






在使用mmcv框架(mmdetection或者是mmsegmentation)进行分布式训练的时候,存在一个隐藏bug。正常来说,分布式训练的示意图如下,代表了不同的GPU卡,
代表了不同卡的输出,分布式训练时会有一步汇总操作(代码里是dist.all_reduce),将不同卡的
进行平均。
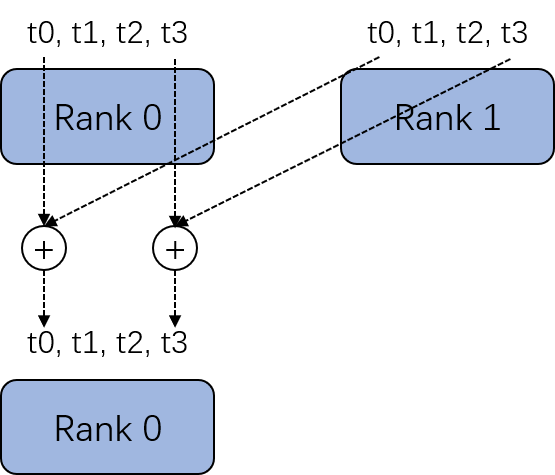
但是,dist.all_reduce操作的前提是在每个GPU卡的产生顺序一定要是固定的,比如有
四个分类任务,代码里指定GPU0卡依次产生
,GPU1卡依次产生
,如果只有GPU0与GPU1两个卡做分布式训练,那么实际在做dist.all_reduce操作时,是GPU0卡的
与GPU1卡的
做平均,而不是与GPU1卡的
做平均。因此在用mmcv框架做分布式训练时,一定要保证不同head产生的loss顺序一致,不然会产生不同任务loss做平均的问题。














 4796
4796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









