






上午学习记录
- 了解周二周三周四三天内需要完成的项目
手机流量统计项目
需求:通过提供的access.log日志数据文件,
统计每个手机号上行流量和、下行流量和、总流量和(上
行流量和+下行流量和),并且:将统计结果按照手机号的前缀
进行区分,并输出到不同的输出文件中去。
开发步骤包括(1)自定义Access类、(2)自定义Map任务类、(3) 编写Reduce任务类、(4) 编写分区处理类
- 在虚拟机中安装集成开发环境IntelliJ IDEA
使用Xshell以及Xftp传安装包ideaIC-2021.1.3.tar.gz到虚拟机中
使用tar命令解压
解压完后在熟悉的文件夹里发现了以前下载过的idea
- 在idea中配置maven,引入hadoop依赖
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop
<artifactId>hadoop-client
<version>3.2.0
</dependency>
</dependencies>
引入后需要刷新一下
下午学习记录
- Hadoop序列化与反序列化
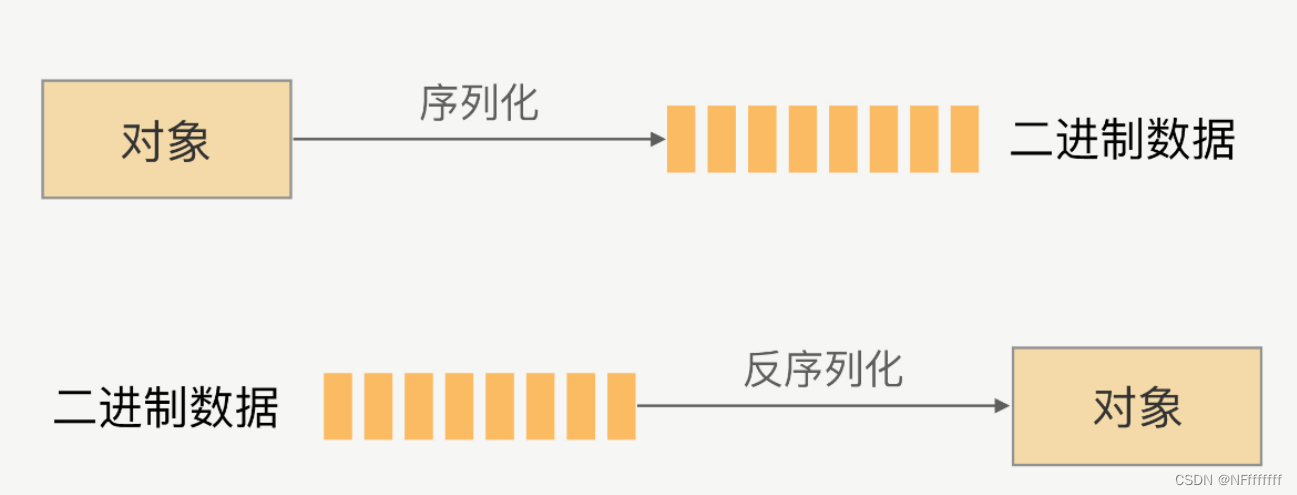
序列化
序列化是将对象的状态信息转化为可以存储或传输的形式
的过程,通常指将对象在内存中的状态信息转换为可以被存储
在外部介质上的二进制流或其他格式的数据,以便在需要时可
以重新读取和还原对象的状态信息。
反序列化
反序列化则是将已经序列化的对象(二进制数据)重新装配
成对象的过程。
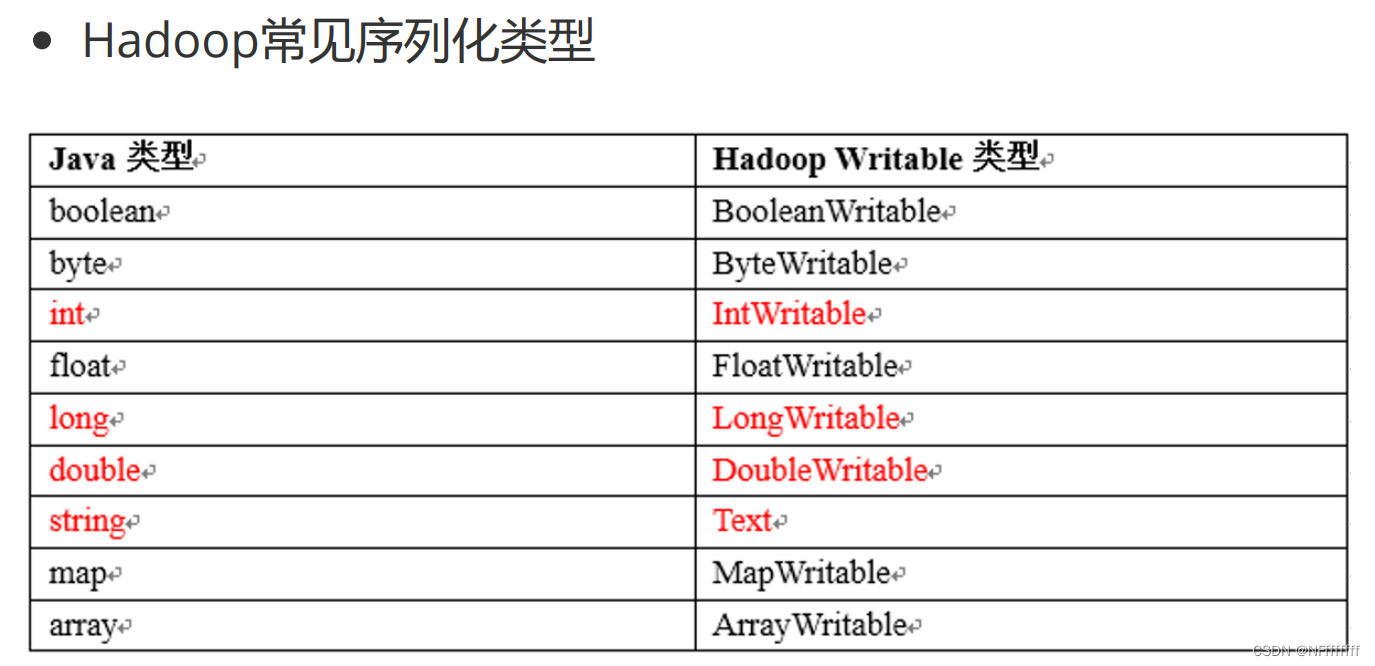
自定义对象实现Hadoop序列化接口
(1) 必须实现Writable接口
(2) 反序列化时,需要反射调用空参构造函数,所以必须有
空参构造
(3) 重写序列化方法和反序列化方法
(4) 反序列化的顺序和序列化的顺序完全一致
(5) 如果需要将自定义的bean放在key中传输,则还需要实现
Comparable接口,因为MapReduce框架中的shuffle过程一定
会对key进行排序。
-
项目进度
-
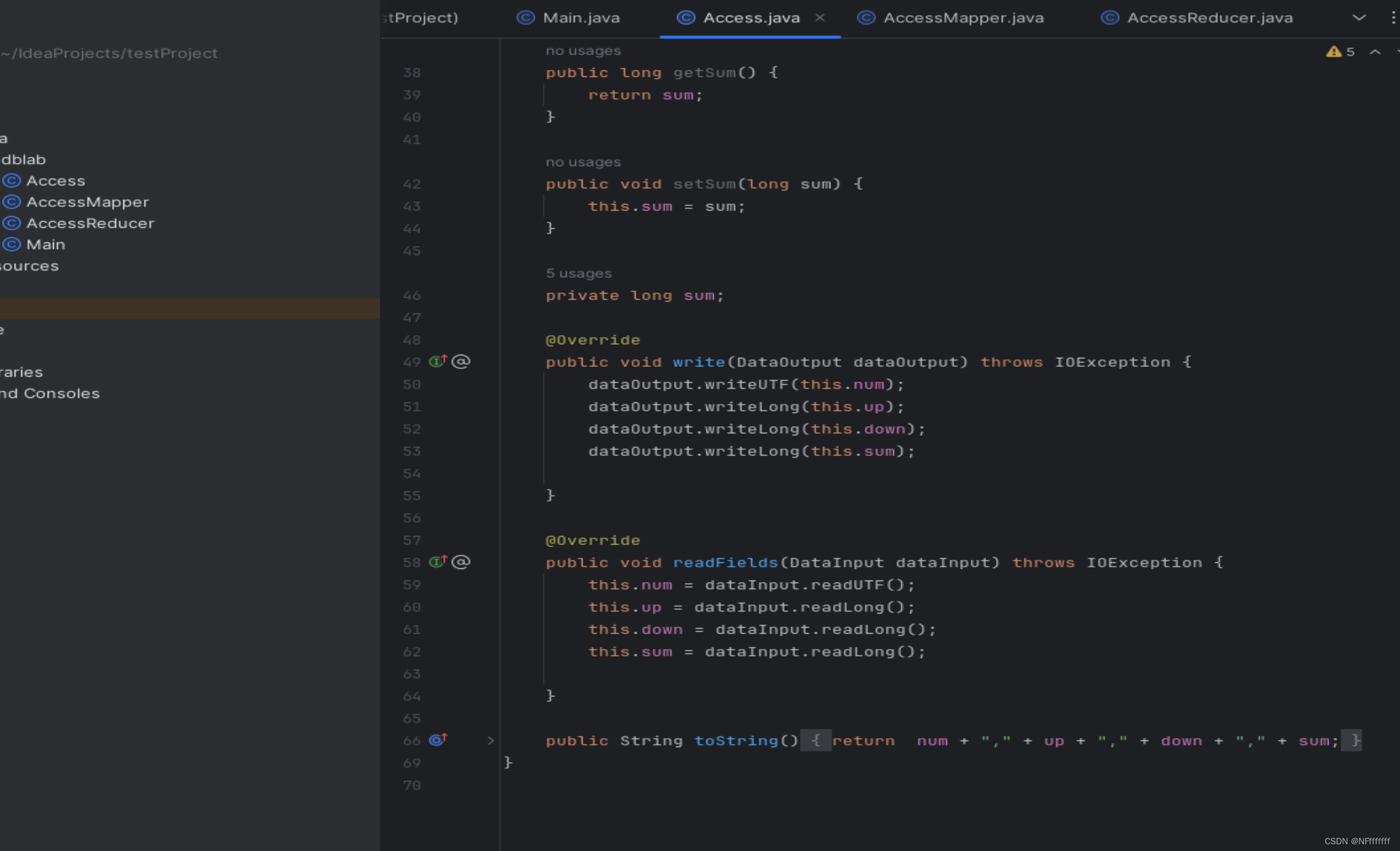
(1)自定义Access类
-
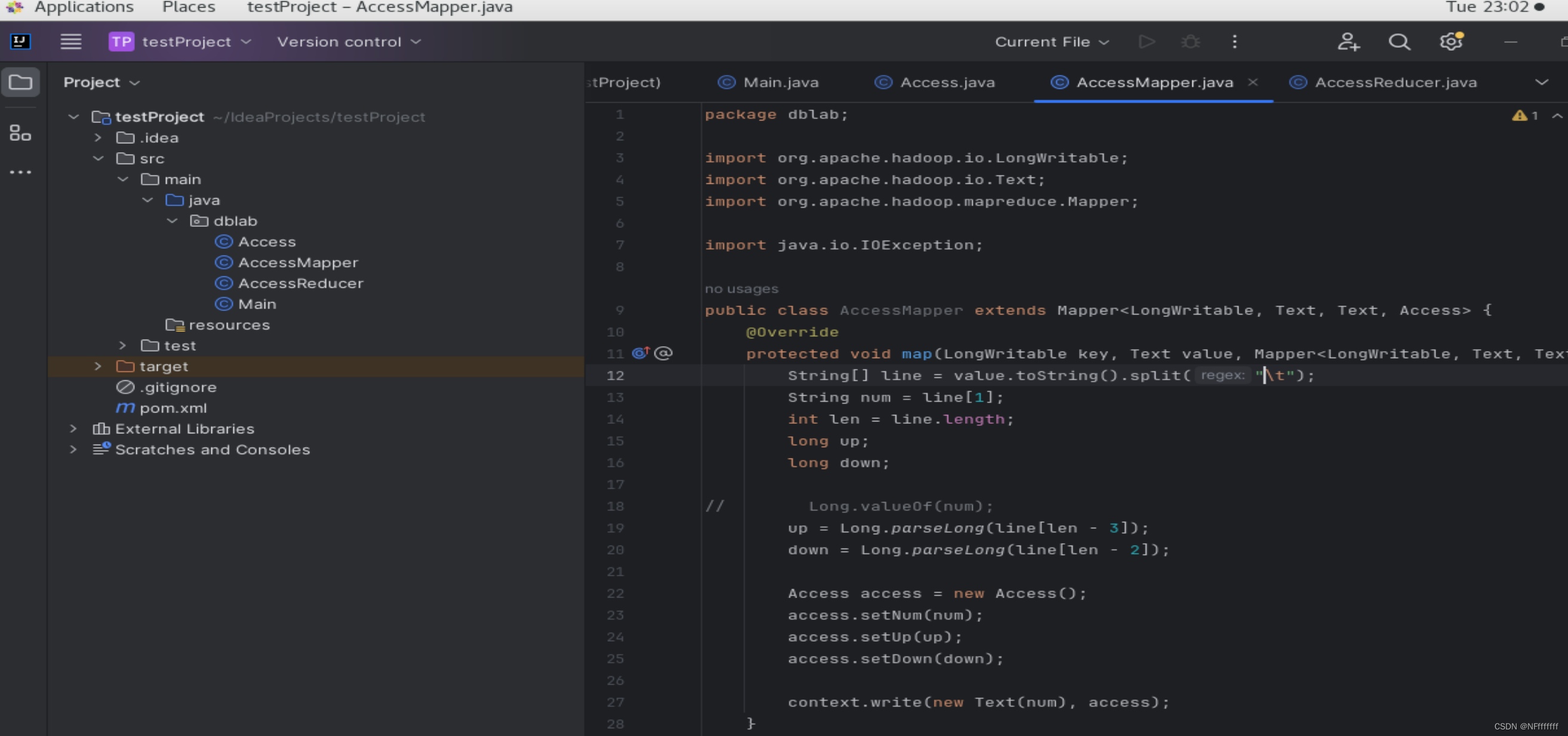
(2)自定义Map任务类
-
(3) 编写Reduce任务类
还没写完
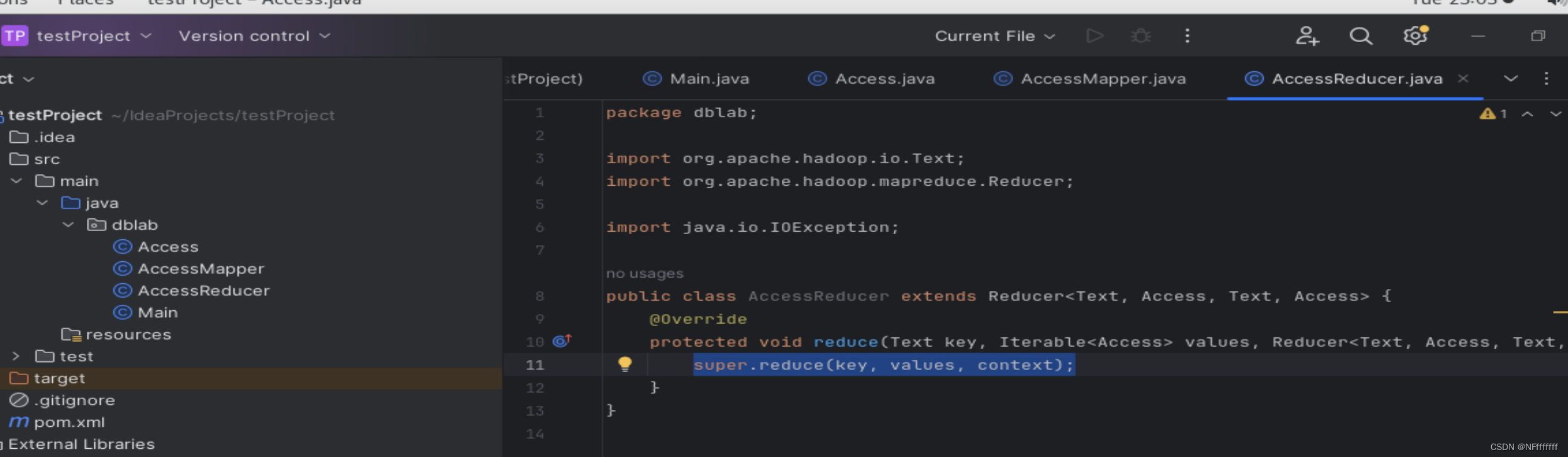
-
(4) 编写分区处理类
- 注册码云、新建仓库
-下载git以及TortoiseGit















 254
254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









