






Stable Diffusion v3.0 api使用教程

今天Stable Diffusion v3.0的api终于可以使用, 效果真的出奇的好.
我这里测试了下给予Python环境的调用, 效果也是非常的好.
第一步, 注册API Key
如果想使用Stable Diffusion v3.0的API, 就要先注册并生成一个秘钥, 网址如下:
https://platform.stability.ai/account/keys
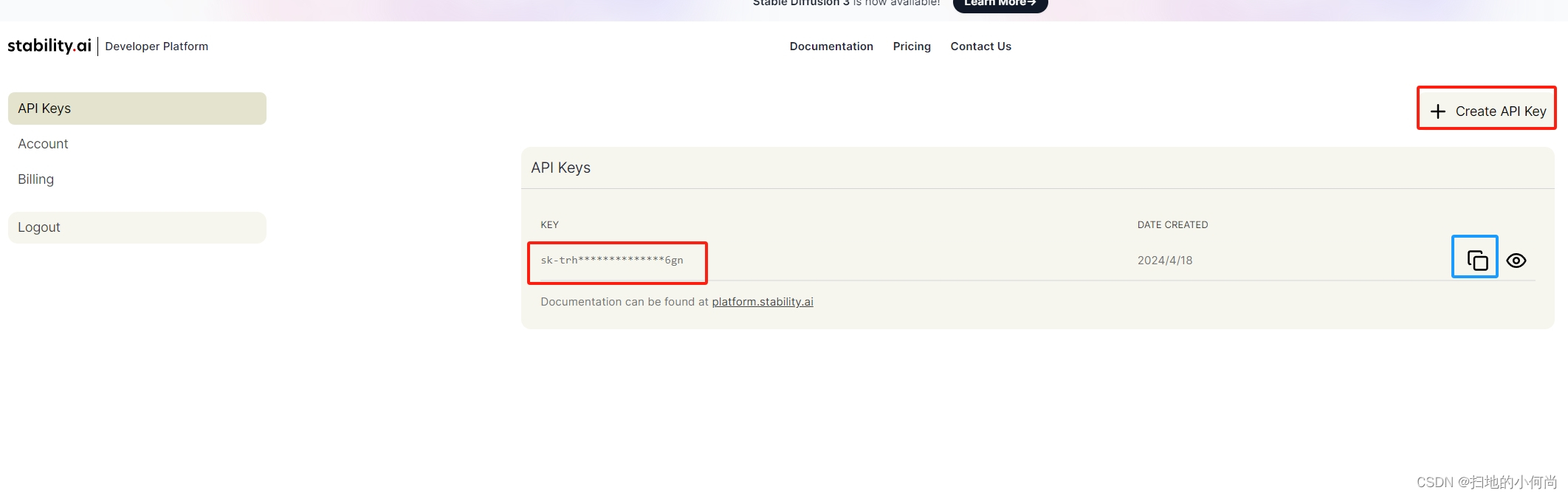
在下面的界面中点击"Create API Key"按钮, 就会生成红色框中的API Key, 然后点击蓝色框中复制按钮, 就可以保存下来.
第二步, 运行代码
import requests
response = requests.post(
f"https://api.stability.ai/v2beta/stable-image/generate/sd3",
headers={
"authorization": f"Bearer Your API Key",
"accept": "image/*"
},
files={"none": ''},
data={
"prompt": "An blue ship with golden wings",
"output_format": "jpeg",
},
)
if response.status_code == 200:
with open("./blue_ship_with_golden_wings.jpeg", 'wb') as file:
file.write(response.content)
else:
raise Exception(str(response.json()))
from PIL import Image
input_image = Image.open("./blue_ship_with_golden_wings.jpeg").convert("RGB")
display(input_image)
将上面的"Your API Key"替换为你刚才生成的, 然后自定义prompt字段就可以生成你的图像
我这里是在Jupyter环境下运行的, 所以直接可以看到如下效果.




















 518
518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











