







本文主要使用inception v3的模型,再后面接一个softmax,做一个分类器。具体代码都是参照tf github。
整体步骤:
步骤一:数据准备,准备自己要分类的图片训练样本。
步骤二:retrain.py 程序,用于下载inception v3模型及训练后面的分类器(可见最后的代码)
步骤三:训练 命令
步骤四:预测 prediction.py 程序,用于调用新生成的模型预测新数据的结果。
具体内容:
步骤一:数据准备 ,可以自己收集照片。这边提供一个图片分类的网站
http:///www.robots.ox.ac.uk/~vgg/data/
要求:放在data/train/ 目录下
步骤二:略,见下方代码2。
步骤三:训练命令
#!/bin/sh
python retrain.py --bottleneck_dir bottleneck --how_many_training_steps 200 --model_dir model/ --output_graph output_graph.pb --output_labels output_labels.txt --image_dir data/train/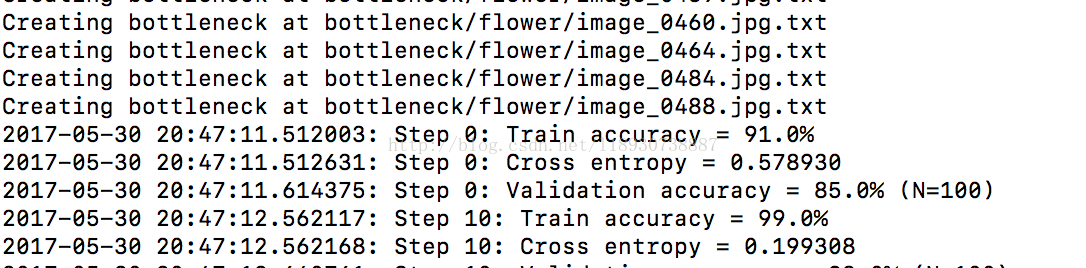
结果如上:
步骤四:训练代码
我目前直接用ipython 演示:
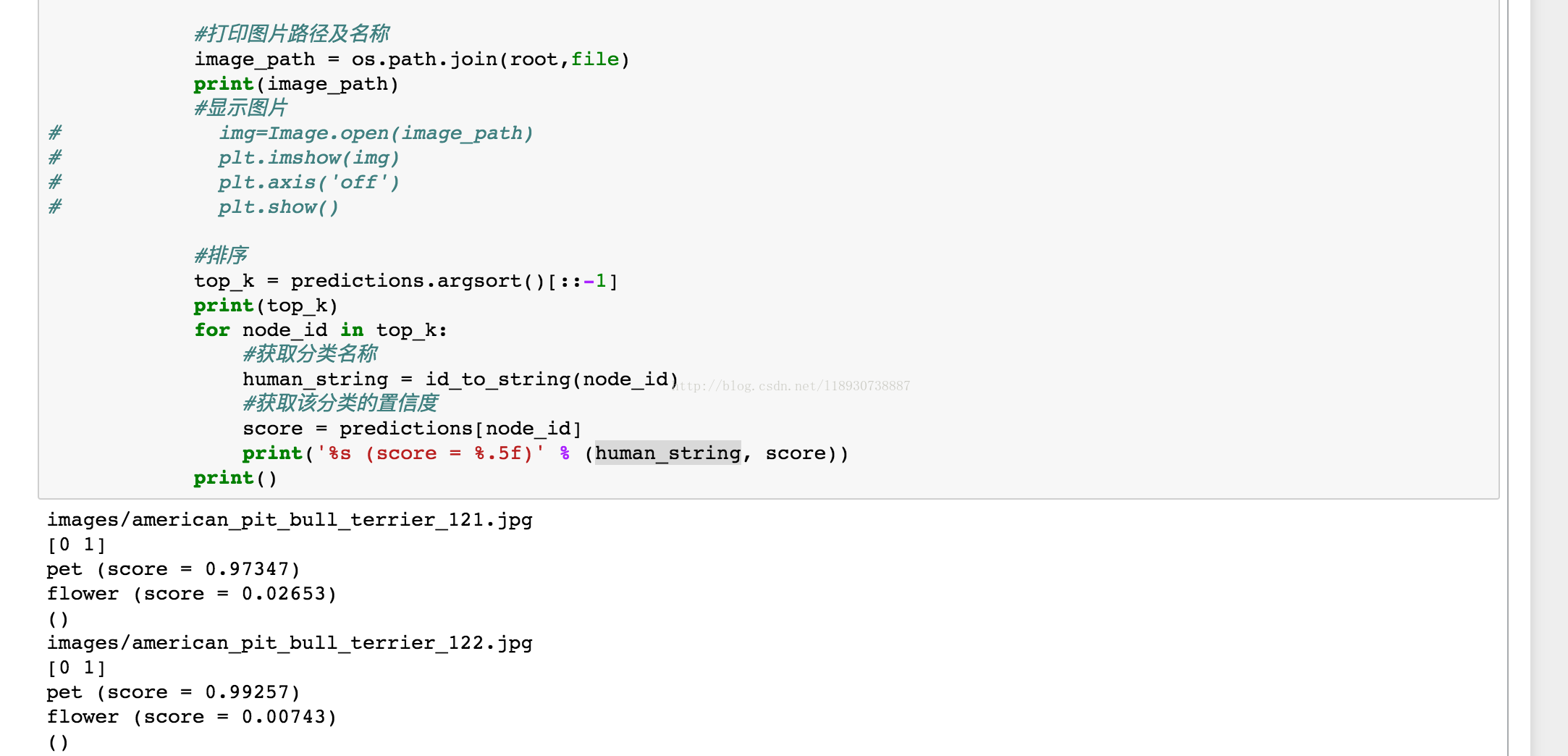
可以看到结果,我是分了宠物和花2种类别。目前效果还是很好的!
放2个代码
第一个:预测代码
# coding: utf-8
import tensorflow as tf
import os
import numpy as np
import re
#from PIL import Image
import matplotlib.pyplot as plt
lines = tf.gfile.GFile('output_labels.txt').readlines()
uid_to_human = {}
#一行一行读取数据
for uid,line in enumerate(lines) :
#去掉换行符
line=line.strip('\n')
uid_to_human[uid] = line
def id_to_string(node_id):
if node_id not in uid_to_human:
return ''
return uid_to_human[node_id]
with tf.gfile.FastGFile('output_graph.pb', 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
tf.import_graph_def(graph_def, name='')
with tf.Session() as sess:
softmax_tensor = sess.graph.get_tensor_by_name('final_result:0')
#遍历目录
for root,dirs,files in os.walk('images/'):
for file in files:
#载入图片
image_data = tf.gfile.FastGFile(os.path.join(root,file), 'rb').read()
predictions = sess.run(softmax_tensor,{'DecodeJpeg/contents:0': image_data})#图片格式是jpg格式
predictions = np.squeeze(predictions)#把结果转为1维数据
#打印图片路径及名称
image_path = os.path.join(root,file)
print(image_path)
#显示图片
# img=Image.open(image_path)
# plt.imshow(img)
# plt.axis('off')
# plt.show()
#排序
top_k = predictions.argsort()[::-1]
print(top_k)
for node_id in top_k:
#获取分类名称
human_string = id_to_string(node_id)
#获取该分类的置信度
score = predictions[node_id]
print('%s (score = %.5f)' % (human_string, score))
print()
第二个:训练代码(可以到tensorflow git 上下载到 examples/retrain 下找到)
# Copyright 2015 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Simple transfer learning with an Inception v3 architecture model.
With support for TensorBoard.
This example shows how to take a Inception v3 architecture model trained on
ImageNet images, and train a new top layer that can recognize other classes of
images.
The top layer receives as input a 2048-dimensional vector for each image. We
train a softmax layer on top of this representation. Assuming the softmax layer
contains N labels, this corresponds to learning N + 2048*N model parameters
corresponding to the learned biases and weights.
Here's an example, which assumes you have a folder containing class-named
subfolders, each full of images for each label. The example folder flower_photos
should have a structure like this:
~/flower_photos/daisy/photo1.jpg
~/flower_photos/daisy/photo2.jpg
...
~/flower_photos/rose/anotherphoto77.jpg
...
~/flower_photos/sunflower/somepicture.jpg
The subfolder names are important, since they define what label is applied to
each image, but the filenames themselves don't matter. Once your images are
prepared, you can run the training with a command like this:
```bash
bazel build tensorflow/examples/image_retraining:retrain && \
bazel-bin/tensorflow/examples/image_retraining/retrain \
--image_dir ~/flower_photos
```
Or, if you have a pip installation of tensorflow, `retrain.py` can be run
without bazel:
```bash
python tensorflow/examples/image_retraining/retrain.py \
--image_dir ~/flower_photos
```
You can replace the image_dir argument with any folder containing subfolders of
images. The label for each image is taken from the name of the subfolder it's
in.
This produces a new model file that can be loaded and run by any TensorFlow
program, for example the label_image sample code.
To use with TensorBoard:
By default, this script will log summaries to /tmp/retrain_logs directory
Visualize the summaries with this command:
tensorboard --logdir /tmp/retrain_logs
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import argparse
from datetime import datetime
import hashlib
import os.path
import random
import re
import struct
import sys
import tarfile
import numpy as np
from six.moves import urllib
import tensorflow as tf
from tensorflow.python.framework import graph_util
from tensorflow.python.framework import tensor_shape
from tensorflow.python.platform import gfile
from tensorflow.python.util import compat
FLAGS = None
# These are all parameters that are tied to the particular model architecture
# we're using for Inception v3. These include things like tensor names and their
# sizes. If you want to adapt this script to work with another model, you will
# need to update these to reflect the values in the network you're using.
# pylint: disable=line-too-long
DATA_URL = 'http://download.tensorflow.org/models/image/imagenet/inception-2015-12-05.tgz'
# pylint: enable=line-too-long
BOTTLENECK_TENSOR_NAME = 'pool_3/_reshape:0'
BOTTLENECK_TENSOR_SIZE = 2048
MODEL_INPUT_WIDTH = 299
MODEL_INPUT_HEIGHT = 299
MODEL_INPUT_DEPTH = 3
JPEG_DATA_TENSOR_NAME = 'DecodeJpeg/contents:0'
RESIZED_INPUT_TENSOR_NAME = 'ResizeBilinear:0'
MAX_NUM_IMAGES_PER_CLASS = 2 ** 27 - 1 # ~134M
def create_image_lists(image_dir, testing_percentage, validation_percentage):
"""Builds a list of training images from the file system.
Analyzes the sub folders in the image directory, splits them into stable
training, testing, and validation sets, and returns a data structure
describing the lists of images for each label and their paths.
Args:
image_dir: String path to a folder containing subfolders of images.
testing_percentage: Integer percentage of the images to reserve for tests.
validation_percentage: Integer percentage of images reserved for validation.
Returns:
A dictionary containing an entry for each label subfolder, with images split
into training, testing, and validation sets within each label.
"""
if not gfile.Exists(image_dir):
print("Image directory '" + image_dir + "' not found.")
return None
result = {}
sub_dirs = [x[0] for x in gfile.Walk(image_dir)]
# The root directory comes first, so skip it.
is_root_dir = True
for sub_dir in sub_dirs:
if is_root_dir:
is_root_dir = False
continue
extensions = ['jpg', 'jpeg', 'JPG', 'JPEG']
file_list = []
dir_name = os.path.basename(sub_dir)
if dir_name == image_dir:
continue
print("Looking for images in '" + dir_name + "'")
for extension in extensions:
file_glob = os.path.join(image_dir, dir_name, '*.' + extension)
file_list.extend(gfile.Glob(file_glob))
if not file_list:
print('No files found')
continue
if len(file_list) < 20:
print('WARNING: Folder has less than 20 images, which may cause issues.')
elif len(file_list) > MAX_NUM_IMAGES_PER_CLASS:
print('WARNING: Folder {} has more than {} images. Some images will '
'never be selected.'.format(dir_name, MAX_NUM_IMAGES_PER_CLASS))
label_name = re.sub(r'[^a-z0-9]+', ' ', dir_name.lower())
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 930
930

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









