







目录
一、概述
梯度下降法(Gradient descent )是一个一阶最优化算法,通常也称为最陡下降法 ,要使用梯度下降法找到一个函数的局部极小值 ,必须向函数上当前点对应梯度(或者是近似梯度)的反方向的规定步长距离点进行迭代搜索。 如果相反地向梯度正方向迭代进行搜索,则会接近函数的局部极大值点;这个过程则被称为梯度上升法 ,相反则称之为梯度下降法。
说起梯度下降算法,其实并不是很难,它的重要作用就是求函数的极值。梯度下降就是求一个函数的最小值,对应的梯度上升就是求函数最大值。虽然梯度下降与梯度上升都是求函数极值的算法,为什么我们常常提到“梯度下降”而不是梯度上升“呢?主要原因是在大多数模型中,我们往往需要求函数的最小值,即使求最大值也可以转化为求最小值(取反即可)。比如BP神经网络算法,我们得出损失函数,当然是希望损失函数越小越好,这个时候肯定是需要梯度下降算法的。梯度下降算法作为很多算法的一个关键环节,其重要意义是不言而喻的
二、算法思想
1、一维
梯度下降算法的思想是:先任取点(x0,f(x0)),求f(x)在该点x0的导数f"(x0),在用x0减去导数值f"(x0),计算所得就是新的点x1。然后再用x1减去f"(x1)得x2…以此类推,循环多次,慢慢x值就无限接近极小值点。
具体是有公式推导的,不过比较麻烦。其实这个算法是可以直观理解的。比如对于函数f(x)=x**2,当x大于0时,导数大于零,x减去导数值后变小;只要x大于零,每次减去一个大于零的导数,x值肯定变小。当x小于零时,导数小于零,减去小于零的数后x值增加,所以无论x0起始于何处,最终都能走到极值点0处。只不过有可能从单侧趋近(像走楼梯一样下降),也可能x一会儿大于极值点,一会儿小于极值点,交替地趋近,最终x趋于0。

2、多维
(1)确定当前位置的损失函数的梯度,对于,其梯度表达式为:
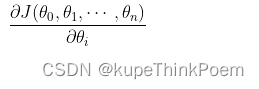
(2)用步长a乘以损失函数的梯度,得到当前位置下降的距离,即。
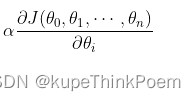
(3)如果梯度的向量的模接近于0或者两次函数值之间的差值接近于0则停止,否则进入第(4)步。(从条件可以看出梯度下降有可能求的是局部最优值)
(4)更新所有的参数值,更新表达式如下,更新完成后转入步骤(1):
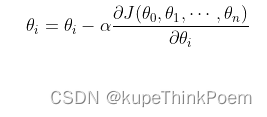
三、梯度下降算法类型
1、批量梯度下降算法
计算会每次从所有数据中计算梯度,然后求平均值,作为一次迭代的梯度,对于高维数据,计算量相当大,因此,把这种梯度下降算法称之为批量梯度下降算法。
2、随机梯度下降算法
由于批量下降法每迭代更新一次权重都需要计算所有样本误差,而实际问题中经常有上亿的训练样本,故效率偏低,且容易陷入局部最优解,因此提出了随机梯度下降算法。其每轮计算的目标函数不再是全体样本误差,而仅是单个样本误差,即每次只代入计算一个样本目标函数的梯度来更新权重,再取下一个样本重复此过程,直到损失函数值停止下降或损失函数值小于某个设定的阈值。此过程简单,高效,通常可以较好地避免更新迭代收敛到局部最优解。
3、小批量梯度下降算法
小批量梯度下降算法是综合了批量梯度下降算法和随机梯度下降算法的优缺点,随机选取样本中的一部分数据,通常最常用的也是小批量梯度下降算法,计算速度快,收敛稳定。
















 239
239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











