







前言:
风险控制是挖掘中最为常见的应用,属于监督学习的“分类器”使用案例。我们通过以往历史数据判断用户违约的概率。本文使用了Logistic Regression 方法完成案例。
注:
根据CDA课程自己总结的学习笔记。使用的是ipython,数据及代码都已上传至个人网盘http://pan.baidu.com/s/1ntR2tmD。
如果有任何问题或错误欢迎各位指正 liedward@qq.com谢谢。
风控模型开发流程
· 数据抽取
· 数据探索
· 建模数据准备
· 变量选择
· 模型开发与验证
· 模型部署
· 模型监督
加载包:
importos
importsys
importstring
importpymysql
importnumpyasnp
importpandasaspd
importstatsmodels.apiassm
importmatplotlib.pyplotasplt
%matplotlibinline
importseabornassns
importsklearn.cross_validationascross_validation
importsklearn.treeastree
importsklearn.ensembleasensemble
importsklearn.linear_modelaslinear_model
importsklearn.svmassvm
importsklearn.feature_selectionasfeature_selection
importsklearn.metricsasmetrics
- 数据抽取
model_data = pd.read_csv("credit_develop.csv")
model_data.head()#查看数据格式
读取数据后查看大致数据的情况,主要看每个字段的格式属性。比如Branch_of_Bank等字段为分类变量,后续需要进行虚拟化变量处理。

- 数据探索
数据探索是建模人员了解特征时使用的方法,可以通过数据表或是图形的方式了解整体数据。
model_data.describe().T
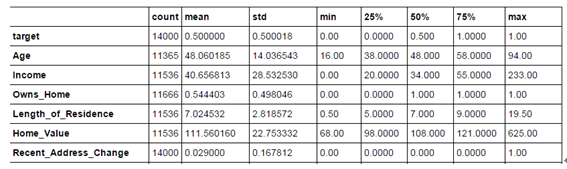
查看数据的分布。
data = model_data["Credit_Score"].dropna() # 去除缺失值sns . distplot ( data )
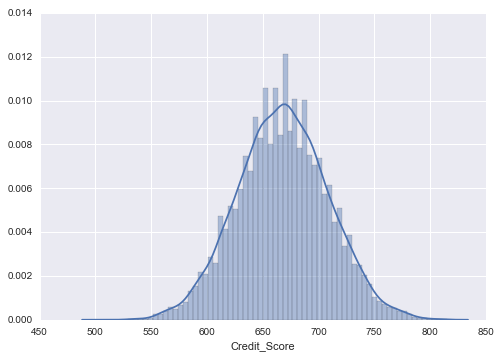
查看信用分数的分布情况
plt . boxplot ( data )
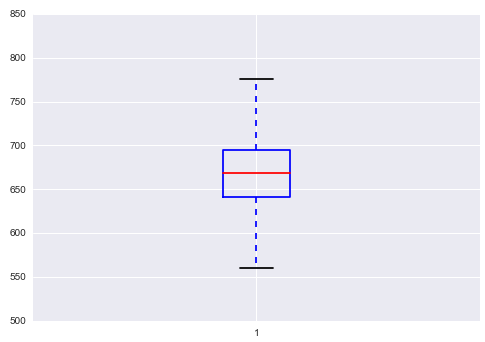
利用箱线图查看数据离散情况
model_data=model_data.drop_duplicates()#去除重复项
填充缺失值
model_data = model_data.fillna(model_data.mean()) #用均值来填充
变量相似度分析,变量聚类
simpler = np .random .randint ( 0 , len (model_data ),size = 50 )sns.clustermap(model_data.iloc[simpler,3:].T,col_cluster=False,row_cluster=True)

- 生成模型训练/测试数据集
将分类变量变为虚拟变量
Area_Classification_dummy = pd.get_dummies(model_data["Area_Classification"],prefix="Area_Class")model_data .join (Area_Classification_dummy )
model_data.join(model_data[="Branch"))
· 分成目标变量和应变量
target = model_data["target"]
pd.crosstab(target,"target")
data = model_data.ix[ :,'Age':]
· 分成训练集和测试集,比例为6:4
train_data, test_data, train_target, test_target = cross_validation.train_test_split(data, target, test_size=0.4, random_state=0)
- 筛选变量
因为使用的是普通的罗吉斯回归,所以变量筛选变得尤为重要。如果筛选不当会产生过拟合或是欠拟合现象。(当然可以使用一些更高级的算法完成筛选功能)首先使用最原始的方法线性相关系数。
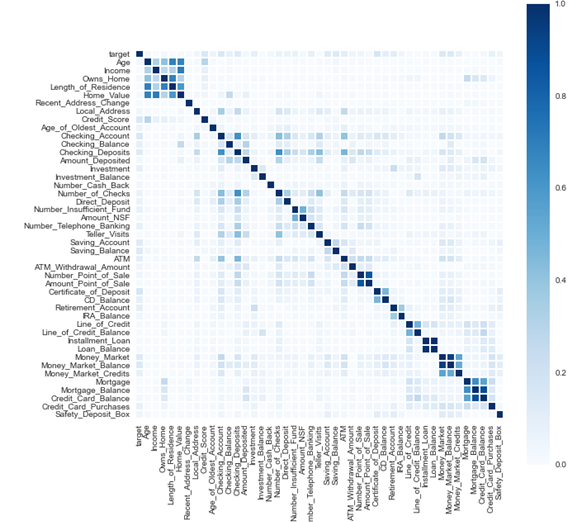
corr_matrix = model_data.corr(method='pearson')
corr_matrix = corr_matrix.abs()
sns.set(rc={ "figure.figsize": (10, 10)})
sns.heatmap(corr_matrix,square=True,cmap="Blues")
corr = model_data.corr(method='pearson').ix["target"].abs()
corr.sort(ascending=False)corr .plot (kind = "bar" ,title = "corr" ,figsize =[ 12 ,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2038
2038











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









