






20220822
spark-sql 命令行是个很好的工具,要好好使用
https://blog.csdn.net/Allwordhuier/article/details/119509999
进入spark-shell
通过 命令 spark-shell或者pyspark命令进入,可以对hdfs 增删改查很方便解决
20220721
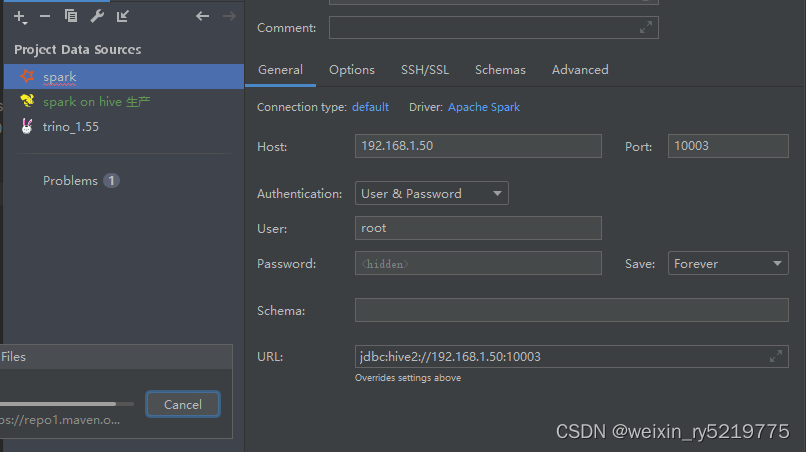
pycharm远程连接spark
20220523
pysparkpy4j.Py4JException:方法和([classjava.lang.Integer]))不存在
https://www.5axxw.com/questions/content/gmtwrc
20220519
https://blog.csdn.net/zhangxianx1an/article/details/80609514
ntile函数 排序分成几部分,对前多少分之几进行分析
Caused by: java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(
https://blog.csdn.net/xiangqianzou_liu/article/details/80409237
分析步骤:
1、系统环境变量配置HADOOP_HOME ,并且添加进path 变量里;
2、HADOOP_HOME\bin 里是否有hadoop.dll 和 winutils.exe 这两个文件
3、C: windows\System32 里是否有hadoop.dll 文件 ,记得重启电脑噢!!!
20220518
https://newbedev.com/since-spark-2-3-the-queries-from-raw-json-csv-files-are-disallowed-when-the-referenced-columns-only-include-the-internal-corrupt-record-column
一个jason单位整体放在一行
Since Spark 2.3, the queries from raw JSON/CSV files are disallowed when the referenced columns only include the internal corrupt record column
https://sparkbyexamples.com/pyspark/pyspark-py4j-protocol-py4jerror-org-apache-spark-api-python-pythonutils-jvm/
import findspark
findspark.init(r"D:\Python37\Lib\site-packages\pyspark")
用python自带的pyspark
from pyspark.sql import SparkSession
20220415
uo.coalesce(1).write.mode("overwrite").option("header", True).csv(uo_output)
od.coalesce(1).write.mode("overwrite").option("header", True).csv(od_output)
yarn下写到本地一个文件的方式
https://blog.csdn.net/weixin_39966065/article/details/89523609
transform,action 算子的区别
20220414
Py4J is a Java library that is integrated within PySpark and allows python to dynamically interface with JVM objects
schema_od = StructType() \
.add("user_id", IntegerType(), True) \
.add("order_id", IntegerType(), True) \
.add("order_day", StringType(), True) \
.add("goods_id", IntegerType(), True) \
.add("category_second_id", IntegerType(), True)
od_all = spark_big.read.csv("hdfs://k8s04:8020/data/od/*",inferSchema=True,schema=schema_od)
要同时更改很多列名的时候
java.lang.IllegalArgumentException: Executor memory 6 must be at least 471859200. Please increase executor memory using the --executor-memory option or spark.executor.memory in Spark configuration.
不小心误写小了
starting org.apache.spark.deploy.history.HistoryServer, logging to /opt/module/spark-3.1.2-bin-hadoop3.2/logs/spark-root-org.apache.spark.deploy.history.HistoryServer-1-k8s04.out
failed to launch: nice -n 0 /opt/module/spark-3.1.2-bin-hadoop3.2/bin/spark-class org.apache.spark.deploy.history.HistoryServer
删除spark /logs下的所有文件,另外spark-conf 下
spark-default.conf 或者 spark-env.sh 里面 log服务器
的hdfs路径配置错误
20220409
Detected yarn cluster mode, but isn‘t running on a cluster. Deployment to YARN is not supported 解决办法
https://blog.csdn.net/qq_40243573/article/details/114890806
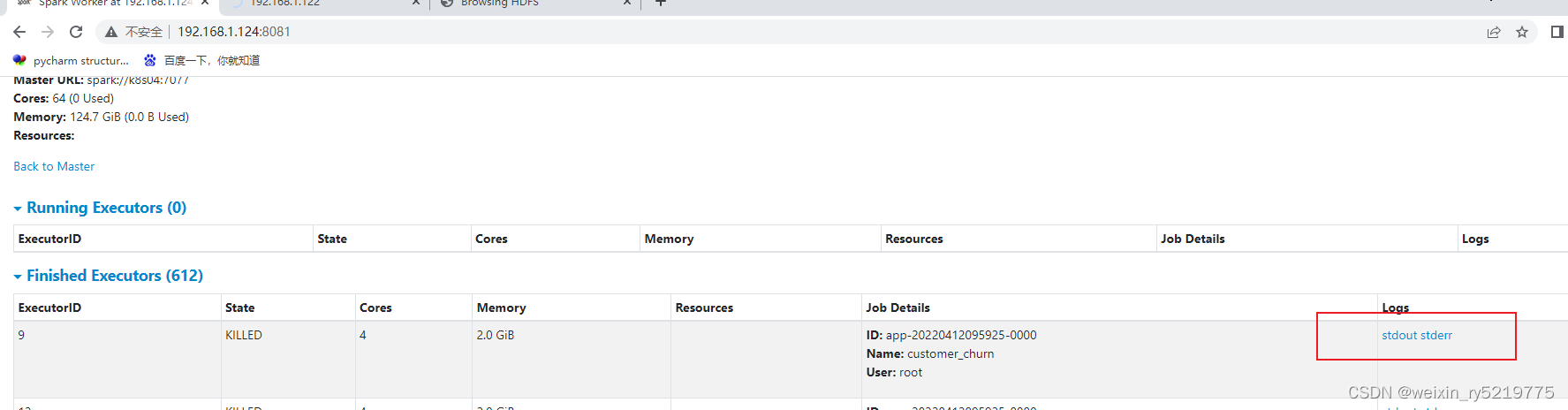
http://192.168.1.124:8081/
http://192.168.1.124:4041/
查问题主要从这里查
https://home.apache.org/~pwendell/spark-releases/spark-2.2.0-rc2-docs/configuration.html
spark参数配置
https://zhuanlan.zhihu.com/p/343638801
sparkOOM问题
createDataFrame
数据量很大的情况下,超千万条 createDataFrame会很慢
可以先保存到本地csv,再直接读取为sparkDataframe这样会更快
行不通,spark不能直接从本地读取
两种解决方法:1.可以先在python代码里面上传文件到hdfs
2. 先把普通的dataframe转换为list 然后用 parallelize(list)
转换为rdd,再通过rdd转换为dataframe会很快 代码如下
不过这两种方法占用非常占用内存,很难成功,可以通过先hdfs -put到hdfs再重新读取就好了
od_col = od.columns.tolist()
od_all = od.values.tolist()
sc = spark_big.sparkContext
od_all = sc.parallelize(od_all)
# od.to_csv(PATH + 'temp/temp_od.txt',index=False)
# od_all = spark_big.read.text("file://"+PATH + 'temp/temp_od.txt')
# od_all.createOrReplaceTempView('od_all')
# od_all = spark_big.sql("select * from od_all")
# od_all = od_all.rdd.map(lambda x:x.split(","))
od_all = spark_big.createDataFrame(od_all,schema=od_col)
https://bryancutler.github.io/createDataFrame/
通过arrow加速
https://stackoverflow.com/questions/21138751/spark-java-lang-outofmemoryerror-java-heap-space
Spark java.lang.OutOfMemoryError: Java heap space
20220406
.config(“spark.dynamicAllocation.enabled”, “true”)
spark.catalog.dropTempView()
删除临时表
spark提高效率
WARN TaskSetManager: Lost task 238.1 in stage 3.0 (TID 1345) (192.168.1.122 executor 134): TaskKilled (another attempt succeeded)
不用管
1、报错 ERROR TaskSchedulerImpl: Lost executor 3 on 172.16.0.24: Unable to create executor due to Unable to register with external shuffle server due to : Failed to connect to /172.16.0.24:7337
https://blog.csdn.net/weixin_42034217/article/details/103581573
py4j.protocol.Py4JJavaError: An error occurred while calling o153.collectToPython.
: org.apache.spark.SparkException: Job aborted due to stage failure: Total size of serialized results of 299 tasks (2.1 GiB) is bigger than spark.driver.maxResultSize (2.0 GiB)
调到maxResultSize?
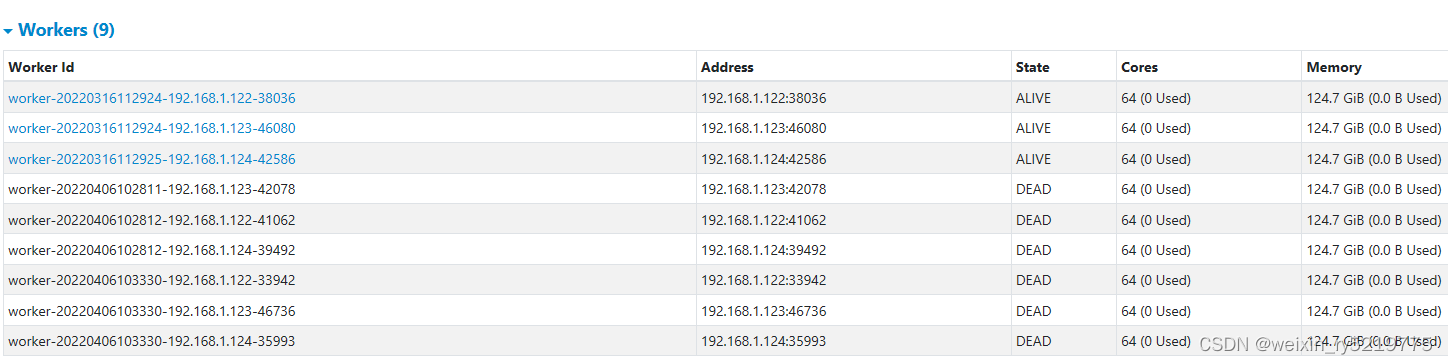
Spark集群无法停止:“no org.apache.spark.deploy.master.Master to stop”
https://blog.csdn.net/u010416101/article/details/80137353

删除临时表
https://blog.csdn.net/liuxinghao/article/details/77934725
java.lang.OutOfMemoryError:GC overhead limit exceeded
20220316
spark和多进程不能同时使用
https://blog.csdn.net/qq_40999403/article/details/101759558
spark写入mysql
https://blog.csdn.net/qq_42246689/article/details/86062910
spark调整日志输出等级
https://mvnrepository.com/artifact/org.apache.spark/spark-core
spark和scala对应关系
20220315
py4j.protocol.Py4JJavaError: An error occurred while calling z:org.apache.spark.api.python.PythonRDD.readRDDFromFile.
: java.lang.ExceptionInInitializerError
Caused by: com.fasterxml.jackson.databind.JsonMappingException: Scala module 2.10.0 requires Jackson Databind version >= 2.10.0 and < 2.11.0
20220314
py4j.protocol.Py4JJavaError: An error occurred while calling z:org.apache.spark.api.python.PythonRDD
https://blog.csdn.net/u011250186/article/details/112240484
java.lang.NoClassDefFoundError: org/apache/spark/sql/connector/catalog/SupportsMetadataColumns
alluxio-client版本不一致造成的
https://blog.csdn.net/MrLevo520/article/details/86738109
spark-submit 提交python外部依赖包
20220311
WARN TaskSetManager: Lost task 173.1 in stage 44.0 (TID 3012, 192.168.1.122, executor 16): TaskKilled (another attempt succeeded)
可以忽略
20220310
程序跑着跑着自动退出又没有报错很可能是资源不够
NioEventLoop: Selector.select() returned prematurely 512 times in a row; rebuilding Selector io.netty.channel.nio.SelectedSelectionKeySetSelector@115adbc6.
不是报错,意思netty遇见了linux的空轮询问题,正在重建选择器进行事件监听
空轮询是linux问题
org.apache.spark.shuffle.MetadataFetchFailedException:Missing an output location for shuffle 5
解决方案:executor分配的内存不足,分配更多内存后解决问题
https://blog.csdn.net/u014236468/article/details/78663478
ERROR TransportRequestHandler
Could not find CoarseGrainedScheduler
https://blog.csdn.net/u013709270/article/details/78879869
org.apache.spark.shuffle.FetchFailedException: Failed to connect to xxx.hadoop.com:7337
很可能是端口写错了
https://blog.csdn.net/wuzhilon88/article/details/80198734
Connection reset by peer spark
有可能是英文sc参数配置产生的问题,具体问题还需深入分析
ERROR TaskSchedulerImpl: Lost executor 1 on 1xx.xx.xxx.x: Remote RPC client disassociated. Likely du
ERROR TaskSchedulerImpl: Lost executor 1 on xx.xx.xx.xx: Remote RPC client disassociated. Likely due to containers exceeding thresholds, or network issues. Check driver logs for WARN messages.
是SPARK_DRIVER_MEMORY或SPARK_EXECUTOR_MEMORY不足,在spark-env.sh中增大一些就OK
最可能是把executor_memory加大
https://blog.csdn.net/DayOneMore/article/details/114882871
20220308
ERROR SparkUI: Failed to bind SparkUI
有可能是内存不够了sparksumit太多了
重新连接shell
spark Stage 0 contains a task of very large size (228 KB). The maximum recommended task size is 100 KB.
https://zhuanlan.zhihu.com/p/149526790
Can not merge type <class 'pyspark.sql.types.StringType'> and <class 'pyspar
某列存在空值
Initial job has not accepted any resources; check your cluster UI to ensure that workers are registe
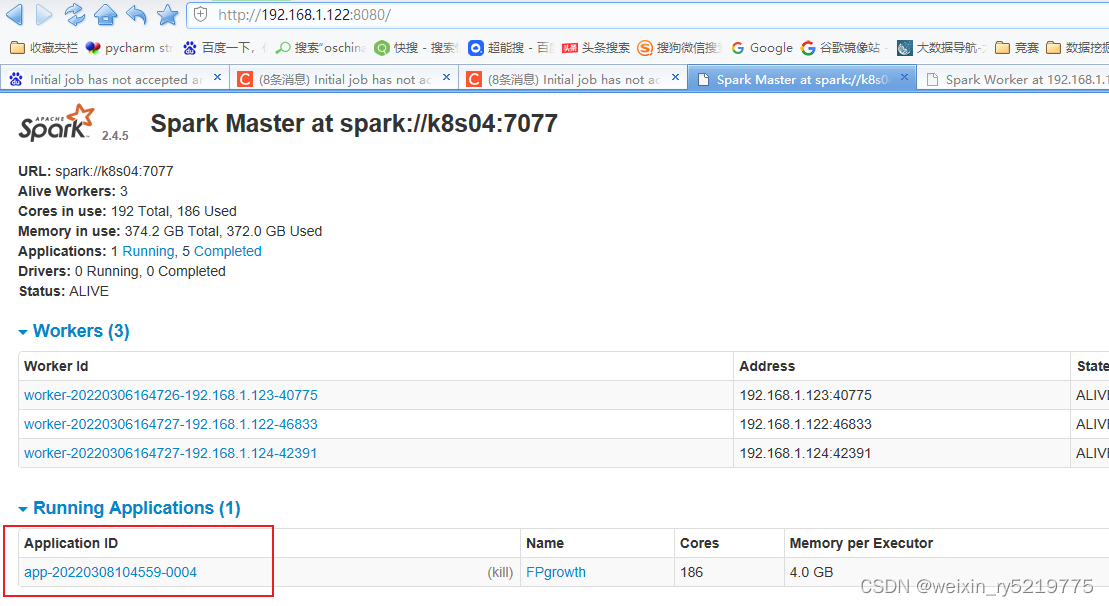
8080端口才能看到具体运行的程序
查看正在跑的程序,程序太多kill一些
直接在这里kill释放资源不用重新登陆shell同样可以去除sparksubmit
进程
20220304
https://blog.csdn.net/kyle1314608/article/details/120013044
pyspark小结重点
Initial job has not accepted any resources; check your cluster UI to ensure that workers are registe
https://blog.csdn.net/struggling_rong/article/details/81269635
20220214
org.apache.spark.SparkException: Exception thrown in awaitResult:
spark服务没启动?
20211231
2021-06-25-Spark-39(ERROR TransportResponseHandler: Still have 1 requests outstanding when conne...
https://www.jianshu.com/p/00dbcacb2e07
20211230
spark的输入和输出都基于hadoop的hdfs上面hdfs不别 "."的当前目录 直接从根目录开始
/data
http://blog.chinaunix.net/uid-29454152-id-5645182.html
关闭和修改日志
关闭屏幕输出
https://mp.weixin.qq.com/s/mo2hYHT13SSMp8iSrsG5xg
https://www.cnblogs.com/lenmom/p/12022038.html
https://blog.csdn.net/kyle1314608/article/details/122234853
上面两篇参考起来一起看
Spark-submit 参数调优完整攻略
SPARK_WORKER_WEBUI_PORT
工作者Web UI的端口(默认值:8081)以及 8080 ,4041
Spark Application UI: http://localhost:4040/
Resource Manager: http://localhost:9870
Spark JobTracker: http://localhost:8088/
Node Specific Info: http://localhost:8042/

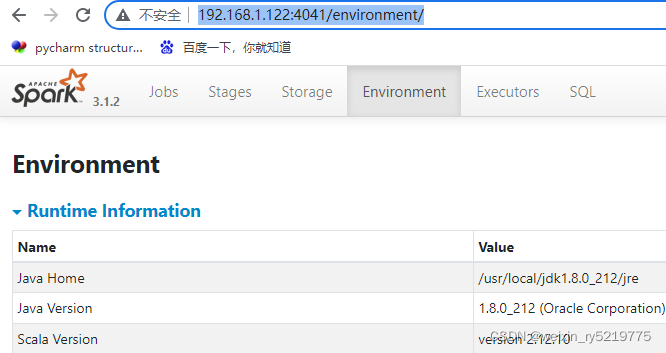
http://192.168.1.122:4041/
4041端口详细信息
配置参数是对应的?
https://blog.csdn.net/weixin_42712704/article/details/101556912
spark WARN scheduler.TaskSetManager: Lost task报错
https://blog.csdn.net/u011564172/article/details/69703662
Spark 任务调度之启动CoarseGrainedExecutorBackend
https://mp.weixin.qq.com/s/sC7_cvzfEbS3Gm2q1-2ECQ
Spark常见的脚本及参数详解和端口
https://blog.csdn.net/LastYHM/article/details/108715939
sparksubmit进程无法杀死
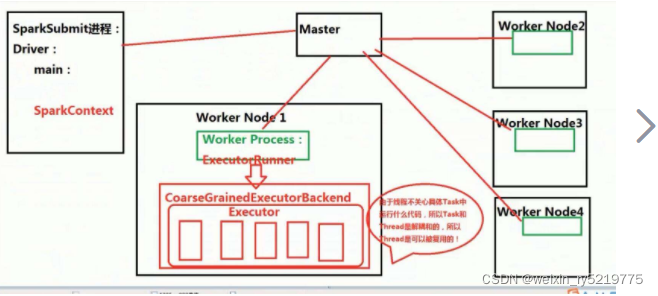
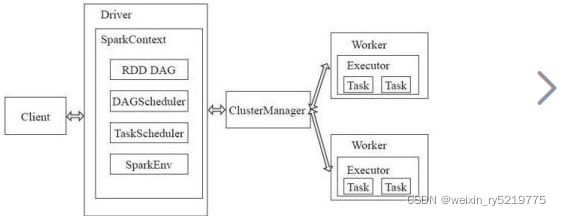
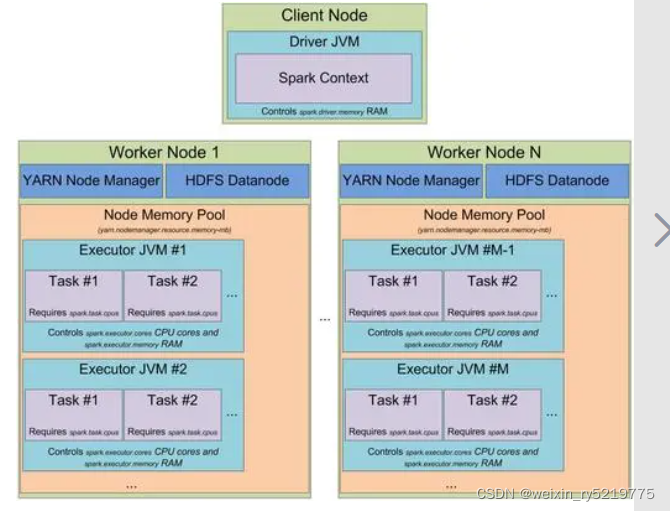
https://blog.csdn.net/weixin_30667301/article/details/99494592
spark进程关系
20211229
http://192.168.1.122:8080/#completed-app
spark控制台端口号
https://blog.csdn.net/chenyuangege/article/details/51513569
先启动hadoop再启动spark 只需要在master上启动就够了
启动关闭hadoop集群和spark集群 重点
bin/spark-submit \
--master spark://hadoop01:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
/tmp/test.py
pyspark集群提交任务
spark-submit为spark\bin里面的spark-submit
可以建立软连接
hadoop01是主机名称
https://www.cnblogs.com/luckyboylch/p/12567710.html
linux安装pyspark重点
20220316
两种解决ERROR: Attempting to operate on hdfs namenode as root的方法
https://blog.csdn.net/weixin_49736959/article/details/108897129
记Hadoop3.1.2安装排错之ERROR: Cannot set priority of datanode process
是因为上一个问题解决之后没有分发到其他worker节点
https://blog.csdn.net/qq_43591235/article/details/120173435
hadoop3的安装配置 1
https://blog.csdn.net/qq_15349687/article/details/82748074
https://www.cnblogs.com/zhangyongli2011/p/10572152.html
上面两点主要关注hadoop的配置 2
1和2结合起来,hadoop-env只需配置java-home
可以参考大数据的配置文件
https://blog.csdn.net/a532672728/article/details/72358422
spark集群搭建安装重点
https://www.cnblogs.com/startnow/p/13697739.html
pyspark提交集群任务
https://blog.csdn.net/ruth13156402807/article/details/118962105
pyspark更好python版本
pyspark helloword test
from pyspark import SparkConf
from pyspark.sql import SparkSession
print("==========app start=========")
spark = SparkSession.builder.enableHiveSupport().getOrCreate()
df = spark.sql('show databases')
df.show()
print("==========app stop=========")
spark.stop()















 1899
1899











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









