






Day3实习记录
今天主要是在写项目,老师讲解了一下第二个项目和其中遇到过的某些问题。
- 电商日志数据分析项目
统计页面浏览量(每行记录就是一次浏览)
统计各个省份的浏览量 (需要解析IP)
日志的ETL操作(ETL:数据从来源端经过抽取(Extract)、转换(Transform)、加载(Load)至目的端的过程)
为什么要ETL:没有必要解析出所有数据,只需要解析出有价值的字段即可。本项目中需要解析出:ip、url、pageId(topicId对应的页面Id)、country、province、city
*|-` )这个项目都没怎么听,现在不知道咋做了 *
但是把手机流量统计项目做完了
- Access类
package dblab;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class Access implements Writable {
private String num;
private long up;
private long down;
private long sum;
public String getNum() {
return num;
}
public Access() {
super();
}
public void setNum(String num) {
this.num = num;
}
public long getUp() {
return up;
}
public void setUp(long up) {
this.up = up;
}
public long getDown() {
return down;
}
public void setDown(long down) {
this.down = down;
}
public long getSum() {
return sum;
}
public void setSum(long sum) {
this.sum = sum;
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.num = dataInput.readUTF();
this.up = dataInput.readLong();
this.down = dataInput.readLong();
this.sum = dataInput.readLong();
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(this.num);
dataOutput.writeLong(this.up);
dataOutput.writeLong(this.down);
dataOutput.writeLong(this.sum);
}
public String toString(){
return num + "," + up + "," + down + "," + sum;
}
}
- Mapper类
package dblab;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class AccessMapper extends Mapper<LongWritable, Text, Text, Access> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Access>.Context context) throws IOException, InterruptedException {
String[] line = value.toString().split("\t");
String num = line[1];
int len = line.length;
long up;
long down;
// Long.valueOf(num);
up = Long.parseLong(line[len - 3]);
down = Long.parseLong(line[len - 2]);
Access access = new Access();
access.setNum(num);
access.setUp(up);
access.setDown(down);
context.write(new Text(num), access);
}
}
- Reducer类
package dblab;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class AccessReducer extends Reducer<Text, Access, Text, Access> {
@Override
protected void reduce(Text key, Iterable<Access> values, Reducer<Text, Access, Text, Access>.Context context) throws IOException, InterruptedException {
long sumUp = 0;
long sumDown = 0;
for(Access access:values){
sumUp += access.getUp();
sumDown += access.getDown();
}
Access a = new Access();
a.setNum(key.toString());
a.setUp(sumUp);
a.setDown(sumDown);
a.setSum(sumUp+sumDown);
context.write(key,a);
}
}
- Partitioner类
package dblab;
import org.apache.hadoop.mapreduce.Partitioner;
public class AccessPartitioner extends Partitioner {
@Override
public int getPartition(Object o, Object o2, int i) {
String key = o.toString();
if (key.startsWith("13")) {
return 0;
} else if (key.startsWith("15")) {
return 1;
} else {
return 2;
}
}
}
- 主类
package dblab;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Job;
import java.io.IOException;
// Press Shift twice to open the Search Everywhere dialog and type `show whitespaces`,
// then press Enter. You can now see whitespace characters in your code.
public class Main {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//配置类
Configuration conf = new Configuration();
//工作类
Job job = Job.getInstance(conf);
//运行类
job.setJarByClass(Main.class);
//Reduce任务个数
job.setNumReduceTasks(3);
//配置自定义Partitioner
job.setPartitionerClass(AccessPartitioner.class);
// 配置Mapper与Reducer
job.setMapperClass(AccessMapper.class);
job.setReducerClass(AccessReducer.class);
//设置Mapper输出的key、value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Access.class);
//设置Reduce输出的key、value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Access.class);
FileInputFormat.setInputPaths(job, new Path("file:/home//avior//access.txt"));
FileOutputFormat.setOutputPath(job, new Path("file:/home//avior//output"));
boolean result=job.waitForCompletion(true);
System.out.println(result?"ok":"0");
}
}
反思:下次一定要及时写注释
运行结果:
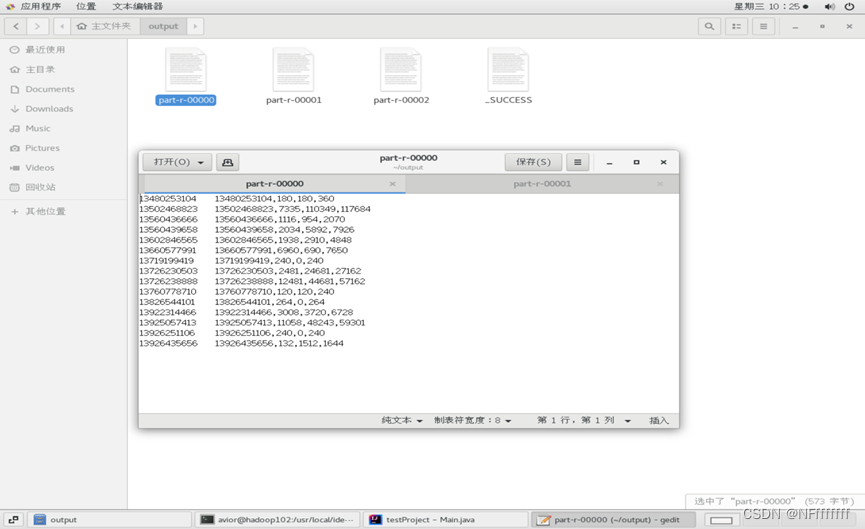
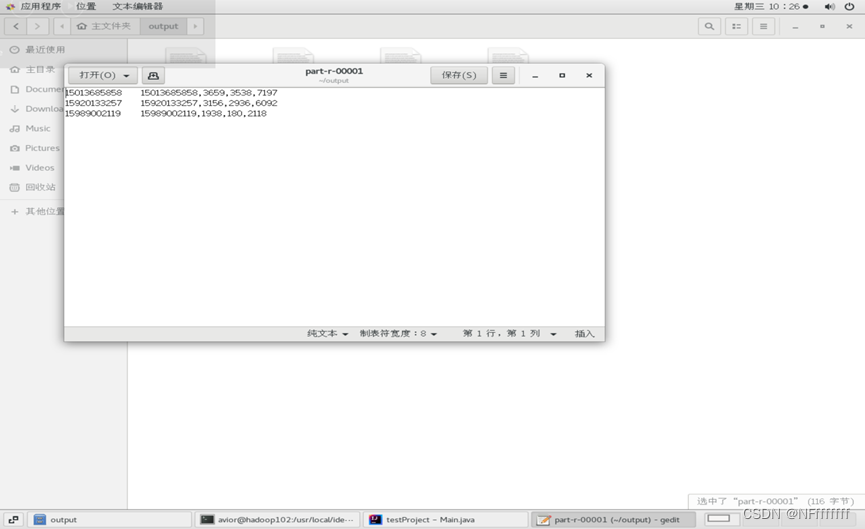
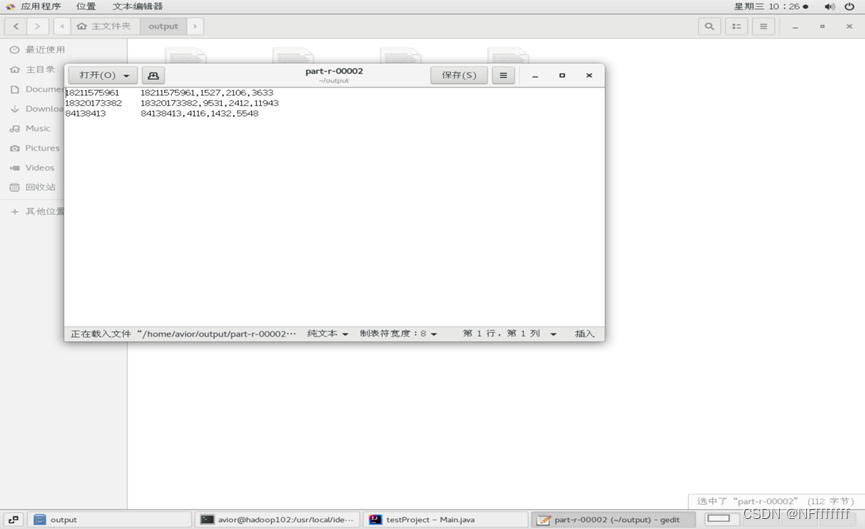















 229
229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









