







介绍
深度学习综述年年有,今年特别多。随着深度学习在机器学习领域的快速发展,对每个任务进行算法的总结对于之后的发展是有益的。综述可以梳理发展脉络,对比算法好坏,并为以后的研究方向进行启发。本文是在NLP领域中重要的任务-文本分类进行综述的文章。论文中涉及到的范围很广,从MLP,RNN,CNN到GNN,RL。我对GNN,RL也不是很熟悉,只是简单记录一下,供自己参考。
文本分类介绍
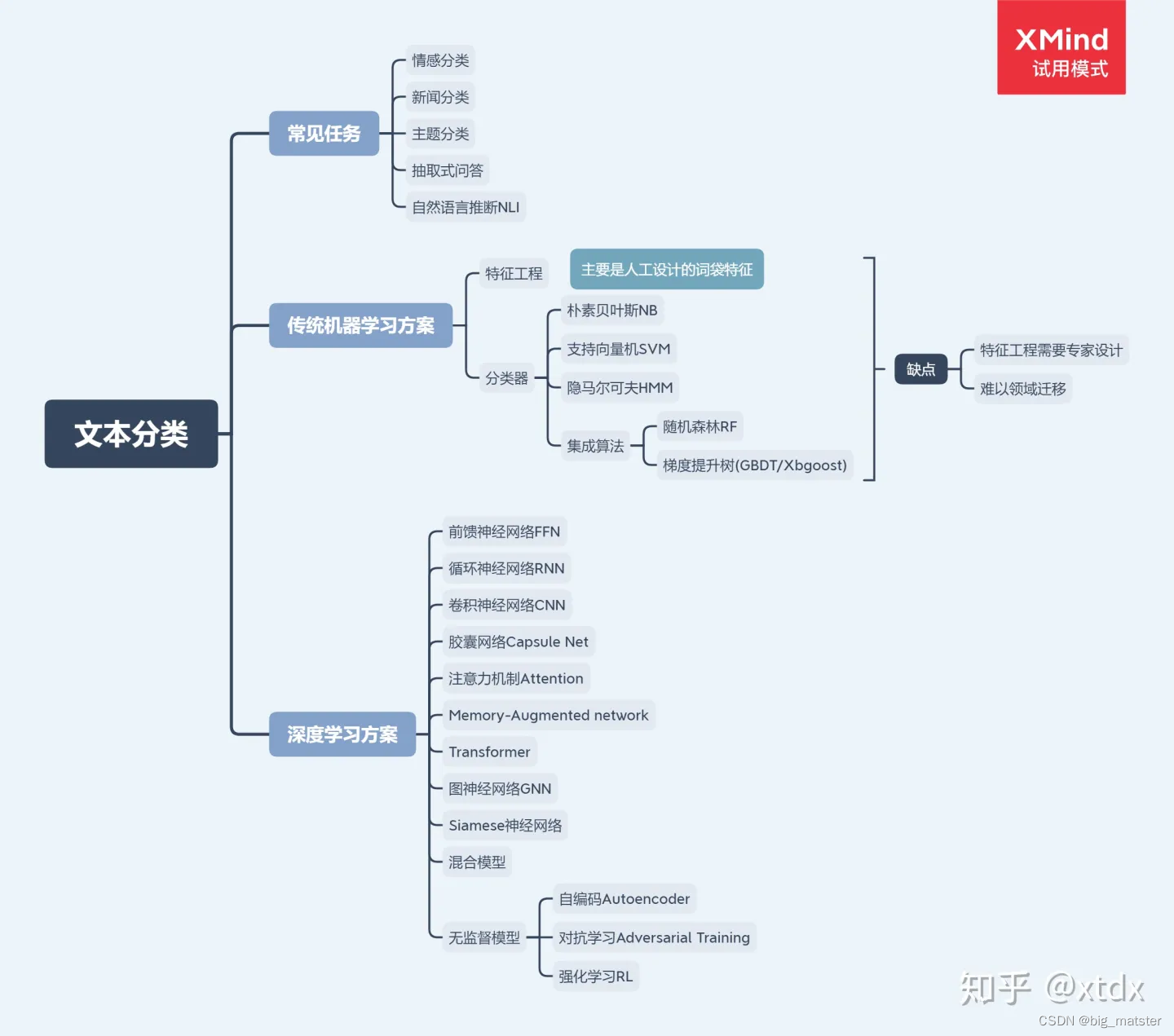
总结
这项工作中,作者:
- 详细回顾了近年来开发的150多个基于深度学习的文本分类模型,并讨论了其技术贡献,相似性和优势。
- 总结了超过40个广泛用于文本分类的流行数据集。
- 总结了性能评价指标,一组深度学习模型的性能进行了定量分析。
- 讨论了剩下挑战和未来方向。
摘要
回顾了近年来的150多个基于深度学习的文本分类模型,并讨论了它们的技术贡献、相似性和优势。总结了40多个广泛用于文本分类的流行数据集。最后,对不同深度学习模型在流行基准上的表现进行量化分析,并探讨未来的研究方向。
介绍
自动文本分类方向大致分为3类:总结如下:
- 基于规则的方法
- 基于机器学习的方法(数据驱动)
- 混合方法
- 基于规则的方法使用一组预定义的规则将文本分类为不同类别,这些方法需要对领域有深入的了解,而且系统很难维护。
- 基于机器学习的方法利用预先标记的例子作为训练数据,学习文本片段与其标签之间的内在联系。因此,基于机器学习的方法可以检测数据中隐藏的模式,具有更高的可扩展性,并且可以应用于各种任务。近年来,机器学习模型引起了人们的广泛关注。大多数经典的基于机器学习的模型遵循流行的两步过程,第一步从文档(或任何其他文本单元)中提取一些手工制作的特征,第二步将这些特征输入分类器进行预测。一些流行的手工制作功能包括单词包(BoW)及其扩展。常用的分类算法有朴素贝叶斯、支持向量机、隐马尔可夫模型、梯度提升树和随机森林。两步方法有几个局限性。例如,依赖手工制作的特性需要繁琐的特性工程和分析才能获得良好的性能。此外,特征设计对领域知识的依赖性强,使得该方法很难推广到新的任务中。最后,这些模型不能充分利用大量的训练数据,因为特征(或特征模板)是预先定义的。
- 2012年开始一个范式转变,当时一个基于深度学习的模型AlexNet以很大的优势赢得了ImageNet的竞争。自那时起,深度学习模型被应用于计算机视觉和自然语言处理的一系列任务,提高了最新的水平。这些模型试图学习特征表示并以端到端的方式执行分类(或回归),其不仅能够发现数据中的隐藏模式,而且可以从一个应用转移到另一个应用,耗不奇怪,这些模型正在近年来各种文本分类任务的主流框架。
- 混合方法使用基于规则和机器学习的组合来进行预测。
根据它们的神经网络结构将这些工作分为几类,例如基于递归神经网络、卷积神经网络、Transformer、注意力、胶囊网络等模型。
Introduction
自动文本分类的方法可以分为三类:Rule-based methods基于规则的方法、 Machine learning (data-driven) based methods数据驱动的机器学习方法、Hybrid methods混合方法。
基于规则的方法使用一组预定义的规则将文本分类成不同的类别。例如,带有单词“football”、“basketball”或“baseball”的任何文档都被指定为“sport”标签。
这些方法需要对领域有深入的了解,并且系统很难维护。基于机器学习的方法学习使用预先标记的例子作为训练数据,可以学习文本片段和它们的标签之间的内在关联,根据过去对数据的观察进行分类。因此基于机器学习的方法可以检测数据中的隐藏模式,具有更强的可扩展性,可以应用于各种任务。这与基于规则的方法相反,基于规则的方法对于不同的任务需要不同的规则集。(基于规则方法对不同任务需要不同的规则集)
混合方法,顾名思义,是将基于规则的方法和机器学习方法结合起来进行预测。
大多数经典的基于机器学习的模型遵循流行的两步程序,第一步从文档(或任何其他文本单元)中提取一些手工制作的特征,第二步将这些特征提供给分类器进行预测。一些流行的手工制作特征方法包括词袋模型bag of words (BoW)及其扩展。流行的分类算法包括朴素贝叶斯、支持向量机(SVM)、隐马尔可夫模型(HMM)、梯度增强树和随机森林。两步方法有几个局限性。例如,依赖手工制作的特性需要冗长的特性工程和分析才能获得良好的性能; 由于设计特征对领域知识的强烈依赖,使得该方法难以推广到新任务; 因为特征(或特征模板)是预先定义的, 这些模型不能充分利用大量的训练数据。
2012年,基于深度学习的模型AlexNet在ImageNet竞赛中大胜,自那以后,深度学习模型被广泛应用于计算机视觉和自然语言处理的任务中。这些模型试图学习特征表示,并以端到端的方式进行分类(或回归)。它们不仅能够发现数据中隐藏的模式,而且从一个应用程序到另一个应用程序的可转移性要大得多。这些模型正在成为近年来各种文本分类任务的主流框架。
文本分类任务
-
不同的文本分类任务有:情感分析sentiment analysis、新闻分类news categorization、主题分类topic analysis、问答question answering(QA)和自然语言推理Nature language inference(NLI)。
-
QA系统有两种类型:抽取式和生成式。抽取式给定一个问题和一组候选答案,我们需要将每个候选答案分类为正确或不正确。生成QA学习从头开始生成答案(例如使用seq2seq模型),这种本文不讨论。
-
NLI也被称为识别文本涵recognizing textual entailment(RTE),它预测一个文本的意义是否可以从另一个文本中推断出来。系统需要为每对文本单元分配一个标签,例如包含,矛盾和中性。 释义Paraphrasing是NLI的一种广义形式,也称为文本对比较。 任务是测量一个句子对的语义相似度,以确定一个句子是否是另一个句子的释义。
用于文本分类的深度学习模型
- 基于前馈网络模型:将文本视为词袋
- 基于RNN模型, 将文本视为一个单词序列,旨在捕获单词的相关性和文本结构。
- 基于CNN模型:训练识别文本中的模式,如关键短语,以便分类。
- 胶囊网络:解决了CNN的池化操作所带来的信息丢失问题,最近被应用于文本分类。
- 注意力机制:有效的识别文中中相关词汇,并已经成为开发深度学习模型的有用工具。
- 记忆增强网络:其将神经网络与外部记忆结合在一起,模型可以读取和写入。
- Transformer: 其允许比RNN更多的并行化,使得使用GPU集群高效,使得预训练非常大的语言模型成为可能。
- 图神经网络:用于捕捉自然语言内部图形结构,如句法和语义分析树。
- 孪生网络:设计用于文本分类,和文本匹配的一个特殊情况。
- 混合模型:注意力机制、CNN、RNN模型等结合起来,捕捉句子和文档局部和全局特征。
- **其他模型:**使用自动编码器和对抗性训练的无监督学习,以及强化学习。
- 内存增强网络:其将神经网络和外部存储器形式结合在一起,模型可以从中读取和写入数据。
- Siamese Neural Networks,用于文本匹配,这是文本分类的一种特殊情况(2.9)。
模型具体介绍
- Feed forward Neural Networks
前馈神经网络是一种最简单的神经网络,各神经元分层排列。每个神经元只与前一层的神经元相连。接收前一层的输出,并输出给下一层.各层间没有反馈。
将文本视为一袋单词。对于每个单词,使用诸如word2vec或Glove之类的嵌入模型学习向量表示,将向量的总和或平均值作为文本的表示,将其通过一个或多个前馈层,然后使用分类器(例如逻辑回归,朴素贝叶斯或SVM)对最终层的表示进行分类。
这些模型的一个示例是深度平均网络(DAN),其体系结构如图1所示。模型旨在显式地学习文本的组成。DAN在具有较高语法差异的数据集上的表现优于语法模型。 Joulin等提出了一种简单而有效的文本分类器,称为fastText。像DAN一样,fastText将文本视为一袋单词。与DAN不同,fastText使用一袋n-gram作为附加功能来捕获本地单词顺序信息。事实证明,这在实践中非常有效,同时可以获得与显式使用单词顺序的方法相当的结果。
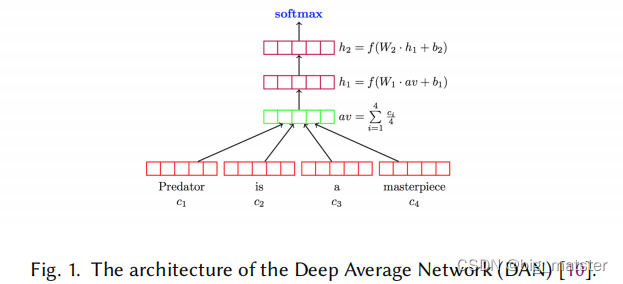
FastText:
在文本分类任务中,fastText(浅层网络)往往能取得和深度网络相媲美的精度,却在训练时间上比深度网络快许多数量级。fastText模型的前半部分,即从输入层输入到隐含层输出部分,主要在做一件事情,生成用来表征文档的向量。那么它是如何做的呢?叠加构成这篇文档的所有词及n-gram的词向量,然后取平均。叠加词向量背后的思想就是传统的词袋法,即将文档看成一个由词构成的集合,fastText模型的后半部分,即从隐含层输出到输出层输出,会发现它就是一个softmax线性多类别分类器,分类器的输入是一个用来表征当前文档的向量。于是fastText的核心思想就是:将整篇文档的词及n-gram向量叠加平均得到文档向量,然后使用文档向量做softmax多分类。这中间涉及到两个技巧:字符级n-gram特征的引入以及分层Softmax分类。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 4788
4788

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











