群。我们在Ray框架上构建RLlib,它允许Python任务跨大型集群分布,Ray的任务调度器非常适合分层控制模型。
- Ray用Ray actor实现了启动新进程并在其上调度任务,Ray actor是可以在集群中创建并接受远程方法调用的Python类,Ray允许这些actor反过来启动更多actor并在这些actor上调度任务,满足了对分层委托的需求;
- 为了性能,Ray提供了聚合和广播等标准通信原语;
- 通过共享内存对象存储实现了大型数据对象的零复制共享。
2. 强化学习的抽象
为了利用RLlib进行分布式执行,算法必须声明策略 π \pi π, 经验后处理器 ρ \rho ρ, 和损失 L L L,RLlib中提供了策略评估器和策略优化器,用于实现分布式策略评估和训练。
2.1 策略计算图定义
RLlib抽象模式:
策略模型 π \pi π, 将当前观测值 o t o_t ot和RNN的隐藏状态 h t h_t ht映射到一个动作 a t a_t at和下一个RNN状态 h t + 1 h_{t+1} ht+1,用户定义的 y t i y^i_t yti也可以被返回:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 879
879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









