







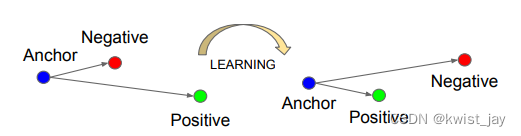
Triplet三元组的基本训练思想是使得类内距离变小,类间距离变大,示意如下:
于是可以构造约束条件:
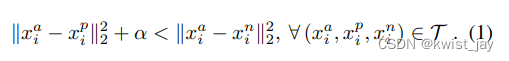
其中:表示anchor样本点,
表示正样本,
表示负样本。于是构造损失函数:
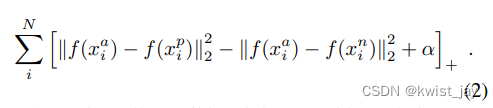
但问题在于如果我们选取满足(1)约束条件的样本,那么必然会使得loss很小,模型收敛速度很慢,相反的,我们选取违反约束条件的样本时,便能大大提升模型的收敛速度。那么我们的目标就变成了:
意思就是找到与anchor之间类内距离最大的点(hard positive)以及类间距离最小的点(hard negative)从而构成三元组进行优化。
解决方案:
在整个训练集上寻找argmax和argmin是困难的。如果找不到,会使训练变得困难,难以收敛,例如错误的打标签和差劲的反映人脸。因此需要采取两种显而易见的方法避免这个问题:
1.离线更新三元组(每隔n步)。采用最近的网络模型的检测点 并 计算数据集的子集的argmin和argmax(局部最优)。
2.在线更新三元组。在mini-batch上 选择不好的正(类内)/负(类间)训练模型。(一个mini-batch可以训练出一个子模型)
本文中采用上述第二种方法。本文中,采用以下方法:
1.使用大量 mini-batch,从而得到几千个不好的训练模型。
2.计算mini-batch上的argmin和argmax。
总结:以上所有过程博主概括为:为了快速收敛模型-->需要找到训练的不好的mini-batch上的差模型(负样本)-->从而找到 不满足约束条件/使损失增大 的三元组
在本文中,训练集的每个mini-batch包含:
1. 每个身份的40个人脸
2. 随机放一些负样本人脸
实际采用方法:
1.采用在线的方式 (作者说,在线+不在线方法结果不确定)
2.在mini-batch中挑选所有的anchor positive 图像对 (因为实际操作时,发现这样训练更稳定)
3.依然选择最为困难的anchor negative图像对 (可以提前发现不好的局部最小值)
特殊情况:
选择最为困难的负样本,在实际当中,容易导致在训练中很快地陷入局部最优,或者说整个学习崩溃f(x)=0 //我在CNN学习的时候也经常会遇到这个问题,不过我的是f(x)=1。为了避免这个问题,在选择negative的时候,使其满足式(3):
左边:Positive pair的欧式距离右边:negative pair的欧式距离。把这一个约束叫作semi-hard (半序关系)。因为虽然这些negative pair的欧式距离 远小于 Positive pair的欧式距离,但是 negative pair的欧式距离的平方 接近于Positive pair的欧式距离的平方。
参考文章:
https://www.cnblogs.com/lijie-blog/p/10168073.html
FaceNet: A Unified Embedding for Face Recognition and Clustering















 1272
1272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









