






原文:2024 年十大机器学习算法 | 爱搜AI工具资源导航站
机器学习算法是指一类让计算机能够从数据中学习和预测的方法和技术。它们可以帮助我们发现数据中的模式、关系和见解,从而为我们提供更好的决策和预测能力。在实际应用中,有许多种不同的机器学习算法,每种都有其特定的优势和适用场景。下面将介绍十大常见的机器学习算法:
十大常见机器学习算法列表
以下是常用机器学习算法的列表。这些算法可用于解决几乎任何数据问题。
- Linear Regression 线性回归
- Logistic Regression 逻辑回归
- Decision Tree 决策树
- SVM 支持向量机
- Naive Bayes 朴素贝叶斯
- kNN kNN
- K-Means K-均值
- Random Forest 随机森林
- Dimensionality Reduction Algorithms降维算法
- Gradient Boosting algorithms 梯度提升算法
1. Linear Regression
概念:用于预测连续型变量的数值,通过拟合数据点与一个或多个自变量之间的线性关系来进行预测。线性回归用于预测连续结果(例如根据身高预测一个人的体重)。它假设输入特征(自变量)和目标变量(因变量)之间存在线性关系。

有几种方法可以确定线性回归模型的拟合优度:

目标是找到系数(β 值),使平方误差之和(实际值与预测值之间的差异)最小。
R 平方:R 平方是一种统计度量,表示因变量中的方差由模型中的自变量解释的比例。 R 平方值为 1 表示模型解释了因变量中的所有方差,值为 0 表示模型没有解释任何方差。
调整 R 平方:调整 R 平方是 R 平方的修改版本,它考虑了模型中自变量的数量。当比较具有不同数量自变量的模型时,它可以更好地指示模型的拟合优度。
均方根误差 (RMSE):RMSE 衡量预测值与实际值之间的差异。 RMSE 较低表明模型与数据的拟合效果更好。
平均绝对误差 (MAE):MAE 测量预测值与实际值之间的平均差异。 MAE 越低表明模型与数据的拟合效果越好。
from sklearn.datasets import make_regression
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split# Create a synthetic dataset
X, y = make_regression(n_samples=100, n_features=1, noise=0.1, random_state=42)# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Create and train the model
model = LinearRegression()
model.fit(X_train, y_train)# Make predictions
y_pred = model.predict(X_test)print(“Predictions:”, y_pred)
2. Logistic Regression
概念:主要用于处理分类问题,将输入数据映射到一个0-1之间的概率值,用于预测属于某个类别的概率。逻辑回归用于二元分类问题,其结果是分类的(例如预测电子邮件是否是垃圾邮件)。它不是预测连续值,而是预测给定输入属于某个类别的概率。


P(y=1∣x) 是结果 y 为 1(例如垃圾邮件)的概率。e 是自然对数的底。
其余术语与线性回归类似,但它们使用逻辑函数进行转换以将输出保持在 0 和 1 之间。
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split# Load the breast cancer dataset
X, y = load_breast_cancer(return_X_y=True)# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Create and train the model
model = LogisticRegression(max_iter=10000)
model.fit(X_train, y_train)# Make predictions
y_pred = model.predict(X_test)print(“Predictions:”, y_pred)
3. Decision Tree
概念:决策树是一种用于分类和回归任务的机器学习算法。通过对数据集进行划分,构建一棵树形结构来进行分类或回归预测。它们是决策的强大工具,可用于对变量之间的复杂关系进行建模。

决策树是一种树状结构,每个内部节点代表一个决策点,每个叶节点代表最终结果或预测。该树是通过根据输入特征的值递归地将数据分割成子集来构建的。目标是找到最大化不同类别或目标值之间分离的分割。
构建决策树的过程从选择根节点开始,根节点是最好地将数据分为不同类别或目标值的特征。然后根据该特征的值将数据分成子集,并对每个子集重复该过程,直到满足停止标准。停止标准可以基于子集中的样本数量、子集的纯度或树的深度。
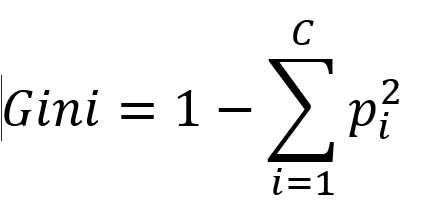
基尼杂质:测量从集合中随机选择的元素被错误分类的频率。 pi 是从 C 类中选择 iii 类元素的概率。
信息增益:测量数据集在特征上分割后熵的减少。这是分裂之前和之后的熵之差。
决策树存在一些常见的挑战。一个关键问题是它们倾向于过度拟合数据,尤其是当树变得很深并且分支广泛时。当树变得过于复杂时,就会发生过度拟合,捕获噪声而不是实际模式。这可能会损害其在新的、未见过的数据上的性能。但不用担心!我们有修剪、正则化和交叉验证等技巧来控制过度拟合。
另一个挑战是它们对输入特征顺序的敏感性。对功能进行混洗,最终可能会得到一种完全不同的树结构,但并不总是最好的。但不要害怕!随机森林和梯度提升等技术可以解决这一问题,确保做出更稳健的决策。
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split# Load the iris dataset
X, y = load_iris(return_X_y=True)# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Create and train the model
model = DecisionTreeClassifier(random_state=42)
model.fit(X_train, y_train)# Make predictions
y_pred = model.predict(X_test)print(“Predictions:”, y_pred)
4. SVM
概念:支持向量机(SVM)是一种监督学习算法,可用于分类或回归问题。它找到将类分开的最佳边界(超平面),并在类的最近点(支持向量)之间具有最大边距(距离)。这些最接近的数据点称为支持向量。主要用于分类问题,通过找到能够最大化类别间距离的超平面来进行分类。

超平面:可以有多条线/决策边界来分隔n维空间中的类,但我们需要找出有助于对数据点进行分类的最佳决策边界。这个最佳边界称为 SVM 的超平面。
支持向量:最接近超平面并影响超平面位置的数据点或向量称为支持向量。由于这些向量支持超平面,因此称为支持向量。SVM 可以有两种类型:
- 线性SVM:线性SVM用于线性可分离数据,这意味着如果一个数据集可以用一条直线将数据集分为两类,那么这样的数据被称为线性可分离数据,并且使用的分类器被称为线性SVM分类器。
- 非线性SVM:非线性SVM用于非线性分离的数据,这意味着如果一个数据集不能用直线进行分类,那么这样的数据被称为非线性数据,所使用的分类器被称为非线性数据。线性 SVM 分类器。
当数据不可线性分离(这意味着数据不能用直线分离)时,SVM 特别有用。在这些情况下,SVM 可以使用一种称为核技巧的技术将数据转换到更高维的空间,其中可以找到非线性边界。 SVM 中使用的一些常见核函数包括多项式、径向基函数 (RBF) 和 sigmoid。
Mathematical Explanation:
目标是最大化边际,定义为 2 / ∣∣w∣∣,其中 w 是特征系数向量。
决策边界由 w⋅x + b = 0 表示,其中 b 是偏差项。
SVM 试图找到最大化边际的 www 和 bbb,同时确保数据点正确分类。
from sklearn.datasets import load_wine
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split# Load the wine dataset
X, y = load_wine(return_X_y=True)# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Create and train the model
model = SVC(kernel=‘linear’, random_state=42)
model.fit(X_train, y_train)# Make predictions
y_pred = model.predict(X_test)print(“Predictions:”, y_pred)
5. Naive Bayes
概念:朴素贝叶斯是一种简单高效的机器学习算法,基于贝叶斯定理,用于分类任务。它被称为“朴素”,因为它假设数据集中的所有特征都是相互独立的,而现实世界数据中的情况并不总是如此。基于贝叶斯定理和特征条件独立假设,用于处理分类问题。
该算法在给定输入特征值的情况下计算给定类别的概率。贝叶斯定理指出,给定一些证据(在本例中为特征值)的假设(在本例中为类别)的概率与给定假设的证据的概率乘以假设的先验概率成正比。
朴素贝叶斯算法可以使用不同类型的概率分布(例如高斯分布、多项式分布和伯努利分布)来实现。高斯朴素贝叶斯用于连续数据,多项式朴素贝叶斯用于离散数据,伯努利朴素贝叶斯用于二进制数据。
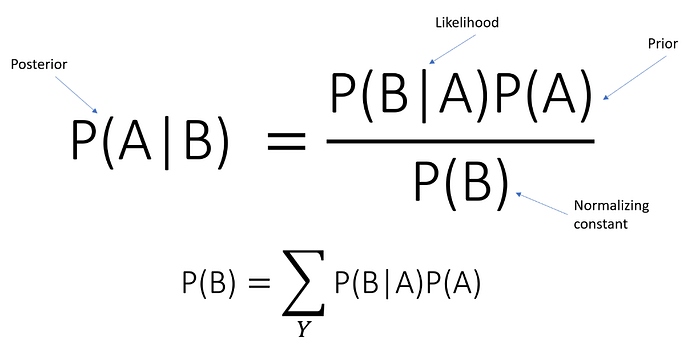
P(A∣B) 是假设 B 为真时事件 A 的概率。
P(B∣A) 是假设 A 为真时事件 B 的概率。
P(A) 和 P(B) 是 A 和 B 独立的概率。
6. k-Nearest Neighbors (kNN)
概念:K 最近邻(KNN)是一种简单而强大的算法,用于机器学习中的分类和回归任务。它基于这样的想法:相似的数据点往往具有相似的目标值。该算法的工作原理是查找给定输入的 k 个最近数据点,并使用最近数据点的多数类或平均值来进行预测。通过计算新样本与训练样本的距离来进行分类或回归预测。

构建 KNN 模型的过程从选择 k 值开始,k 是预测时考虑的最近邻居的数量。然后将数据分为训练集和测试集,训练集用于查找最近的邻居。为了对新输入进行预测,该算法会计算输入与训练集中每个数据点之间的距离(欧几里德),并选择 k 个最近的数据点。然后使用最近数据点的多数类或平均值作为预测。

KNN 的主要优点之一是其简单性和灵活性。它可用于分类和回归任务,并且不对底层数据分布做出任何假设。此外,它可以处理高维数据,并可用于监督和无监督学习。
KNN 的主要缺点是其计算复杂性。随着数据集大小的增加,查找最近邻居所需的时间和内存可能会变得非常大。此外,KNN 对 k 的选择很敏感,并且找到 k 的最佳值可能很困难。
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split# Load the iris dataset
X, y = load_iris(return_X_y=True)# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Create and train the model
model = KNeighborsClassifier(n_neighbors=3)
model.fit(X_train, y_train)# Make predictions
y_pred = model.predict(X_test)print(“Predictions:”, y_pred)
7. K-Means Clustering
概念:K-means 是一种用于聚类的无监督机器学习算法。聚类是将相似的数据点分组在一起的过程。 K-means 是一种基于质心的算法或基于距离的算法,我们计算将点分配给簇的距离。

该算法的工作原理是随机选择 k 个质心,其中 k 是我们想要形成的簇的数量。然后将每个数据点分配给具有最近质心的簇。一旦分配了所有点,质心将被重新计算为簇中所有数据点的平均值。重复此过程,直到质心不再移动或点对簇的分配不再改变。
Mathematical Explanation:

该算法迭代地工作以最小化簇内平方和(惯性):
随机初始化 k 个质心。
将每个数据点分配给最近的质心。
重新计算质心作为簇中所有点的平均值。
重复步骤2和3,直到质心不再改变。其中 μi 是簇 Ci 的质心。
KNN 的主要优点之一是其简单性和灵活性。它可用于分类和回归任务,并且不对底层数据分布做出任何假设。此外,它可以处理高维数据,并可用于监督和无监督学习。
KNN 的主要缺点是其计算复杂性。随着数据集大小的增加,查找最近邻居所需的时间和内存可能会变得非常大。此外,KNN 对 k 的选择很敏感,并且找到 k 的最佳值可能很困难。
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans# Create a synthetic dataset
X, _ = make_blobs(n_samples=100, centers=3, n_features=2, random_state=42)# Create and train the model
model = KMeans(n_clusters=3, random_state=42)
model.fit(X)# Predict the clusters
labels = model.predict(X)print(“Cluster labels:”, labels)
8. Random Forest
概念:使用多个决策树背后的想法是,虽然单个决策树可能容易过度拟合,但决策树的集合或森林可以降低过度拟合的风险并提高模型的整体准确性。
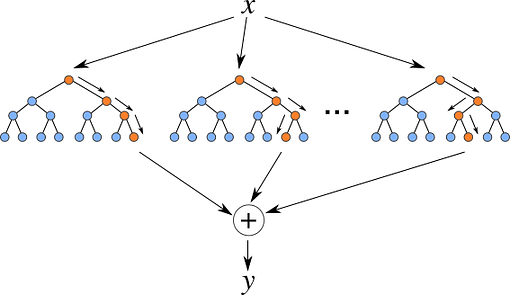
构建随机森林的过程首先使用一种称为引导的技术创建多个决策树。 Bootstrapping 是一种统计方法,涉及从原始数据集中随机选择数据点并进行替换。这会创建多个数据集,每个数据集都有一组不同的数据点,然后用于训练单个决策树。
随机森林的主要优点之一是它比单个决策树更不容易过度拟合。多棵树的平均可以消除误差并减少方差。随机森林在高维数据集和具有大量 calcategories 变量的数据集中也表现良好。
随机森林的缺点是训练和预测的计算成本可能很高。随着森林中树木数量的增加,计算时间也会增加。此外,随机森林比单个决策树的可解释性更差,因为更难理解每个特征对最终预测的贡献。
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split# Load the breast cancer dataset
X, y = load_breast_cancer(return_X_y=True)# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Create and train the model
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)# Make predictions
y_pred = model.predict(X_test)print(“Predictions:”, y_pred)
9. Dimensionality Reduction Algorithms (PCA)
概念:降维用于减少数据集中输入变量的数量,同时保留尽可能多的信息。它用于提高机器学习算法的性能并使数据可视化更容易。有多种降维算法可用,包括主成分分析 (PCA)、线性判别分析 (LDA) 和 t 分布随机邻域嵌入 (t-SNE)。

线性判别分析(LDA)是一种监督降维技术,用于为分类任务找到最具判别性的特征。 LDA 最大化低维空间中类之间的分离。
主成分分析 (PCA) 是一种线性降维技术,它使用正交变换将一组相关变量转换为一组称为主成分的线性不相关变量。 PCA 对于识别数据模式和降低数据维度而不丢失重要信息非常有用。
t 分布随机邻域嵌入 (t-SNE) 是一种非线性降维技术,对于可视化高维数据特别有用。它使用高维数据点对上的概率分布来查找保留数据结构的低维表示。
降维技术的主要优点之一是它们可以通过降低计算成本和降低过度拟合的风险来提高机器学习算法的性能。此外,它们还可以通过将维度数量减少到更易于管理的数量来使数据可视化变得更容易。
降维技术的主要缺点是在降维过程中可能会丢失重要信息。此外,降维技术的选择取决于数据的类型和手头的任务,并且可能很难确定要保留的最佳维数。
10. Gradient Boosting Algorithms
概念:梯度提升是一种按顺序构建模型的集成技术。每个新模型都会纠正以前模型所犯的错误。该方法对于分类和回归任务都非常有效。
Mathematical Explanation:

该模型通过添加预测先前模型的残差(误差)的模型来最小化损失函数:
Fm(x) 是 mmm 迭代后的模型。
hm(x)是修正Fm−1(x)误差的模型。
XGBoost 、 LightGBM 和 CatBoost 是梯度提升的流行实现。
import xgboost as xgb
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split# Load the breast cancer dataset
X, y = load_breast_cancer(return_X_y=True)# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Create and train the model
model = xgb.XGBClassifier(random_state=42)
model.fit(X_train, y_train)# Make predictions
y_pred = model.predict(X_test)print(“Predictions:”, y_pred)
总结一下,机器学习算法是一种让计算机能够从数据中学习和预测的蓝图,它们可以帮助我们发现数据中的模式、关系和见解。在实际应用中,选择合适的机器学习算法对于解决特定问题至关重要,需要根据具体情况来选择最合适的算法来进行建模和预测。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









