







1.Ref
-
https://arxiv.org/pdf/2303.01469
-
https://zeqiang-lai.github.io/blog/posts/ai/consistency_model/
-
https://kevinng77.github.io/posts/notes/articles/%E7%AC%94%E8%AE%B0speed_sd.html#cm-lcm-lcm-lora
-
https://wrong.wang/blog/20231111-consistency-is-all-you-need/
-
https://blog.csdn.net/weixin_54338498/article/details/130174582
2. Consistency Models(CM)
A. DM multi-step denoising
特别消耗计算资源,所以模型的加速需求是比较强烈的。
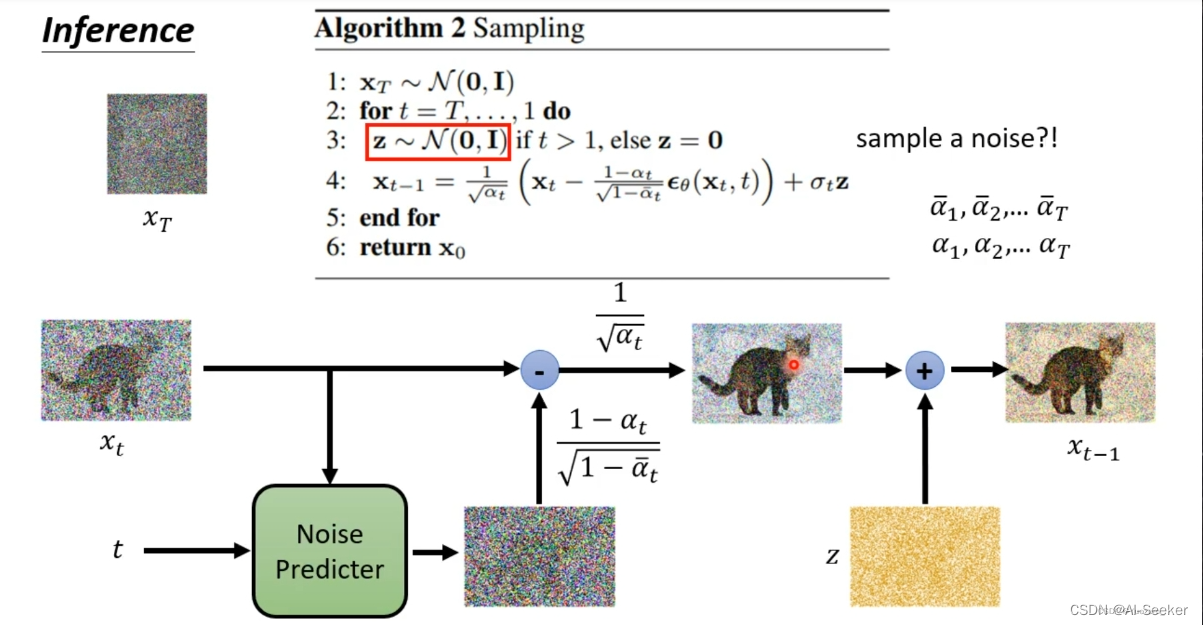
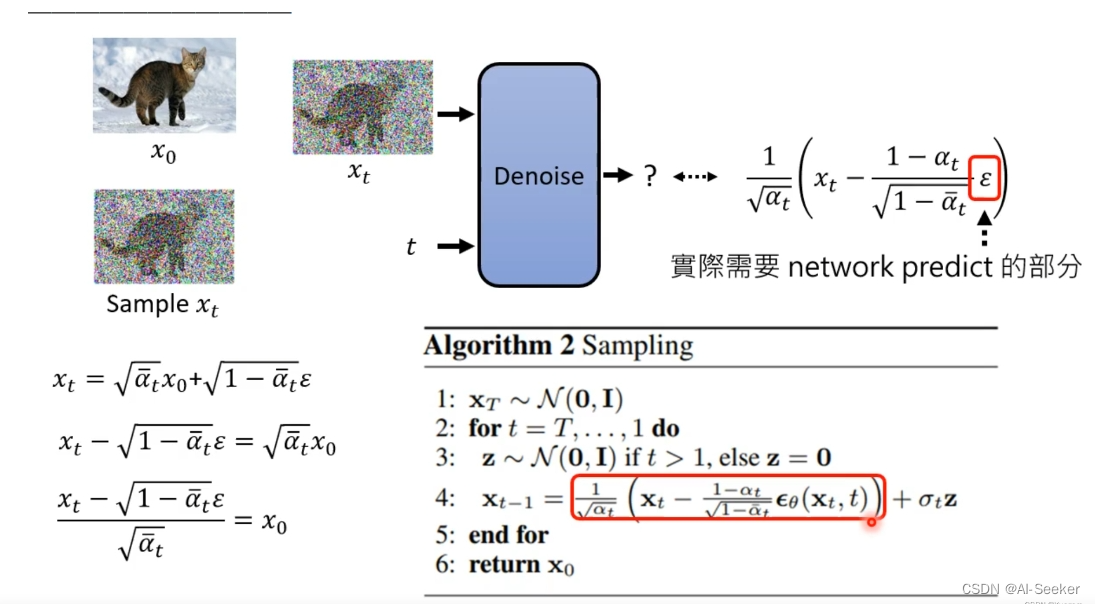
B. DM 优化方案
-
剪枝策略:通用剪枝策略 diff-pruning,在多步 model 采用统一的剪枝策略。
-
Handcraft Arch
-
Block-wise pruning:DeepCach
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 576
576

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









