






写在开头,最近学习mmyolo的框架,想着它能将所有配置都写在一个config文件里,只需要改配置文件就可以改动模型,感觉挺方便的。
就想着Yolov6用mmyolo框架来实现,但mmyolo并没有提供v6的voc实现配置,v5是有的(看下图),因此博主想自己学着将VOC12数据集当作自定义数据集来实现。

想法虽好,但真实现起来,中途还是踩了不少坑啊!!! 因此在这总结,方便后来人-.-
论文:《YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications》
原理可以看mmyolo给的文档
一、环境安装和项目克隆
根据mmyolo给的文档15 分钟上手 MMYOLO 目标检测来快速上手,最好将这篇文档中的流程都过一遍,自己复现下,博主试过了,很快的。
二、数据集以及转换
2.1 数据准备
VOC2012数据集下载链接:https://pan.baidu.com/s/1E0WDCqxkvROpLVoOUMWdpQ?pwd=o05u
提取码:o05u
解压后文件格式应该是这样的。

2.2 数据集转换和划分
将VOC数据集转换为coco格式
这里可以自己创建一个项目用于转换,例如

其中merge.py就是下面的代码,用于转换数据集
import xml.etree.ElementTree as ET
import os
import json
from datetime import datetime
import sys
import argparse
coco = dict()
coco['images'] = []
coco['type'] = 'instances'
coco['annotations'] = []
coco['categories'] = []
category_set = dict()
image_set = set()
category_item_id = -1
image_id = 000000
annotation_id = 0
def addCatItem(name):
global category_item_id
category_item = dict()
category_item['supercategory'] = 'none'
category_item_id += 1
category_item['id'] = category_item_id
category_item['name'] = name
coco['categories'].append(category_item)
category_set[name] = category_item_id
return category_item_id
def addImgItem(file_name, size):
global image_id
if file_name is None:
raise Exception('Could not find filename tag in xml file.')
if size['width'] is None:
raise Exception('Could not find width tag in xml file.')
if size['height'] is None:
raise Exception('Could not find height tag in xml file.')
image_id += 1
image_item = dict()
image_item['id'] = image_id
image_item['file_name'] = file_name
image_item['width'] = size['width']
image_item['height'] = size['height']
image_item['license'] = None
image_item['flickr_url'] = None
image_item['coco_url'] = None
image_item['date_captured'] = str(datetime.today())
coco['images'].append(image_item)
image_set.add(file_name)
return image_id
def addAnnoItem(object_name, image_id, category_id, bbox):
global annotation_id
annotation_item = dict()
annotation_item['segmentation'] = []
seg = []
# bbox[] is x,y,w,h
# left_top
seg.append(bbox[0])
seg.append(bbox[1])
# left_bottom
seg.append(bbox[0])
seg.append(bbox[1] + bbox[3])
# right_bottom
seg.append(bbox[0] + bbox[2])
seg.append(bbox[1] + bbox[3])
# right_top
seg.append(bbox[0] + bbox[2])
seg.append(bbox[1])
annotation_item['segmentation'].append(seg)
annotation_item['area'] = bbox[2] * bbox[3]
annotation_item['iscrowd'] = 0
annotation_item['ignore'] = 0
annotation_item['image_id'] = image_id
annotation_item['bbox'] = bbox
annotation_item['category_id'] = category_id
annotation_id += 1
annotation_item['id'] = annotation_id
coco['annotations'].append(annotation_item)
def read_image_ids(image_sets_file):
ids = []
with open(image_sets_file, 'r') as f:
for line in f.readlines():
ids.append(line.strip())
return ids
def parseXmlFilse(data_dir, json_save_path, split='train'):
assert os.path.exists(data_dir), "data path:{} does not exist".format(data_dir)
labelfile = split + ".txt"
image_sets_file = os.path.join(data_dir, "ImageSets", "Main", labelfile)
xml_files_list = []
if os.path.isfile(image_sets_file):
ids = read_image_ids(image_sets_file)
xml_files_list = [os.path.join(data_dir, "Annotations", f"{i}.xml") for i in ids]
elif os.path.isdir(data_dir):
# 修改此处xml的路径即可
# xml_dir = os.path.join(data_dir,"labels/voc")
xml_dir = data_dir
xml_list = os.listdir(xml_dir)
xml_files_list = [os.path.join(xml_dir, i) for i in xml_list]
for xml_file in xml_files_list:
if not xml_file.endswith('.xml'):
continue
tree = ET.parse(xml_file)
root = tree.getroot()
# 初始化
size = dict()
size['width'] = None
size['height'] = None
if root.tag != 'annotation':
raise Exception('pascal voc xml root element should be annotation, rather than {}'.format(root.tag))
# 提取图片名字
file_name = root.findtext('filename')
assert file_name is not None, "filename is not in the file"
# 提取图片 size {width,height,depth}
size_info = root.findall('size')
assert size_info is not None, "size is not in the file"
for subelem in size_info[0]:
size[subelem.tag] = int(subelem.text)
if file_name is not None and size['width'] is not None and file_name not in image_set:
# 添加coco['image'],返回当前图片ID
current_image_id = addImgItem(file_name, size)
print('add image with name: {}\tand\tsize: {}'.format(file_name, size))
elif file_name in image_set:
raise Exception('file_name duplicated')
else:
raise Exception("file name:{}\t size:{}".format(file_name, size))
# 提取一张图片内所有目标object标注信息
object_info = root.findall('object')
if len(object_info) == 0:
continue
# 遍历每个目标的标注信息
for object in object_info:
# 提取目标名字
object_name = object.findtext('name')
if object_name not in category_set:
# 创建类别索引
current_category_id = addCatItem(object_name)
else:
current_category_id = category_set[object_name]
# 初始化标签列表
bndbox = dict()
bndbox['xmin'] = None
bndbox['xmax'] = None
bndbox['ymin'] = None
bndbox['ymax'] = None
# 提取box:[xmin,ymin,xmax,ymax]
bndbox_info = object.findall('bndbox')
for box in bndbox_info[0]:
bndbox[box.tag] = int(box.text)
if bndbox['xmin'] is not None:
if object_name is None:
raise Exception('xml structure broken at bndbox tag')
if current_image_id is None:
raise Exception('xml structure broken at bndbox tag')
if current_category_id is None:
raise Exception('xml structure broken at bndbox tag')
bbox = []
# x
bbox.append(bndbox['xmin'])
# y
bbox.append(bndbox['ymin'])
# w
bbox.append(bndbox['xmax'] - bndbox['xmin'])
# h
bbox.append(bndbox['ymax'] - bndbox['ymin'])
print('add annotation with object_name:{}\timage_id:{}\tcat_id:{}\tbbox:{}'.format(object_name,
current_image_id,
current_category_id,
bbox))
addAnnoItem(object_name, current_image_id, current_category_id, bbox)
json_parent_dir = os.path.dirname(json_save_path)
if not os.path.exists(json_parent_dir):
os.makedirs(json_parent_dir)
json.dump(coco, open(json_save_path, 'w'))
print("class nums:{}".format(len(coco['categories'])))
print("image nums:{}".format(len(coco['images'])))
print("bbox nums:{}".format(len(coco['annotations'])))
if __name__ == '__main__':
"""
脚本说明:
本脚本用于将VOC格式的标注文件.xml转换为coco格式的标注文件.json
需要改动参数说明:
--voc-dir=voc_data_dir,改为voc路径,例如:'../VOCdevkit\VOC2012'
--save-path=json_save_path:保存json文件输出的文件夹,例如:'./data/val.json'
--type=split:主要用于voc2012查找xx.txt,如train.txt.
"""
parser = argparse.ArgumentParser()
parser.add_argument('-d', '--voc-dir', type=str, default='../VOCdevkit\VOC2012', help='voc path')
parser.add_argument('-s', '--save-path', type=str, default='./data/train.json', help='json save path')
parser.add_argument('-t', '--type', type=str, default='train', help='only use in voc2012/2007')
opt = parser.parse_args()
if len(sys.argv) > 1:
print(opt)
parseXmlFilse(opt.voc_dir, opt.save_path, opt.type)
else:
# voc_data_dir = r'D:\dataset\VOC2012\VOCdevkit\VOC2012'
voc_data_dir = '../VOCdevkit\VOC2012'
json_save_path = './data/train.json'
split = 'train'
parseXmlFilse(data_dir=voc_data_dir, json_save_path=json_save_path, split=split)
2.2.1 踩坑注意
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
注意下面这是我刚开始是这样做的,但把我坑惨了,你看到这步可以参考,但最好别这样做
这样做会出现一个问题,就是在训练集和验证集标签不对应,不管你怎么训练,都不会有效果(就比如,你考试答案写错题了,无论你写的多好都是错的)
上述代码需要运行两遍,因为一遍将train转换,第二遍再将val转换,转换后的格式

再将其放入如下格式中这个data文件是mmyolo项目里的,也就是之前克隆下来的,将其放入

-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
2.2.2 正确的做法
这里给出代码,直接复制到上面代码将if语句中的替换即可
if __name__ == '__main__':
"""
脚本说明:
本脚本用于将VOC格式的标注文件.xml转换为coco格式的标注文件.json
需要改动参数说明:
--voc-dir=voc_data_dir,改为voc路径,例如:'../VOCdevkit\VOC2012'
--save-path=json_save_path:保存json文件输出的文件夹,例如:'./data/val.json'
--type=split:主要用于voc2012查找xx.txt,如train.txt.
"""
parser = argparse.ArgumentParser()
parser.add_argument('-d', '--voc-dir', type=str, default='../VOCdevkit\VOC2012', help='voc path')
parser.add_argument('-s', '--save-path', type=str, default='./data/trainval.json', help='json save path')
parser.add_argument('-t', '--type', type=str, default='annotations_all', help='only use in voc2012/2007')
opt = parser.parse_args()
if len(sys.argv) > 1:
print(opt)
parseXmlFilse(opt.voc_dir, opt.save_path, opt.type)
else:
# voc_data_dir = r'D:\dataset\VOC2012\VOCdevkit\VOC2012'
voc_data_dir = '../VOCdevkit\VOC2012'
json_save_path = './data/trainval.json'
split = 'annotations_all'
parseXmlFilse(data_dir=voc_data_dir, json_save_path=json_save_path, split=split)
也就是用VOC2012的trainval,将train和val标签放到一起,转换后你可以看到
merge文件就是转换代码,生成的文件在data下
你如果跑过第一步环境安装和项目克隆中的(15 分钟上手 MMYOLO 目标检测)你的项目结构应该是这样

我们在data文件下创建voc目录结构如下图所示

其中将之前转换后的annotations_all.json放到annotations文件中
test.json和trainval.json之后划分后会自动生成.

将VOC2012train+val对应的图片放入images文件中,不过VOC图像不仅包括目标检测还包括分割的
VOC12总共:17125张图片,而train+val:11540张图片
这里如果不想自己分的话博主直接给出整合后的trainval数据集链接下载
链接:https://pan.baidu.com/s/1Tan3tgO1xRtzJxJ9T7SKug?pwd=h4rv
提取码:h4rv
2.3 检查转换为coco的标签
转换后我们需要检查标签是否有问题,
打开mmyolo项目,在终端输入如下命令
python tools/analysis_tools/browse_coco_json.py --img-dir ./data/voc/images --ann-file ./data/voc/annotations/annotations_all.json

运行结果如下图所示,每3s会切换下一张图片,可以检测框以及类别是否会出错
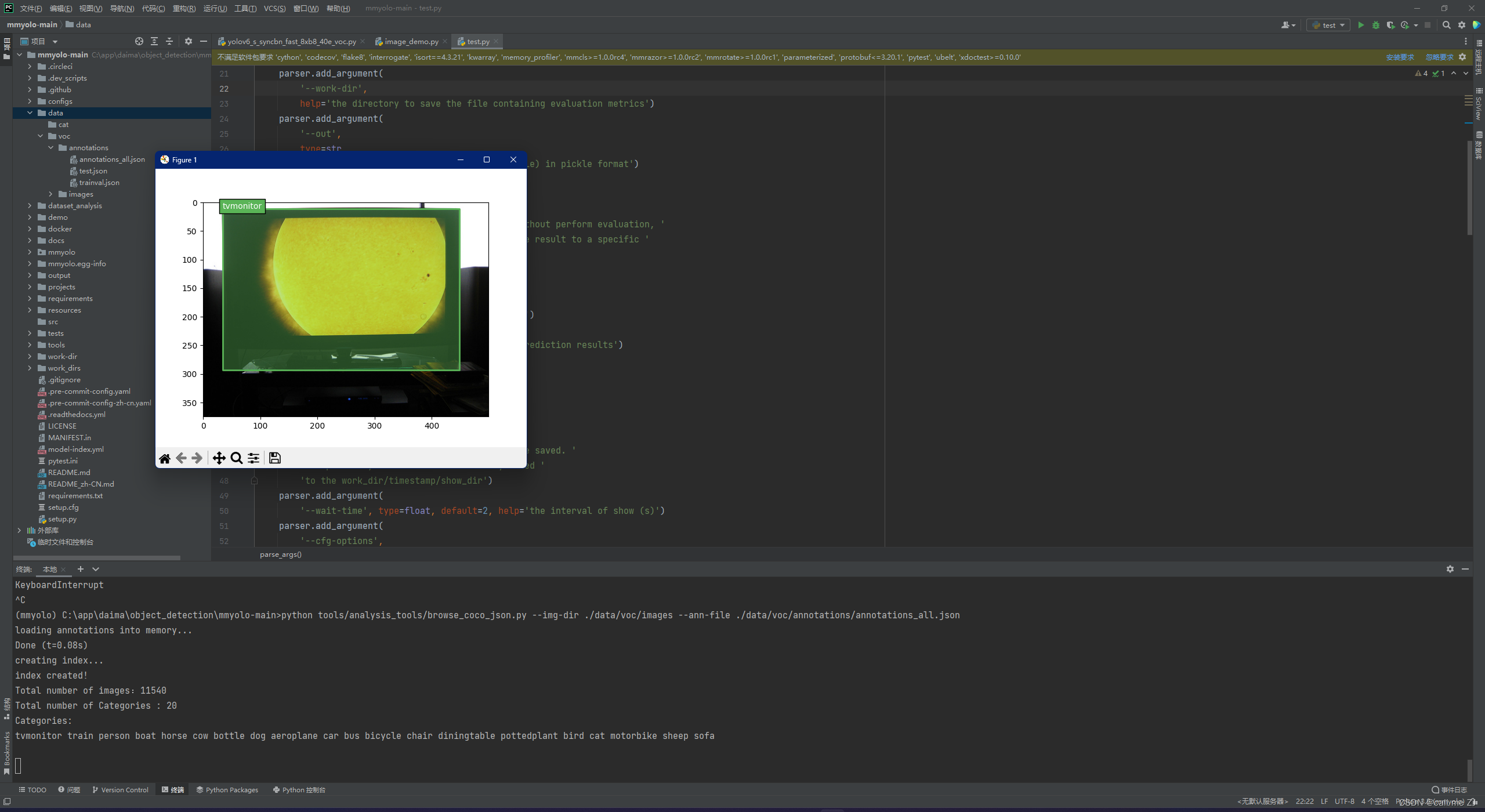
大家可以多看几张图片,如果检测框以及类别都每问题就在终端ctrl+c关闭就行了
2.4 数据集划分
上面annotations(标签)+images(图像)都准备好后,就可以划分数据集了
注意:本来博主是打算用原本VOC的train(5718张)当训练集,用val(5824张)当验证集的,但是上面也说了,train和val分别转换为coco标签后里面的类别不一样,导致训练不了
打开mmyolo项目,在终端输入
python tools/misc/coco_split.py --json ./data/voc/annotations/annotations_all.json --out-dir ./data/voc/annotations --ratios 0.7 0.3 --shuffle --seed 10
"""
参数解释:
--json:之前转换为coco数据集后的标签
--out-dir:划分后文件的保存路径
--ratios:划分比例,train:val,如需test,写三个参数即可比如0.6 0.2 0.2
--shuffle:是否打乱
--seed:随机种子
"""
划分后格式如下图所示

三、训练配置文件
3.1 创建配置文件
根据下图创建文件夹以及.py文件

这里给出配置文件中代码
"""
需要根据自己环境修改的参数
data_root:VOC目录的路径
其他epoch,batch-size之类的参数,直接看配置吧,基本都写注释了很容易理解
batch-size参数如果显存不够的话自己适当调小,博主显卡3070ti(8g)
"""
_base_ = '../yolov6/yolov6_s_syncbn_fast_8xb32-400e_coco.py'
max_epochs = 30 # 训练的最大 epoch
data_root = 'C:/app/daima/object_detection/mmyolo-main/data/voc/' # 数据集目录的绝对路径
# 结果保存的路径,可以省略,省略保存的文件名位于 work_dirs 下 config 同名的文件夹中
# 如果某个 config 只是修改了部分参数,修改这个变量就可以将新的训练文件保存到其他地方
work_dir = './work_dirs/yolov6_s_syncbn_fast_8xb8_40e_voc'
# load_from 可以指定本地路径或者 URL,设置了 URL 会自动进行下载,因为上面已经下载过,我们这里设置本地路径
load_from = 'https://download.openmmlab.com/mmyolo/v0/yolov6/yolov6_s_syncbn_fast_8xb32-400e_coco/yolov6_s_syncbn_fast_8xb32-400e_coco_20221102_203035-932e1d91.pth'
# 根据自己的 GPU 情况,修改 batch size,YOLOv5-s 默认为 8卡 x 16bs
train_batch_size_per_gpu = 8
train_num_workers = 4 # 推荐使用 train_num_workers = nGPU x 4
save_epoch_intervals = 2 # 每 interval 轮迭代进行一次保存一次权重
# 根据自己的 GPU 情况,修改 base_lr,修改的比例是 base_lr_default * (your_bs / default_bs)
base_lr = _base_.base_lr * (8 / 32)
# 根据 class_with_id.txt 类别信息,设置 class_name
class_name = ('tvmonitor', 'train', 'person', 'boat', 'horse', 'cow', 'bottle', 'dog', 'aeroplane', 'car', 'bus',
'bicycle', 'chair', 'diningtable', 'pottedplant', 'bird', 'cat', 'motorbike', 'sheep', 'sofa')
num_classes = len(class_name)
metainfo = dict(classes=class_name)
train_cfg = dict(
max_epochs=max_epochs,
# val_begin=20, # 第几个 epoch 后验证,这里设置 20 是因为前 20 个 epoch 精度不高,测试意义不大,故跳过
val_interval=5 # 每 val_interval 轮迭代进行一次测试评估
)
model = dict(
backbone=dict(frozen_stages=4),
bbox_head=dict(head_module=dict(num_classes=num_classes)),
train_cfg=dict(
initial_assigner=dict(num_classes=num_classes),
assigner=dict(num_classes=num_classes)))
train_dataloader = dict(
batch_size=train_batch_size_per_gpu,
num_workers=train_num_workers,
dataset=dict(
data_root=data_root,
metainfo=metainfo,
ann_file='annotations/trainval.json', # 训练标签
data_prefix=dict(img='images/'))) # 保存图片的文件名
val_dataloader = dict(
dataset=dict(
metainfo=metainfo,
data_root=data_root,
ann_file='annotations/test.json', # 验证标签
data_prefix=dict(img='images/')))
test_dataloader = val_dataloader
val_evaluator = dict(ann_file=data_root + 'annotations/test.json')
test_evaluator = val_evaluator
optim_wrapper = dict(optimizer=dict(lr=base_lr))
default_hooks = dict(
# 设置间隔多少个 epoch 保存模型,以及保存模型最多几个,`save_best` 是另外保存最佳模型(推荐)
checkpoint=dict(
type='CheckpointHook',
interval=save_epoch_intervals,
max_keep_ckpts=1,
save_best='auto'),
param_scheduler=dict(max_epochs=max_epochs),
# logger 输出的间隔
logger=dict(type='LoggerHook', interval=5))
# wandb可视化
# visualizer = dict(
# vis_backends = [dict(type='LocalVisBackend'),
# dict(
# type='WandbVisBackend',
# init_kwargs=dict(
# project='Yolo', # 项目名字
# name='yolo_v6' # 模型名字
# )
# )]) # noqa
# TensorBoard可视化
# visualizer = dict(vis_backends=[dict(type='LocalVisBackend'),dict(type='TensorboardVisBackend')])
其中代码最后的wandb可视化,你如果会用wandb的话把注释取消就行,不会用就注释把,否则会报错
同理tensorboard,这两个记录训练过程的用一个即可,百度搜一下很简单的,
其中wandb需要注册账号,而tensorboard只需要pip 安装库即可用了
3.2 可视化config配置中数据集处理部分
上面的训练配置文件准备好后,在mmyolo项目的终端运行下面代码
python tools/analysis_tools/browse_dataset.py configs/custom_dataset/yolov6_s_syncbn_fast_8xb8_40e_voc.py --show-interval 3
脚本 tools/analysis_tools/browse_dataset.py 能够帮助用户去直接窗口可视化 config 配置中数据处理部分
比如这样,经过Mosaic等一系列数据增强处理后的训练图片

这里也需要看检测框和类别是否是对的
注意:如果按2.2.1的步骤来划分数据集的话,在可视化config配置中数据处理部分的类别显示就会出错,博主之前就被坑惨了,这步的类别一致不对,例如horse的图像标签显示的是dog,找了一天原因才发现是数据集标签的问题
四、训练和可视化
4.1 训练
在终端输入如下命令
python tools/train.py configs/custom_dataset/yolov6_s_syncbn_fast_8xb8_40e_voc.py
博主3070ti训练时间:1h 30m 45s
训练结束后会产生work_dirs文件夹,在对应配置的文件名下会保存相关文件,一串数字的文件是表示运行时间
可能文件数目不同,因为博主删了点东西

4.2 可视化(可选)
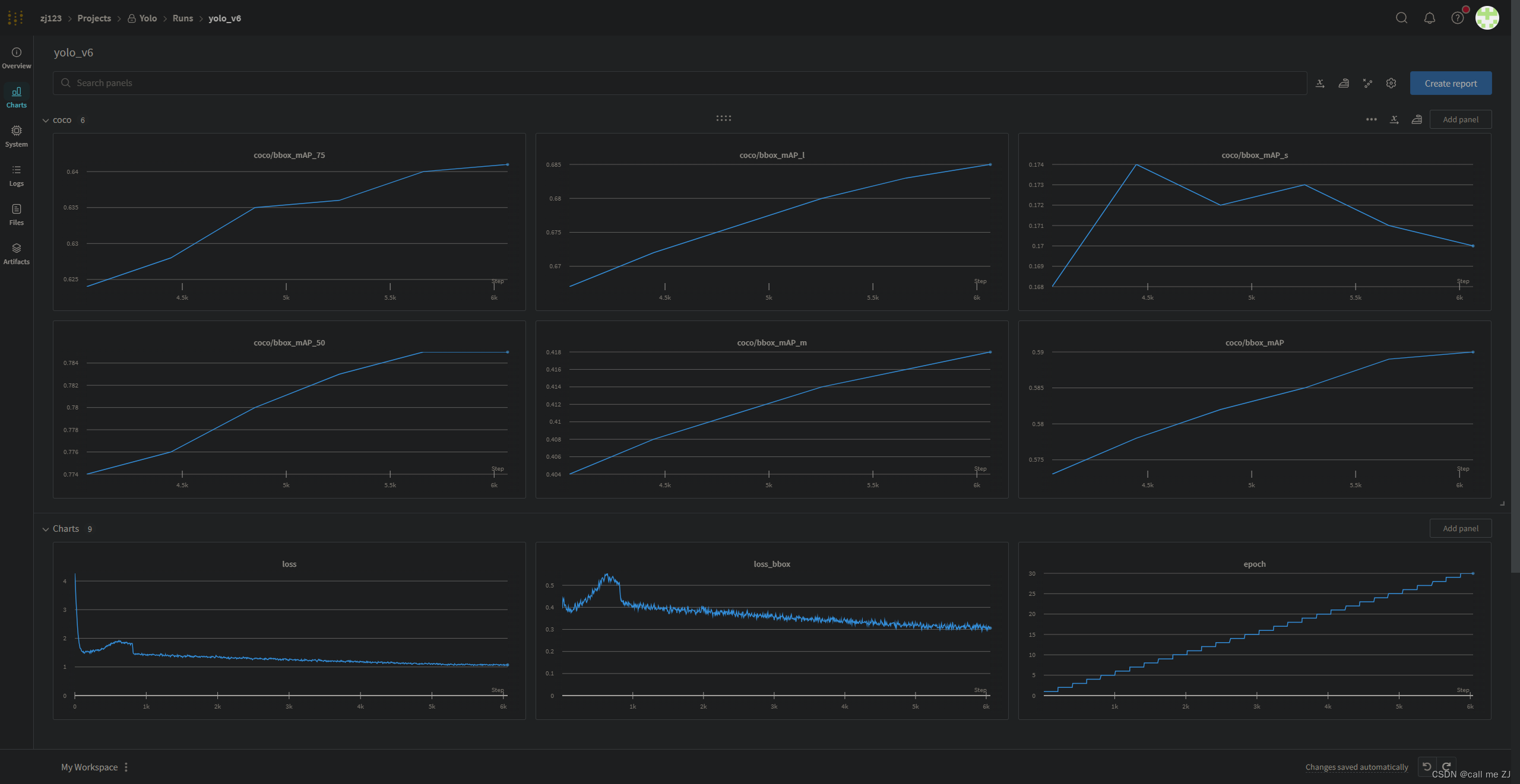
如果你之前在3.1配置文件中选择用了wandb或tensorboard可视化工具的话,在这你就可以看到训练过程图
wandb:
wandb记录的训练过程图
tensorboard:
这里博主没有用,如果大家用了的话,
训练完后Tensorboard 文件会生成在可视化文件夹 work_dirs/yolov6_s_syncbn_fast_8xb8_40e_voc.py/{时间}/vis_data 下
在终端运行命令,会给个链接,大家点进去就可以看了
tensorboard --logdir=work_dirs/yolov6_s_syncbn_fast_8xb8_40e_voc.py
五、推理和测试
5.1 模型推理
用上一步训练完保存的权重epoch_30.pth
python demo/image_demo.py demo/demo.jpg ./configs/custom_dataset/yolov6_s_syncbn_fast_8xb8_40e_voc.py ./work_dirs/yolov6_s_syncbn_fast_8xb8_40e_voc/epoch_30.pth --out-dir ./demo/output
推理结果保存在

效果如图所示,可能是训练轮数太少了,最大的椅子都识别错了,增加训练epoch可能效果会更好

当然也可以用视频进行推理,用demo/video_demo.py文件即可,将图片路径改为视频路径
5.2 模型测试
在mmyolo终端运行以下测试命令,
python tools/test.py configs/custom_dataset/yolov6_s_syncbn_fast_8xb8_40e_voc.py work_dirs/yolov6_s_syncbn_fast_8xb8_40e_voc/epoch_30.pth --show-dir show_results
运行代码后,测试结束会显示voc数据集在coco标准的精度,
这里我们主要看最后一行,平均精度bbox_map:59%,iou=0.5的精度bbox_map_50:78%

你不仅可以得到模型训练部分所打印的 AP 性能,还可以将推理结果图片自动保存至 work_dirs/yolov6_s_syncbn_fast_8xb8_40e_vo/{时间}/show_results 文件夹中。

下面为show_results中一张结果图片,左图为实际标注,右图为模型推理结果

最后
到这基本训练流程就完成了,如果对你有帮助请点点赞

博主还会将训练完的模型打包,放到评论区链接中!!!















 7155
7155











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









