







 Neural Baby Talk是一种减少语言模型依赖、强化图像内容的图像描述技术。通过物体检测器生成带有槽位的句子模板,再用目标检测结果填充,实现了视觉与文本的融合。文章详细介绍了模型结构、目标函数、训练细节,以及在标准和新颖对象caption任务上的表现。
Neural Baby Talk是一种减少语言模型依赖、强化图像内容的图像描述技术。通过物体检测器生成带有槽位的句子模板,再用目标检测结果填充,实现了视觉与文本的融合。文章详细介绍了模型结构、目标函数、训练细节,以及在标准和新颖对象caption任务上的表现。
Neural Baby Talk学习笔记
1、介绍
-
深度学习时代
采用LSTM模型,过分依赖language model,导致caption经常与图像内容关联不够。
-
深度学习之前
更依赖图像内容,而对language model关注不多,例如采用一系列视觉检测器检测图像内容,然后基于模板或者其他方式生成caption
-
作者观点
减少对语言模型的依赖,更多地结合图像内容。
采用物体检测器检测图像中的物体(visual words),然后在每个word的生成时刻,自主决定选取text word(数据集中的词汇) 还是 visual word(检测到的词汇)。
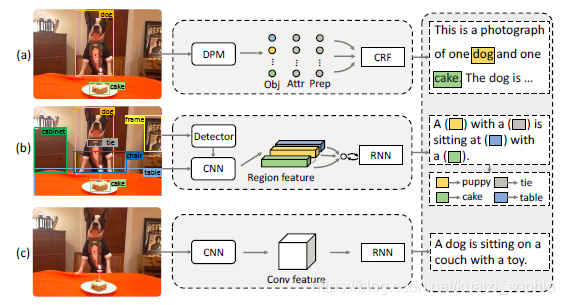
如图1所示,(a)为Baby Talk模型示意图,(b)为Neural Baby Talk模型示意图,©为neural image captioning模型示意图。Neural Baby Talk方法先生成一个句子模板,其中关键单词空缺,如图中的有色方块所示,接着,目标检测器对图片中目标进行检测,并将检测得到的物体名称填入句子模板中。

如上图,展示了使用4个不同目标检测器的效果,(1)未使用目标检测器;(2)使用弱目标检测器,只检测出来“person”和"sandwich";(3)使用在COCO数据集上训练出来的目标检测器,结果较为准确;(4)使用具有新奇概念novel concepts的目标检测器,图片captions训练集中并没有“Mr. Ted”和"pie"词汇。
本文提出的神经方法会生成一个句子模板,模板中的空槽和图片区域捆绑在一起。在每个time step,模型决定选择从textual词汇表生成词语还是使用视觉词汇。
visual word:
每个visual word对应一个区域 r I r_I rI,如图1所示,“puppy”和"cake"分别属于“dog”和"cake"的bounding box类别,是visual words。
textual word:
来自Caption的剩余部分,图1中,“with” 和 “sitting”与图片中的区域没有关系,因此是textual words。
2、方法
目标:
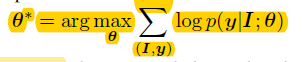
其中, I I I为输入图片, y y y为图片描述语句。
公式可以分成两个级联的目标:
-
最大化生成句子“模板”的概率;
如图3所示,“A <region-2>is laying on the <region-4> near a <region-7>"即为“模板”。
-
最大化依据grounding区域和目标识别信息得到的visual words的概率;
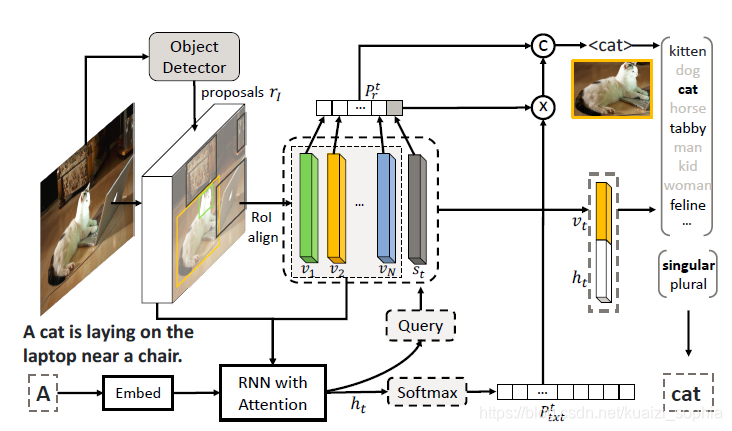
“Slotted” Caption模板生成
本文使用recurrent neural network(RNN)生成Caption的模板。此RNN由LSTM层组成,CNN输出的feature maps作为其输入。
使用pointer network,通过调制一个在grounding区域上基于内容的注意力机制来生成visual words的槽“slot”。
Caption改良:槽填充
使用目标检测框架在grounding区域上,可以识别区域内的物体类别,例如,“狗”。
还需要对词语进行变换使其适合当前文本上下文,比如单复数、形态等。
而Captions指的是比较时尚的词“puppy”,或复数形式“dogs”。因此,为了适应语言的变化,我们模型生成的visual words是经过细致改良过的,变换的主要措施为:1、单复数,确定此类别物体是否有多个(如dog跟dogs);2、确定细粒度的类别名称(如dog可以细分为puppy等);
两种变换分别学习两个分类器实现,单复数用二分类器,fine-grained用多分类做。
整体实现
目标函数:
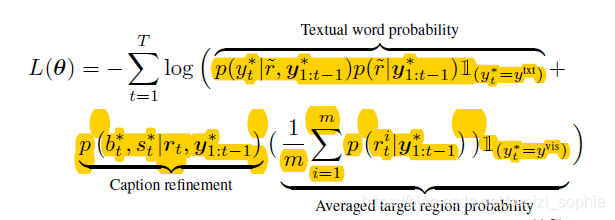
第一部分为Textual word 概率,第二部分为Caption细微改良(针对词形态),第三部分为目标区域平均概率。
其中, y t ∗ y_t^*
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1739
1739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









