








基于spark1.4.1的sparkR的实例操作,sparkR的操作基本语法与R一致,其中添加了rJava、rhdfs、SparkR的依赖库的支持。
1、集群启动SparkR
输入 bdcmagicR
关于启动脚本的封装参看 : http://blog.csdn.net/bdchome/article/details/48092499
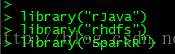
2、加载依赖库
- library("rJava")
- library("rhdfs")
- library("SparkR")
3、sparkR操作实例
1) 、基础的R语句
- x <- 0
- for(i in 1:100){
- x <- x+i
- }
- x

2)、sparkR操作hdfs上的文件
上传文件,并查看
- hdfs.init()
- hdfs.put("/opt/bin/jar/people.json","hdfs://nameservice1/tmp/resources/people2.json")
- hdfs.cat("hdfs://nameservice1/tmp/resources/people.json")

sparkR操作该文件,找出年龄大于30的人
- sqlContext <- sparkRSQL.init(sc)
- path <- file.path("hdfs://nameservice1/tmp/resources/people2.json")
- peopleDF <- jsonFile(sqlContext, path)
- printSchema(peopleDF)
- registerTempTable(peopleDF, "people")
- teenagers <- sql(sqlContext, "SELECT name FROM people WHERE age > 30")
- teenagersLocalDF <- collect(teenagers)
- print(teenagersLocalDF)
- sparkR.stop()

最后需要关闭 sparkR.stop()
3)、通过sparkR操作spark-sql以hive的表为对象
- hqlContext <- sparkRHive.init(sc)
- showDF(sql(hqlContext, "show databases"))
- showDF(sql(hqlContext, "select * from ods.tracklog where day='20150815' limit 15"))
- result <- sql(hqlContext, "select count(*) from ods.tracklog where day='20150815' limit 15")
- resultDF <- collect(result)
- print(resultDF)
- sparkR.stop()
返回结果:show databases;

查询返回结果:select * from ods.tracklog where day='20150815' limit 15

做为变量的返回:

最后需要关闭 sparkR.stop()

总结: sparkR可以完成R基础的操作,以hdfs上的操作,spark-sql的查询等。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









