







人机对话概述
人机对话是指,让机器理解和运用自然语言实现人机通信的技术,如图1所示,通过人机对话交互,用户可以查询信息,如示例中的第一轮对话,用户查询天气信息,用户也可以和机器机型聊天,如示例中的第二轮对话,用户还可以获取特定服务,如示例中的最后两轮对话,用户获取调用票预定服务。

人机对话是人工智能的重要挑战,最近几年随着人工智能的兴趣,人机对话研究也越来越火热,图2 是NLP顶级会议
A
C
L
ACL
ACL和
E
M
N
L
P
EMNLP
EMNLP,自2010年以来对话相关论文的数量,可以看出从2016年开始看出从2016年以来对话论文的数量增长迅猛,2018年相比于2010年对话论文数量有数倍增长,对话相关技术的逐步成熟,也引发了工业界研发对话产品的热潮,产品类型主要包括**:语音助手、智能音箱和闲聊软件**。
语音助手:指在硬件设备上或者APP软件上,植入人机对话程序辅助用户通过语音方式,使用宿主设备或程序上的功能,如内容搜索、信息查询、音乐播放、闹铃设定以及餐馆和票务预定等功能,该类型的产品主要有:百度小度、苹果
S
i
r
i
Siri
Siri、Google Now、微软小娜,阿里小蜜。
智能音箱: 是为对话系统独立设计的音箱产品,和语音助手的区别是,智能音箱独立设计了一套语音输入和输出系统。用于实现远场语音控制,即远距离的语音对话交互,如家具环境下家电设备的控制,该类型的产品有百度小度音箱和小度在家,亚马逊Echo、Google Home、阿里天猫精灵、小米小爱等;.
闲聊软件: 主要是借助情感计算技术与用户进行情感交流。如微软小冰。
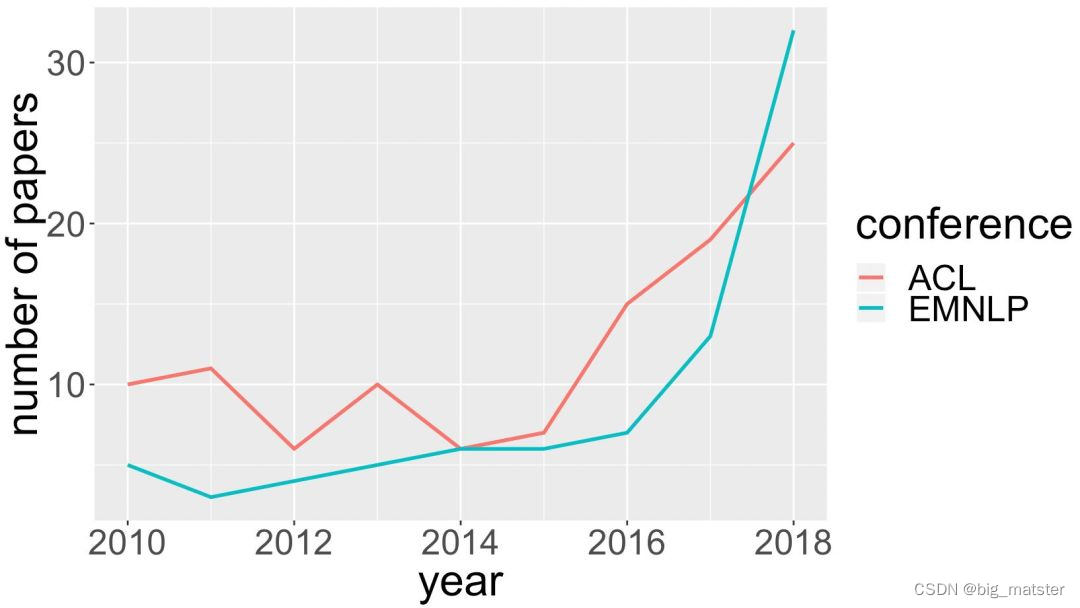
对话论文在NLP会议上的增长趋势
人机对话技术
人机对话技术研究最早可追溯至上世纪六十年代,自阿兰·图灵提出通过图灵测试[1]来检验机器是否具有人类智能的设想以来,研究人员就开始致力于人机对话系统的研究。1966年MIT的计算机科学家Joseph Weizenbaum开发了Eliza[2]聊天系统,用于模拟心理治疗师对精神病患者进行心理治疗。1972年精神病医生Kenneth Colby基于Eliza的原理开发了Parry[3]聊天系统,只不过模拟的不是心理治疗师,而是精神病患者。1998年CMU的Randy Pausch开发的Alice[4]被认为是最像人类的聊天机器人,还获得了三届人工智能竞赛大奖-罗布纳奖(2000年、2001年和2004年),同时孕育了用于开发聊天机器人的AIML语言。
随着深度学习技术的兴起,以及对话语料为基础使用神经网络模型进行对话学习是近几年人机对话的主流研究方法,人机对话根据功能不同可以分为任务完成、问答、和聊天三种类型。不同类型采用的技术手段和评价方法也不同,下面我们对三种类型的对话进行简单的介绍。
任务完成模型
用于完成任务的特定需求,比如电影票预订、机票预定、音乐播放等。以完成任务的成功率作为评价标准,这类对话的特点是用户需求明确,往往需要通过多轮方式解决,主流的解决方案是2013年,Steve Young提出的POMDP[5]框架,如图3所示,涉及语言理解、对话状态跟踪、回复决策、语言生成等技术。

语言理解:理解用户输入中的语义和语用信息,语义信息通常由意图和槽位构成,一个意图表示一个用户需求,每个任务有多种类型的意图,每个意图有多个槽位信息。
在电影票预定中,意图类型有电影票预定,取消预定、和修改意图等意图。槽位有影院、日期、人数等。语用信息主要指交际功能、如询问、回答、陈述等。语言学家
H
a
r
r
y
B
u
n
t
Harry Bunt
HarryBunt,等人设计了一套通用交际功能的分类标准:共有88类,一共选用其中几类即可。
对话状态跟踪: 一个用户需求包含一个意图和多个槽位信息,而一次对话交互只能提供其中一部分信息,因此对话状态跟踪是根据每轮对话信息完善用户的完整需求信息。
回复决策:根据
D
S
T
DST
DST输出结果决策当前的回复动作,如槽位询问,槽位澄清或结果输出等。每个回复动作由一个交际功能和几个槽位构成。
语言生成:
根据
P
o
l
i
c
y
Policy
Policy输出的动作生成一个自然语言句子。
系统上实现上分为
P
i
p
e
l
i
n
e
Pipeline
Pipeline方式和
E
n
d
2
E
n
d
End2End
End2End方式,
P
i
p
e
l
i
n
e
Pipeline
Pipeline方式指的是每个技术模块单独实现,然后以管道形式连接成整个系统。
E
n
d
2
E
n
d
End2End
End2End:指的是一个模型同时实现各个技术模块的功能,使模块之间进行充分的信息共享。
问答类型
用于解决用户信息查询需求,主要是一问一答的对话形式,如美国总统是谁,以及回复答案的准确率作为评价标准,和NLP传统,Question Answering(QA)任务不同的是对话中的问答会涉及上下文的成分补全和指代消解技术。
聊天类型
用于解决用户的情感倾诉需求以及其它类型对话之间的衔接需求。和前两种对话类型的区别是该类型对话是开放性对话,用户的输入是开放的,用户可以输入任何合理的自然语言句子;系统的输出也是开放的,比如图1示例中用户输入“看来今天不适合出门啊”,系统可以回复“是啊,还是呆在家好”,也可以回复“可以去电影院看电影”,甚至可以回复“知足吧,至少你有机会出门,我没脚只能天天呆机房”等等。由于对话的开放性,其技术难度和挑战性要远高于其它类型对话,目前的解决方案主要是检索和生成两种。
检索方案
检索方案采用的是信息检索技术,分为候选回复召回和候选回复排序两个阶段。如图4所示,
- 召回阶段:先离线对对话语料建立倒排索引库****,在线对话时根据用户输入从索引库中检索候选回复
- 排序阶段:根据对话上下文进一步计算候选回复的相关性,以选出最佳候选作为系统输出.
- 2016年 Z h o u Zhou Zhou等人提出在字粒度和句子粒度级别分别计算上下文和候选回复相关性,然后进一步融合。有效的改善了排序效果,提升回复质量。
- 检索方案从百亿级语料库中检索回复,可以有效的解决聊天类型对话的开放性问题,而且检索出的回复语义丰富度和流畅性都很好,在单轮对话中表现良好,但在多轮对话中,检索方案就有问题重重了,对话具有很强的语境关联性,多轮对话确立的语境在语料库中基本不存在,使用检索方案从语料库中选出的回复很难适用于当前语境,会存在多轮逻辑冲突、语义相关性差等问题。这是检索方案的致命缺陷。

生成方案
生成方案不是从语料库中选出历史回复、而是生成全新的回复。语料库只是用于对话逻辑的学习,是目前学术界的一个研究热点,生成方案主要采用 S e q 2 S e q Seq2Seq Seq2Seq的对话框架,对话的上文作为模型的输入,对话的下文作为模型的输出,使用 E n c o d e r Encoder Encoder表示输入, D e c o d e r Decoder Decoder预测输出,如图5所示,除了Seq2Seq框架,有不少研究人员也开展了基于GAN和强化学习的对话框架,GAN模型中的 g e n e r a t o r generator generator模型用于生成回复, d i s c r i m i n a t o r discriminator discriminator模型用户判断输入回复和标准回复还是预测回复.强化学习中的 r e w a r d reward reward为语义相关性、句子流畅性等。 a c t i o n action action为生成的回复句子。
生成方案训练时候,从对话语料中学习对话逻辑,预测时根据用户输入预测和上下文相关的回复输出。目前是生成模型还存在安全回复,机器个性化和效果评估等几个挑战性问题。
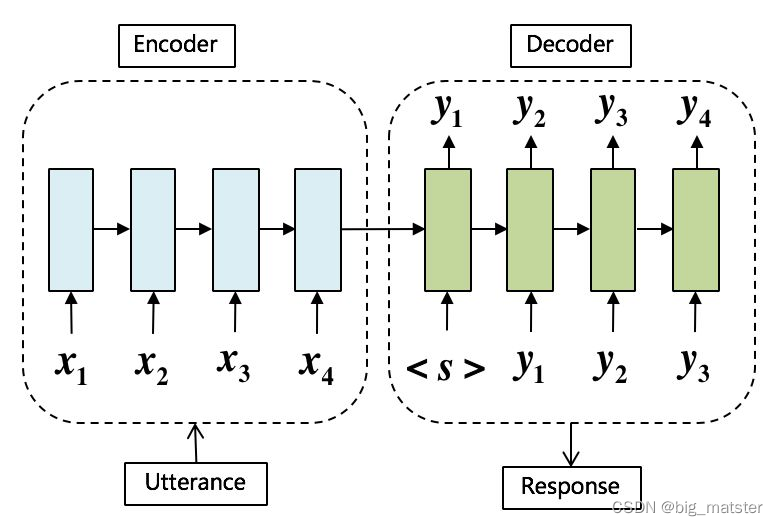
生成方案
由于聊天型对话的开放性特点,对话模型的效果评估上具有很大的挑战性,常见的评估方法**——预测结果和标准结果的匹配程度,难以准确的衡量聊天型对话的效果**,目前可靠的评估方法依然是人工评估,2017年Bengio团队提出用模型拟合人工评估的方式探索自动评估的解决方案[13]。闲聊对话系统可以通过和用户交互的轮次来自动衡量系统的效果,交互轮次越多说明用户对聊天效果越满意,也可以间接说明聊天系统效果越好。这和任务完成类型的评估是截然相反的,任务完成类型在成功完成任务的前提下对话轮次越少说明模型的效果越好。
- 用模型拟合人工评估的方式来探索自动评估的解决方案。
人机对话语料
早期的对话系统依赖于模板匹配技术,通过文本匹配查找相似输入的回复作为输出回复,使得系统的对话能力和灵活性存在很大的局限性。因此上世纪九十年代以来,研究人员开始进行基于数据驱动的对话系统研究。1990年Hemphill等人建设了旅行信息系统(ATIS)数据集[14],用于机票预订对话系统的研究[15];2001年Walker等人建设旅行规划数据集,用于旅行规划系统Communicator的研究[16];2013年微软建设了公交时刻表查询对话数据集用于对话状态跟踪(DSTC)技术的研究[17];2015年Alessandro Sordoni等人在Twitter上整理了2900万人-人对话数据集[18],用于聊天对话技术的研究;2016年Ryan Lowe等人从Ubuntu技术论坛上整理了700万Ubu**ntu社区聊天数据集用于限定领域下的聊天技术研究[19]。2018年Nikita Moghe等人基于电影知识数据人工标注了电影领域的聊天数据集,用于知识对话技术的研究[**20]。
人机对话技术展望
人机对话经过半个世纪的发展有了长足的进步,不过现在的技术水平还处于初级阶段,将来在以下几个方面需要进一步攻克:
(1)通用语言理解和语言生成技术:目前任务完成类型对话每个任务都有各自的语言理解和语言生成模型,领域迁移困难,通用的语言理解和语言生成技术是解决这一问题的关键。
(2)深度融合知识和常识信息:对话中话语背后蕴含了丰富的知识和常识等语境信息,话语的理解和生成与知识和常识信息密不可分。
(3)**记忆机制:**通过记忆机制记住、提炼并整合历史对话内容,对话时结合记忆信息辅助对话决策模型(Policy Model)进行下一步决策。
(4)多模态的对话技术:人类对话中不仅有语言交互,还有视频、图像等信息的交互,如对话中的手势、说话时的情绪等信息,语言理解时融合多模态信息可以使得机器掌握更完整的语境信息,语言生成时融合多模态信息可以使对话更加生动形象。
五2019年语言与技术竞赛
为了推进人机对话技术进步,百度驱动了知识驱动的对话任务,机器根据知识信息构建的图谱主动与用户进行聊天,让机器具备模拟人类使用自然语言进行信息传递的能力,为此,百度在电影和娱乐人物领域构建了具有14万实体和360万知识的图谱,并基于该图谱众包标注了12万轮对话数据,相比于自动挖掘的对话数据,百度数据对知识的使用更加充分,而且对话中机器角色能够根据给定的对话目标主动引导对话的进程,向用户传递知识信息。
今年,中国计算机协会,中国中文信息学会和百度公司联合举办了2019年语言理解和智能技术竞赛,旨在推动机器语言理解和交互技术发展,知识驱动对话也是该比赛的任务之一,欢迎学术界和工业界的学者,开发者报名参加。
人机对话技术还出于探索阶段,百度希望通过设立新的对话任务探索新的人机对话技术,同时通过开放数据和开源基线系统促进人机对话技术的进步。
总结
- 慢慢的入门人机对话系统,将人机对话系统,全部都将其搞清楚,研究彻底都行啦的理由与打算。
\
















 3638
3638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











